В тюрьмах Нью-Йорка и других штатов по всей стране собирают базы данных «голосовых отпечатков» заключенных, используя технологии распознавания. По оценкам исследователей, власти собрали уже более 200 000 голосов разных людей. Сбор данных осуществляется незаконным образом, без согласия заключенных. Издание The Intercept провело расследование и выпустило подробный материал на эту тему.
Голосовое наблюдение
Чиновники исправительных учреждений в Техасе, Флориде, Арканзасе и Аризоне подтвердили, что сегодня они активно используют технологии распознавания голоса, такие как Securus и подобные для извлечения и оцифровки биометрических данных заключенных.

- База данных Securus Investigator Pro VoiceSearch
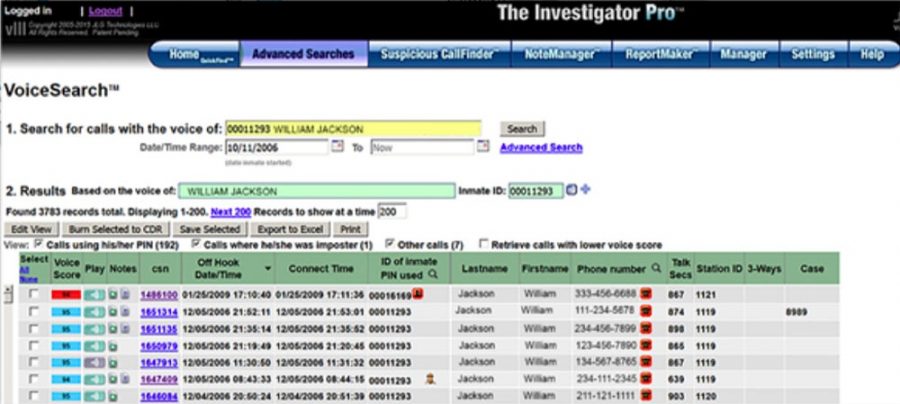
Программа распознавания голоса Securus идентифицирует голоса людей за пределами тюрем, как бывших заключенных, так и тех, кто никогда не нарушал закон, но общался с людьми в тюрьмах. В руководстве тюрем утверждают, что технология контролирует, какие посторонние лица регулярно общаются с несколькими заключенными.
Мера безопасности или нарушение прав?
В тюрьмах надеятся, что технология решит проблему заключенных, использующих личные идентификационные номера и PIN-коды друг друга. «Проблема заключается в том, что заключенные совершают преступные действия или связываются с потерпевшими и свидетелями и используют для этого PIN-код других заключенных» — говорят в руководстве. Голосовой отпечаток позволит точно отследить, кто совершил звонок.
Власти и технологические компании говорят, что это массовое биометрическое наблюдение поддерживает меры безопасности в тюрьмах и предотвращает мошенничество. Но защитники гражданских свобод утверждают, что сбор биометрических данных не был ни прозрачным, ни согласованным. Например, в некоторых тюрьмах Техаса и Аризоны заключенных не допускали к телефонам, если они отказывались регистрироваться в системе распознавания голоса. В других — просто регистрировали и записывали данные заключенных без их ведома.
Масштаб появляющихся в тюрьмах голосовых биометрических баз данных не был всесторонне задокументирован, при этом, по подсчетам исследователей, базы уже содержат более 200 000 отпечатанных голосов людей и 20 миллионов записей телефонных разговоров.