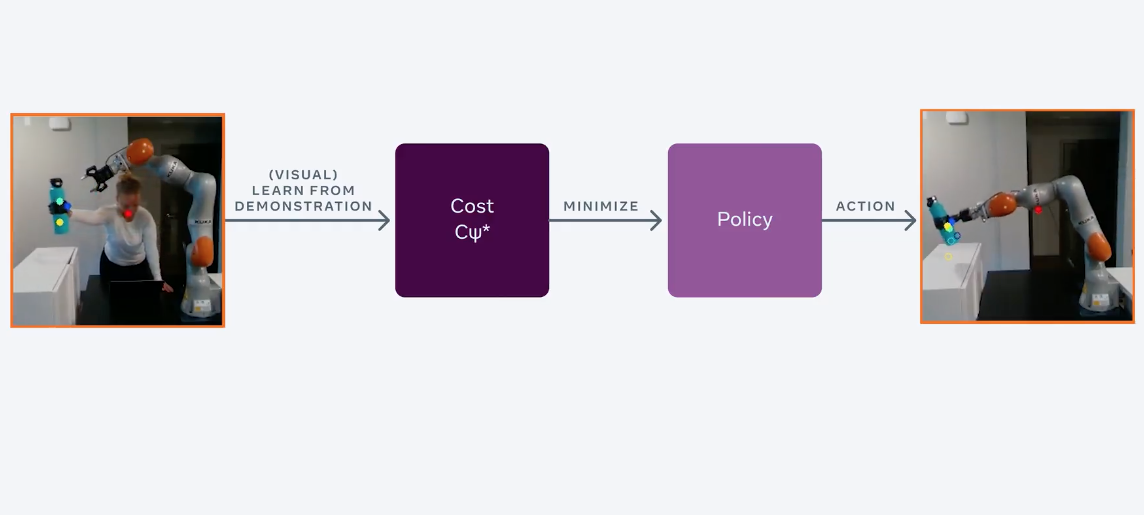
В FAIR RL-агента обучили управлять объектами по видеотьюториалам. Стандартные RL-алгоритмы обучаются задаче итеративно через обучение на ошибках. Предложенный алгоритм выучивает модель среды, наблюдает за поведением человека, а затем определяет функцию вознаграждения. Такой подход к обучению RL-агентов называется обратным обучением с подкреплением, основанным на модели среды (MBIRL).
Зачем это нужно
Люди легко выучивают новые простые задачи, как поднять и поместить объект на стол, через визуальные демонстрации. Однако роботам, чтобы научиться решать те же задачи, требуются вручную заданные для каждой отдельной задачи функции награды. Чтобы обучить робота ставить бутылку на стол, сначала необходимо установить вознаграждение за передвижение бутылки над столом. Затем — вознаграждение за то, что робот поставит бутылку на стол. Это медленный итеративный процесс, который не соотносится с реальным миром, где агенты должны постоянно выучивать новые простые задачи. Исследователи в FAIR переформулировали подход к обучению RL-агентов так, что бы робот учился выполнять новые задачи с помощью коротких видеоклипов.
Подробнее про подход
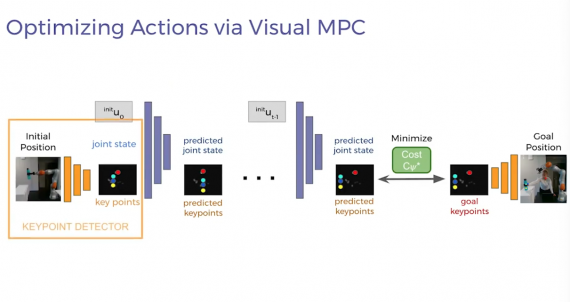
Важной частью предложенного подхода является модель, которая предсказывает изменения в том, что наблюдает. Большинство предыдущих работ предполагают, что известна динамическая модель среды, поэтому исследователи сначала учат робота выучивать модель среды с помощью детекторов ключевых точек. Такие детекторы обучаются в self-supervised формате, что исключает траты на разметку обучающих данных и делает робота более устойчивым к изменениям среды.

Детекторы извлекают малоразмерные визуальные признаки из демонстраций человека и движений робота. Затем предобучается модель, с помощью которой робот может предсказать, как его действия меняют это малоразмерное представление. Робот может оптимизировать политику поведения с помощью своей визуальной динамической модели так, что бы максимизировать функционал вознаграждения. В качестве алгоритма оптимизации используют градиентный спуск.