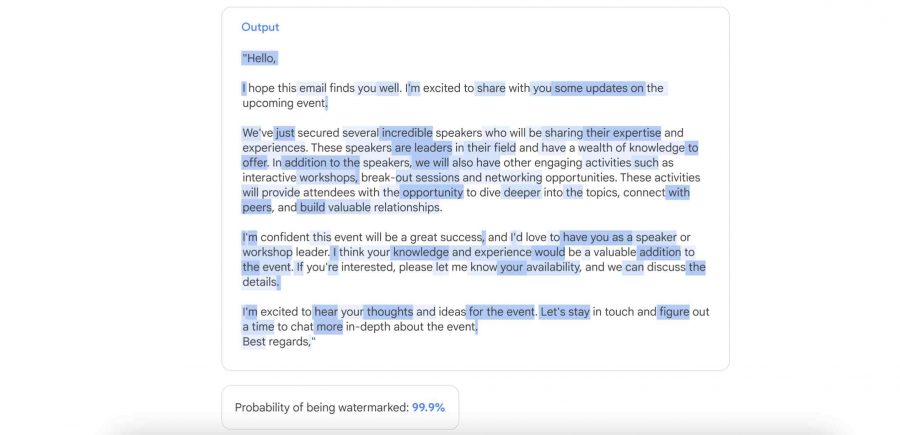
Компания DeepMind представила SynthID Text — новое открытое решение для маркировки генерируемого нейросетями текста, расширив тем самым свою экосистему идентификации ИИ-контента. Решение уже доступно в библиотеке Hugging Face Transformers v4.46.0+. SynthID Text дополняет ранее выпущенные инструменты Deepmind для изображений, аудио и видео.
В условиях, когда генеративный AI создает беспрецедентные объемы контента, надежная система водяных знаков становится критически важной для проверки происхождения контента и борьбы с дезинформацией. SynthID предлагает готовое решение для интеграции в LLM-пайплайны.
Метод был интегрирован в модель Google Gemini и протестирован на 20 миллионах ответах. При этом для обучения модели требуется всего несколько тысяч примеров, что делает ее практичной для внедрения в энтерпрайзы.
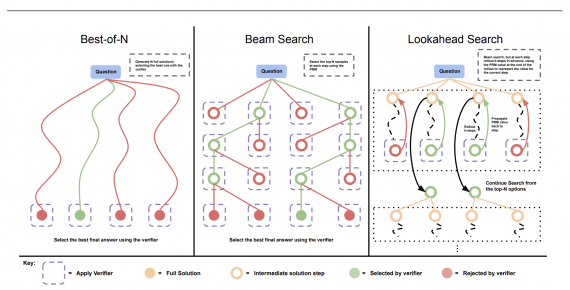
Метод SynthID
SynthID модифицирует процесс генерации токенов с помощью псевдослучайной g-функции. В частности, когда LLM генерирует текст, она предсказывает каждый следующий токен на основе распределения вероятностей. Затем SynthID корректирует эти вероятностные оценки, используя настраиваемые параметры, которые балансируют силу водяного знака и качество результата.
Технические детали
Ключевые параметры конфигурации включают:
- Keys: список случайных целых чисел, определяющих слои водяных знаков;
- ngram_len: значение (по умолчанию 5) обеспечивает баланс между обнаруживаемостью и устойчивостью;
- sampling_table_size: рекомендуется минимум 2^14 для несмещенной g-функции;
- context_history_size: управляет водяными знаками повторяющихся n-граммов.
Модельь использует байесовский детектор, который выдает три состояния: с водяным знаком, без водяного знака или неопределенное состояние. При этом пороги обнаружения можно настраивать для достижения определенных показателей ложноположительных и ложноотрицательных срабатываний. Следовательно, модели с одним токенизатором могут использовать общие конфигурации водяных знаков и детекторы при условии обучения на примерах всех участвующих моделей.
Варианты внедрения SynthID
Организации могут выбрать один из вариантов:
- Полностью приватный: без доступа к детектору;
- Полуприватный: доступ к детектору только через API;
- Публичный: открытое распространение детектора.
Известные ограничения
Несмотря на устойчивость к базовым текстовым модификациям и частичному перефразированию, SynthID показывает низкую эффективность при работе с фактологическими ответами и полностью переписанным контентом. Кроме того, перевод на другие языки существенно влияет на точность детектора.
SynthID представляет собой значительный прорыв в области водяных знаков для LLM, предлагая готовое к внедрению решение с гибкими вариантами и четкими компромиссами между безопасностью и удобством использования. Наконец, его интеграция в библиотеку Transformers делает его доступным для сообщества AI-разработчиков.