
Disney Research опубликовали нейросетевой алгоритм, для автоматической замены лиц на изображениях и видео. Это первый метод, который способен рендерить фотореалистичные и консистентные по времени изображения в высоком разрешении. Модель обучается без учителя.
Исследователи выяснили, что расширение архитектуры и обучающей выборки за пределы двух человек повышает достоверность генерируемых лиц. Когда сгенерированное выражение переносится на целевое лицо, используется метод блендинга, позволяющий сохранить контраст и освещение на изображении. Чтобы добиться временной стабильности, когда модель используется на видеозаписях, исследователи внедрили стратегию уточнения предсказаний в алгоритм стабилизации ключевых точек лица. Это позволяет модели обрабатывать видеозаписи в высоком разрешении.
Что внутри модели
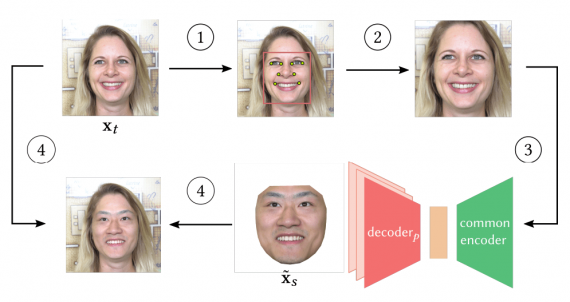
Процесс замены лица на целевом изображении состоит из четырех шагов:
- На первом и втором этапе целевое изображение предобрабатывается: вырезается часть с лицом и лицо нормализуется;
- На третьем этапе предобработанное изображение поступает на вход энкодеру и декодирует соответствующим декодером;
- Четвертый этап необходим для блендинга входного лица с целевым изображением
Модель прогрессивно обучается генерировать более реалистичные целевые изображения с входным лицом. Нейросеть обучали на датасете с видеозаписями разрешением в 4K, который собрали исследователи.
Оценка работы модели
Исследователи сравнивают свою модель с тремя альтернативными архитектурами, которые считаются state-of-the-art в задаче подмены лица на изображении. Альтернативные модели включают в себя Nirkin et al., DeepFakes и DeepFaceLab. Ниже видно, что предложенная нейросеть генерирует более реалистичные изображения с меньшим количеством артефактов в сравнении с аналогами.

