3DDFA — это нейросеть, которая размечает лицо человека в 3D по видеозаписи. Реализация модели написана на PyTorch и доступна в открытом репозитории на GitHub. Репозиторий содержит код проекта, предобученные MobileNet-V1 сети и предобработанный датасет для обучения и тестирования. На инференсе 3DDFA обрабатывает изображение за 0.27 миллисекунд на GeForce GTX TITAN X.

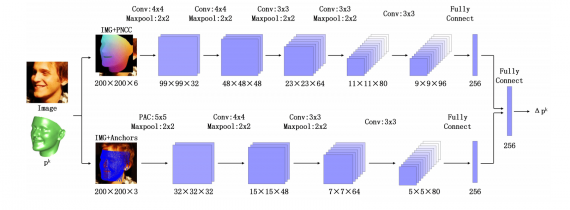
Архитектура подхода
3DDFA комбинирует в себе каскадную регрессию и сверточные сети. CNN применяется как регрессор в каскадной сверточной сети. Фреймворк состоит из четырех компонентов: функционал регрессии, признаки изображения, структуры сверточной сети и функция ошибки для обучения модели.
Нейросеть работает в два потока:
- В первом потоке с промежуточным обучаемым параметром конструируется Projected Normalized Coordinate Code (PNCC), который вместе с входным изображением отправляется на вход CNN;
- На втором потоке модель получает якоря признаков с консистентной семантикой и проводит Pose Adaptive Convolution (PAC) на них
Выходы из двух потоков объединяются с помощью дополнительного полносвязного слоя, который предсказывает обновление промежуточного параметра.
Оценка работы подхода
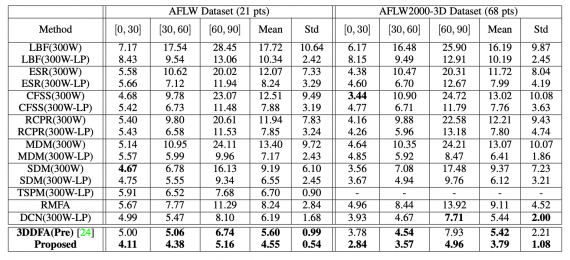
Исследователи сравнили предложенную 3DDFA с state-of-the-art методами для 3D разметки лица. Тестировали модели на датасетах AFLW и AFLW2000-3D. В качестве метрики использовали NME (%). Ниже видно, что предложенный подход выдает результаты выше или сравнимые с state-of-the-art.