
Предыдущие методы для детализированной оценки глубины человека по видеозаписи часто требуют размеченные тренировочные данные. Исследователи представляют self-supervised метод, который обучается на YouTube без разметки глубины. Это упрощает процесс сбора данных для обучения и улучшает обобщающую способность сети. Self-supervised обучение возможно за счет минимизации функции потерь, которая описывает консистентность изображения. Сначала модель генерирует грубую SMPL модель человека покадрово и учитывает движения тела на следующих кадрах. Это позволяет тренировать модель в self-supervised формате.
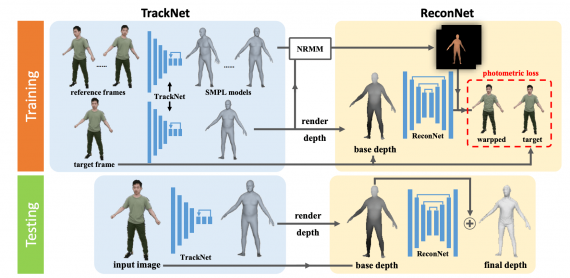
Архитектура подхода
Во время обучения система включает в себя:
- TrackNet, которая считает SMPL модель тела человека для каждого входного кадра видеозаписи;
- NRMM модель, которая учитывает движения тела человека между соседними кадрами и соотносить две формы человека с разных кадров;
- ReconNet для оценки деталей формы тела
Во время тестирования фреймворк сначала считает SMPL модель с помощью TrackNet, а затем оценивает детали формы с помощью ReconNet. Итоговая 3D-модель комбинирует в себе выходы TrackNet и ReconNet.
Оценка работы системы
Исследователи сравнили предложенный подход с state-of-the-art моделями для восстановления 3D-модели человека. Для сравнения выбрали модели HMD и Tang et al. Тестировали модели на датасете из видеозаписей с YouTube, которые модели не видели при обучении. Ниже видно, что предложенная система выдает более реалистичную модель человека в сравнении с предыдущими подходами. Количественная оценка моделей показала, что три модели выдают схожие результаты.

