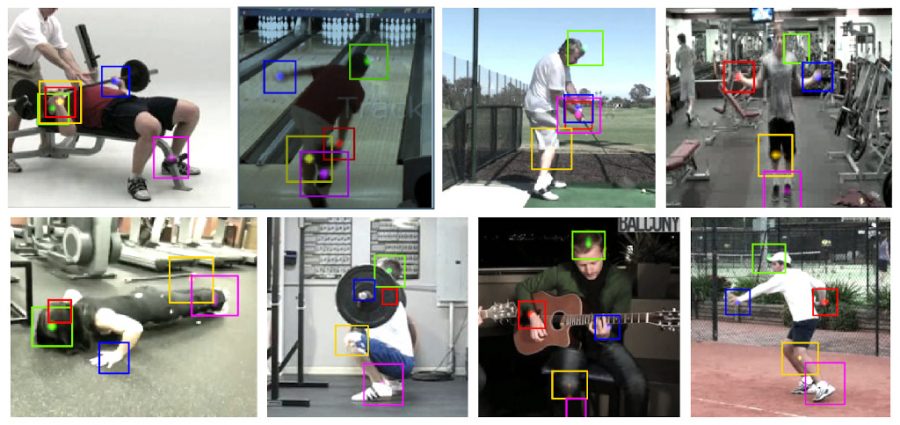
Оценка позы человека и распознавание действия — это связанные задачи, потому как обе проблемы зависят от представления и анализа тела человека. Тем не менее большинство существующих моделей решают эти проблемы раздельно. Исследователи предлагают мультизадачный фреймворк, который решает задачи совместной оценки 2D и 3D поз из изображений и классификации действий по видеозаписи.
Одна архитектура справляется с обеими задачами на уровне state-of-the-art подходов. При этом модель на инференсе обрабатывает более 100 кадров в секунду. Предложенная нейросеть использует разделяет параметры при решении задач оценки позы и классификации действий.
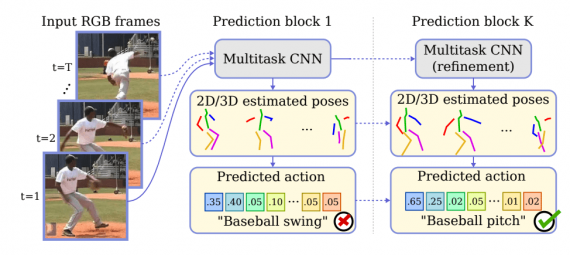
Архитектура подхода
Процесс работы модели состоит из следующих шагов:
- Из входных изображений извлекаются карты признаков;
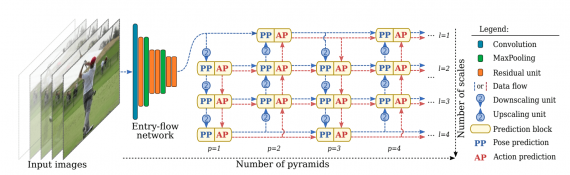
- Карты признаков поступают на вход последовательности сверточных сетей, которые состоят из блоков предсказаний (PB), модулей апскейлинга и даунскейлинга (UU и DU) и skip-связей;
- Каждый PB блок выдает предсказания позы и действия. Эти предсказания уточняются в последующих блоках
Модель обучали полностью на размеченных данных.
Оценка работы модели
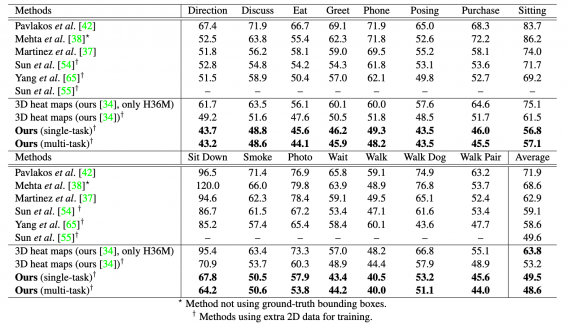
Исследователи тестировали модель на четырех датасетах: MPII, Human3.6M, Penn Action и NTU RGB+D. Ниже видно, что для датасета Human3.6M нейросеть обходит предыдущие подходы в точности классификации действий по видео.