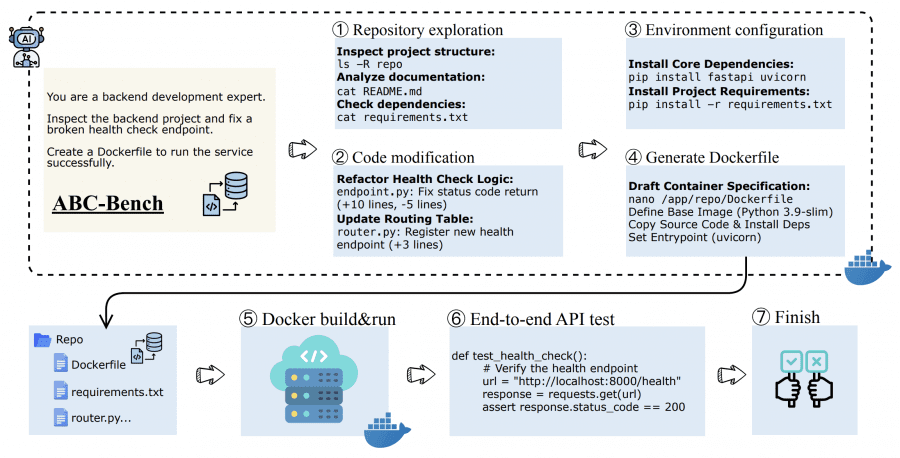
Команда исследователей из Fudan University и Shanghai Qiji Zhifeng Co. представила ABC-Bench — первый бенчмарк, который проверяет способность ИИ-агентов решать полноценные задачи backend-разработки: от изучения кода в репозитории до настройки окружения и запуска сервиса в контейнере. Результаты показывают, что даже лучшие модели справляются только с 63.2% задач, а основная проблема — не написание кода, а настройка окружения и развертывание. Проект частично открытый: исследователи опубликовали код платформы оценки на Github, а датасет доступен на Hugging Face.
Зачем нужен еще один бенчмарк для кода
Типичная задача backend-разработчика выглядит так: нужно открыть незнакомый проект на GitHub, исправить баг в API, настроить все зависимости, написать Dockerfile и запустить сервис так, чтобы он принимал HTTP-запросы и корректно на них отвечал. Существующие бенчмарки вроде SWE-bench проверяют только часть этого процесса — например, умение редактировать код. Но они не проверяют, сможет ли модель настроить окружение и развернуть работающий сервис.

ABC-Bench заполняет этот пробел. Он проверяет полный цикл: агент должен изучить структуру репозитория, понять, что нужно исправить, написать код, настроить зависимости, создать Dockerfile, и в конце система автоматически запускает сервис в Docker-контейнере и проверяет его работу через настоящие HTTP-запросы к API.
Как собирали датасет
Исследователи создали автоматизированный пайплайн — ABC-Pipeline, который превращает открытые GitHub-репозитории в задачи для бенчмарка. Процесс состоит из трех фаз:
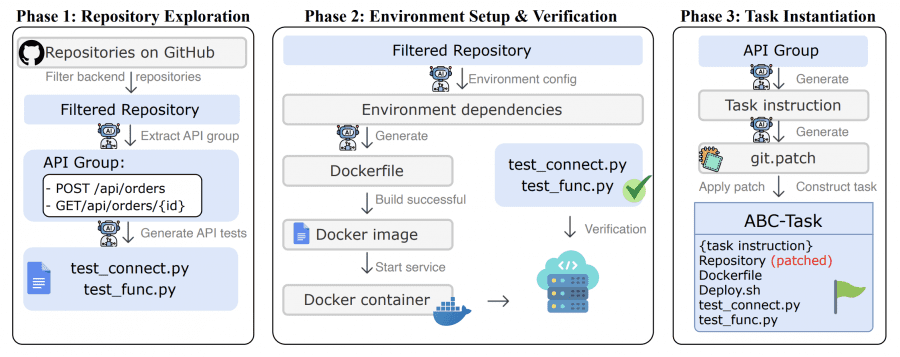
- Фаза 1: исследование репозитория. Система берет 2,000 open-source проектов с MIT-лицензией и фильтрует backend-проекты. Специальный агент на базе GPT-5 изучает каждый проект, находит рабочие API endpoints и автоматически генерирует тесты для них. Тесты проверяют две вещи: подключение к сервису и корректность бизнес-логики.
- Фаза 2: настройка окружения. Агент анализирует зависимости проекта и создает Dockerfile. Потом система пытается собрать Docker-образ и запустить сервис. Если сервис успешно стартует и слушает нужный порт — окружение настроено правильно.
- Фаза 3: создание задачи. Агент формулирует задание на естественном языке и создает solution patch — правильное решение. Потом система применяет обратную операцию: удаляет реализацию нужного endpoint, имитируя ситуацию «код еще не написан». Для 92 задач из 224 также удаляются все файлы настройки окружения, и модель должна создать их сама.
Результат: 224 задачи, покрывающие 8 языков программирования (C#, JavaScript, Python, Java, Ruby, PHP, Go, Rust) и 19 фреймворков (ASP.NET Core, Express, FastAPI, Spring Boot, Ruby on Rails и другие). Задачи охватывают разные домены: от аналитики и e-commerce до DevTools и систем аутентификации.

Как работает оценка
Тестирование происходит в изолированной sandbox-среде. Агент получает задачу и полный доступ к репозиторию. Он может изучать файлы, редактировать код, устанавливать зависимости, создавать Dockerfile — все что угодно. Когда агент отправляет решение (или заканчивается лимит на количество действий), система пытается собрать Docker-образ из того, что создал агент, и запустить сервис.
Успешным считается решение, которое проходит два условия: сервис успешно запустился в контейнере и прошел все функциональные тесты через внешние HTTP-запросы. Например, если задача была исправить endpoint `POST /api/orders`, то система отправляет настоящий POST-запрос на этот адрес и проверяет, что вернулся правильный HTTP-статус (например, 200) и корректные данные в ответе. Это принципиально отличается от других бенчмарков, где проверяют только логику кода через unit-тесты.
Результаты: модели пока далеки от идеала
Протестировали 11 моделей: open-source (Qwen3-8B, Qwen3-32B, DeepSeek-V3.2, GLM 4.7, специализированные Qwen3-Coder и агентные Nex-N1) и проприетарные (GPT-5, Gemini 2.5 Pro, Claude Sonnet 4.5). Все модели запускали через агентный фреймворк OpenHands, каждую задачу пробовали решить три раза с температурой 0.7 для обычных моделей и 1.0 для reasoning-моделей.
Лучший результат показал Claude Sonnet 4.5 с 63.2% успешности. DeepSeek-V3.2 набрал около 50%, GPT-5 — 49.4%. Маленькие модели вроде Qwen3-8B не дотянули даже до 10%. Интересно, что результаты сильно зависят от языка программирования: на Python, Go и JavaScript модели справляются лучше, а на Rust большинство моделей показали 0% — справились только Claude Sonnet 4.5 (33.3%) и GPT-5 (41.7%).
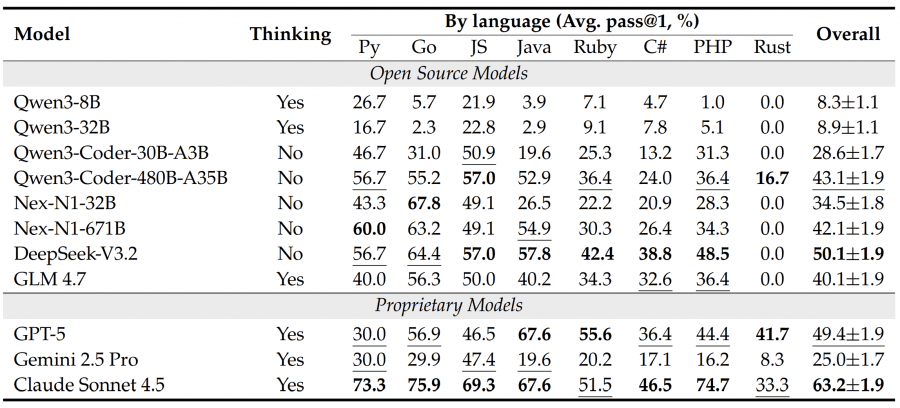
Для 92 задач, требующих настройки окружения, исследователи разделили процесс на два этапа: S1 (Environment Build) — успешная сборка и запуск сервиса, S2 (Functional Execution) — прохождение функциональных тестов среди тех задач, где S1 успешен.

Выявился интересный паттерн: Claude Sonnet 4.5 показывает сбалансированные результаты на обоих этапах (S1 ≈ 78%, S2 ≈ 80%). А вот GPT-5 и DeepSeek-V3.2 демонстрируют странный дисбаланс: они отлично справляются с написанием кода (S2 > 80%), но проваливаются на этапе настройки окружения (S1 < 50%). Это значит, что настройка окружения — основное узкое место, которое маскирует реальные способности моделей в программировании.
Какие ошибки делают модели
Исследователи классифицировали ошибки на шесть типов: синтаксические ошибки, отсутствующие пути к файлам, недостающие зависимости, ошибки компиляции, логические ошибки и прочее.
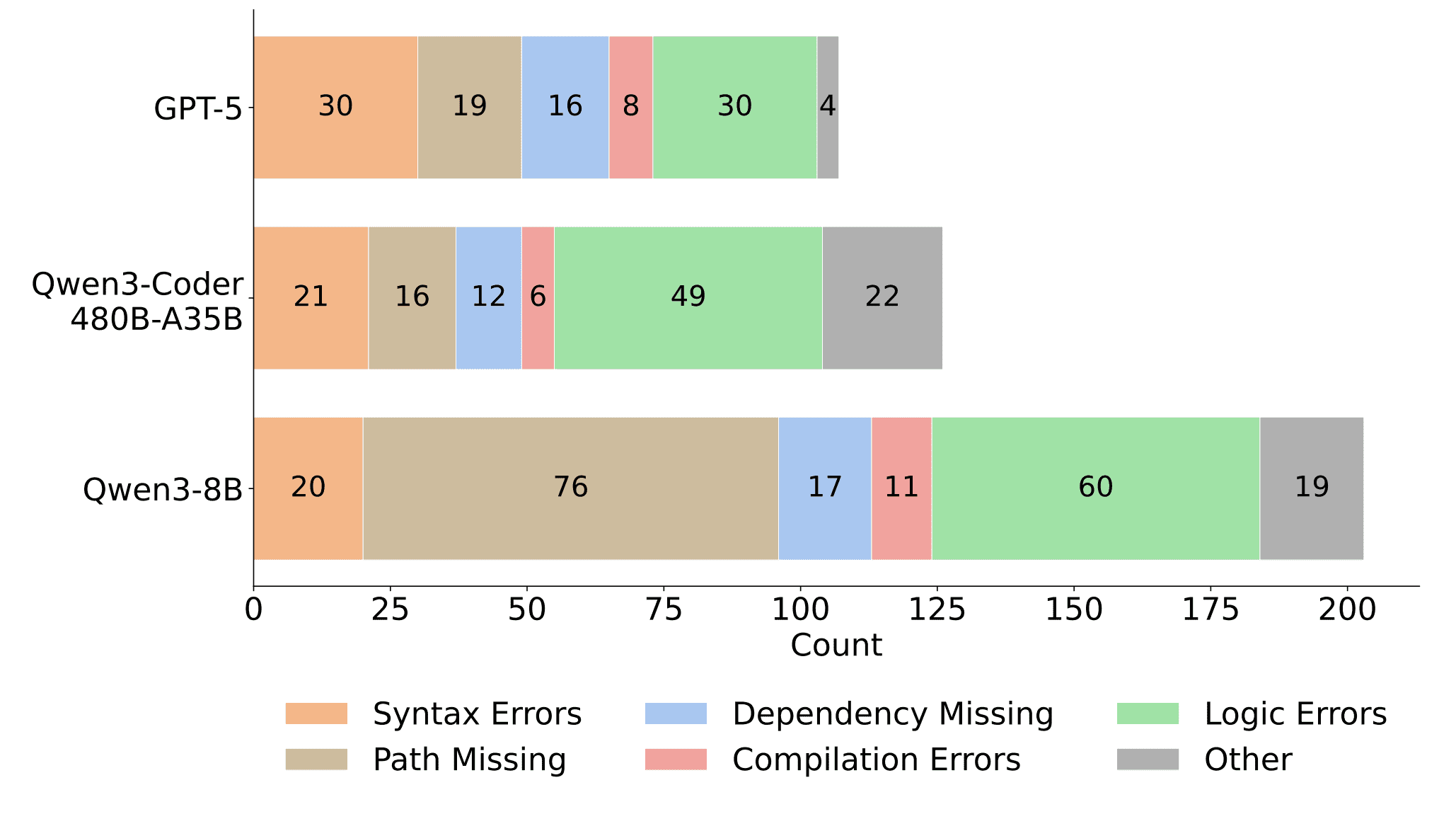
Интересные находки: маленькая Qwen3-8B делает 76 ошибок с путями к файлам — почти в четыре раза больше, чем GPT-5 (19 ошибок). Это показывает проблемы с навигацией по файловой системе. Зато у более крупных моделей GPT-5 и Qwen3-Coder-480B основная доля ошибок приходится на логические ошибки (30 и 49 соответственно) — они уже не ошибаются в синтаксисе, но не всегда правильно реализуют бизнес-логику.
Проблемы с окружением (Path Missing + Dependency Missing) встречаются у всех моделей, но их тяжесть зависит от размера: маленькие модели не справляются с базовой навигацией, большие — с правильной установкой зависимостей.
Дополнительные эксперименты
Фреймворк имеет значение. Протестировали DeepSeek-V3.2 и GPT-5 на трех агентных фреймворках: OpenHands, Claude Code и mini-SWE-agent. OpenHands показал лучшие результаты (~50% для обеих моделей), а mini-SWE-agent провалился, особенно для GPT-5 (упал до <20%). Агентное дообучение помогает. Взяли Qwen3-8B и Qwen3-32B, дообучили их на датасете агентных траекторий Nex-N1 (publicly available). Результаты: 8B модель выросла с 8.3% до 13.9%, а 32B — с 8.9% до 33.8%. Это показывает, что специализированное обучение на агентных задачах существенно улучшает результаты, причем большие модели эффективнее используют такие данные. Есть корреляция между глубиной взаимодействия и успехом. Лучшие модели вроде Claude Sonnet 4.5 делают в среднем >60 итераций (turns) с окружением, а слабые вроде Qwen3-8B — около 10. Корреляция r = 0.87 говорит, что способность к долгим итеративным сессиям с отладкой критична для успеха.
Что в итоге
ABC-Bench показывает, что между академическими бенчмарками и реальной backend-разработкой огромная пропасть. Даже топовая модель справляется только с 63% задач, а основная проблема не в написании кода, а в настройке окружения и развертывании. Модели отлично решают задачки на HumanEval или MBPP, но когда нужно развернуть рабочий сервис с зависимостями и Docker — проваливаются.
Интересно, что проблемы различаются по размеру модели: маленькие не справляются с базовыми вещами (пути, синтаксис), большие — с логикой и конфигурацией. Rust оказался особенно сложным языком — только самые мощные проприетарные модели смогли решить хоть что-то.
Бенчмарк будет расширяться новыми задачами, а методология адаптироваться под улучшающиеся модели. Главный вывод: до настоящих ИИ-инженеров, способных самостоятельно вести полный цикл backend-разработки, еще далеко.









