CFBI — это нейросеть, которая сегментирует объекты на заднем и переднем планах в видеозаписи. Нейросеть обучалась частично с привлечением размеченных данных (semi-supervised). CFBI отличается от предыдущих подходов тем, что модель учитывает эмбеддинги на уровне пикселя и объекта при предсказании. Модель обходит state-of-the-art подходы на датасетах DAVIS 2016, DAVIS 2017 и YouTube-VOS. Код проекта доступен в репозитории на GitHub.
Архитектура модели
Пайплан работы модели во время обучения состоит из следующих шагов:
- Сначала из первого, предыдущего и текущего кадров извлекаются эмбеддинги уровня пикселей. Эмбеддинги извлекают из предобученной базовой (backbone) сети;
- Затем эмбеддинги первого и предыдущего кадров разделяются на пиксели заднего и переднего фонов. Разделение основывается на масках кадров;
- После этого используются модуль соотнесения переднего и заднего планов и механизм внимания, который помогает коллаборативной сети сгенерировать предсказание
Особенность CFBI заключается в том, что модель для предсказания использует эмбеддинги двух уровней: пикселя и инстанса. Кроме того, исследователи предлагают коллаборативный метод для учета объектов, которые находятся на заднем фоне кадра.
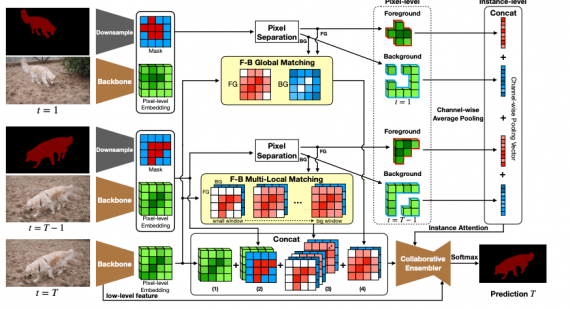
В качестве базовой сети использовали DeepLabv3+ с Resnet-101. Базовую модель предобучали на ImageNet и COCO.
Оценка работы нейросети
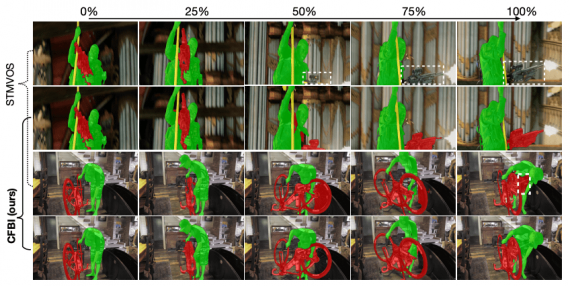
Исследователи сравнили предложенный подход с прошлой state-of-the-art моделью STMVOS. Модели сравнивали на датасете DAVIS 2017. Ниже видно, что STMVOS на выборочных кадрах выдает менее консистентные во времени предсказания, чем CFBI.