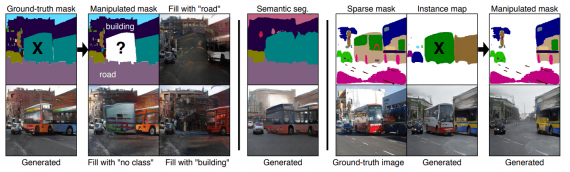
Исследователи из ETH Zurich разработали нейросеть, которая позволяет контролировать генерируемое изображение с помощью высокоуровневых атрибутов и текстовых описаний. На вход модели можно подать маску сегментации объектов с их классами. Нейросеть выдаст аналогичное по структуре изображение. Кроме того, можно редактировать содержание изображения с помощью текстовых запросов. В список возможных действий входят перемещение, удаление или добавление объектов. Модель выучивается разделять передний и задний планы изображения.

Проблема существующих моделей
Предыдущие подходы имеют три ограничения:
- При удалении объекта фон заполняется с артефактами;
- В реальных задачах часто нет доступа к размеченным маскам сегментации всех объектов на изображении
Предложенная модель обходит эти ограничения. Для генерации изображения используется разреженные сегментационная маска и карта объектов.
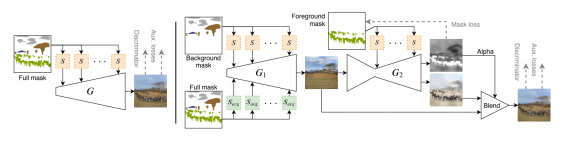
Архитектура модели
Итоговая модель состоит из двух объединенных генераторов. Исследователи называют подход двухступенчатым. Первый генератор отвечает за генерацию заднего фона изображения. Второй генератор синтезирует передний план изображения, учитывая при этом результат первого генератора.
В качестве базы модели используется SPADE, для модулей условий. Предобученную VGG используют в генераторе.
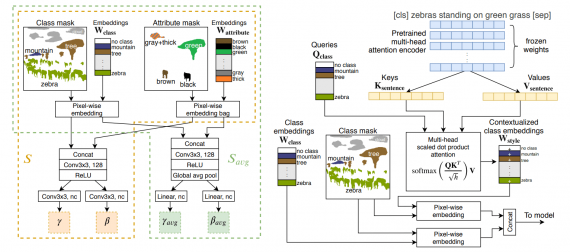
Оценка работы модели
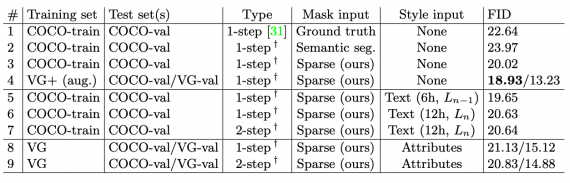
Исследователи сравнили двухступенчатую модель с базовой одноступенчатой. Для сравнения модели предобучали на разных датасетах: COCO2017, Visual Genome (VG), Visual Genome augmented (VG+).