Исследователи из Virginia Tech и Facebook разработали нейросеть, которая предсказывает глубину кадров видеозаписи. Одним из применений является использование предсказаний нейросети для добавления спецэффектов к видеозаписи. По результатам экспериментов, предложенный подход предсказывает глубину сцены на видеозаписи более точно, чем state-of-the-art методы. При этом предсказания нейросети более стабильны.
Ограничения текущих подходов
Стандартные методы для оценки глубины видеозаписи, как COLMAP, часто не справляются с определением глубины движущихся объектов. Нейросетевые методы предсказывают глубину сцены на видеозаписи покадрово. Однако покадровые предсказания, когда их объединяют в видеозапись, часто геометрически неконсистентны. Исследователи предлагают подход, который решает проблемы неконсистентности предсказанной глубины и движущихся объектов.
Что внутри модели
Модель принимает на вход видеозапись и оценивает расположение камеры и карту глубины для каждого кадра видеозаписи. Ключевым преимуществом подхода является геометрическая консистентность покадровых предсказаний.
Подход работает в два этапа:
- Препроцессинг: чтобы информацию о геометрических ограничениях, исследователи используют COLMAP и Mask R-CNN. Mask R-CNN помогает сегментировать на видеозаписи людей и не учитывать регионы с людьми в дальнейшем анализе;
- Обучение модели: исследователи дообучают предобученную сеть для оценки глубины, чтобы повысить стабильность предсказаний
Сравнение с state-of-the-art
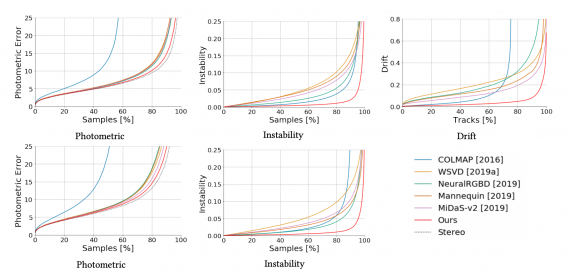
Исследователи сравнили предложенный подход с state-of-the-art методами. Ниже отображено количественное сравнение моделей.