
PlaNet (Deep Planning Network) — нейронная сеть от Google Brain и DeepMind, которая изучает модель мира, просматривая изображения, и применяет полученные знания для планирования своих действий.
Обучение с подкреплением для тренировки алгоритмов (когда сеть обучается с помощью вознаграждений) эффективно применяется для создания моделей принятия решений. Model-based обучение с подкреплением позволяет агенту четко планировать и точно выбирать действия (пример — алгоритм AlphaGo от DeepMind), но требует времени и больших вычислительных ресурсов.
Для планирования действий в неизвестной среде, например, для управления роботом, эффективнее обучить модель изучать механику из опыта, создав обобщенную модель, а не обучать каждому конкретному действию в отдельности. Поэтому для создания PlaNet исследователи из DeepMind решили использовать подход model-free, в котором агент обучается на основе сенсорных наблюдений.
Агент изучает контекст из первых 5 кадров, чтобы понять задачу и условия мира, и точно прогнозирует последовательность действий на 50 шагов вперед.
Как работает PlaNet
PlaNet создает динамическую модель данных на основе входящих изображений и использует их для получений нового опыта. Алгоритм использует модель скрытой динамики: вместо прямого прогнозирования от одного изображения к следующему, модель прогнозирует скрытое состояние. Изображение и вознаграждение на каждом этапе генерируются из соответствующего скрытого состояния.
Сжимая изображения таким образом, агент может автоматически запоминать более абстрактные представления, такие как положение и скорость объектов. Кроме того, использование скрытых представлений ускоряет планирование новых действий.
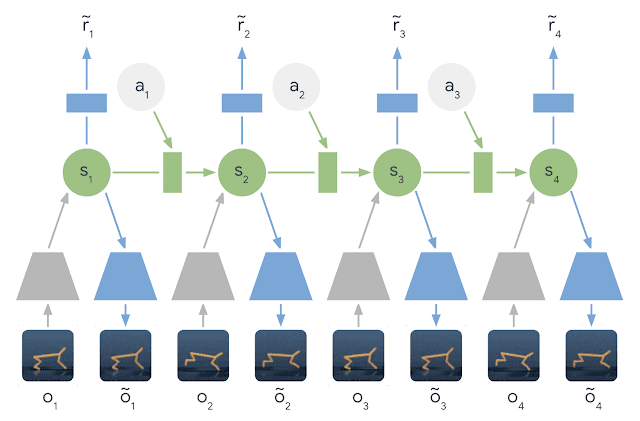
Агенту не нужно генерировать изображения: он должен спрогнозировать будущее вознаграждение, чтобы выбрать последовательность действий. Таким образом сеть может представить, как изменится положение мяча и его расстояние до цели от определенного действия без необходимости визуализировать сценарий.
PlaNet сравнивает 10 000 последовательностей действий с большим размером батча каждый раз, когда нужно спланировать действие и выбирает первое с наилучшей найденной последовательностью.
Результаты
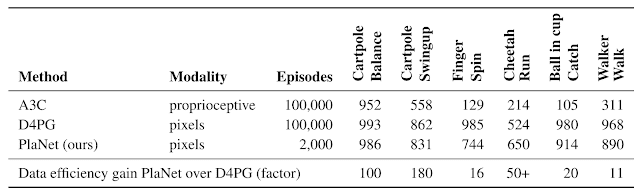
В тестировании PlaNet превзошла другие model-free подходы — A3C или D4PG. Более того, в случайно выбранной среде она научилась шести действиям за 2000 попыток, в то время как другим агентам требовалось в 50 раз больше для достижения сопоставимой производительности. PlaNet превосходит A3C во всех задачах и достигает конечной производительности, близкой к D4PG, при этом используя в среднем на 5000% меньше взаимодействия с окружающей средой.
Дальнейшие исследования будут направлены на изучение точных моделей динамики для задач высокой сложности, таких как движения в трехмерных средах и реальные задачи робототехники.
Подробнее о сети можно прочесть в блоге Google. Открытый код доступен на GitHub.



