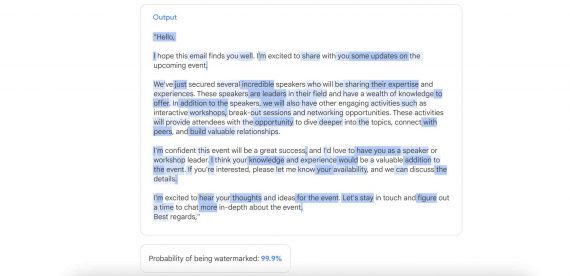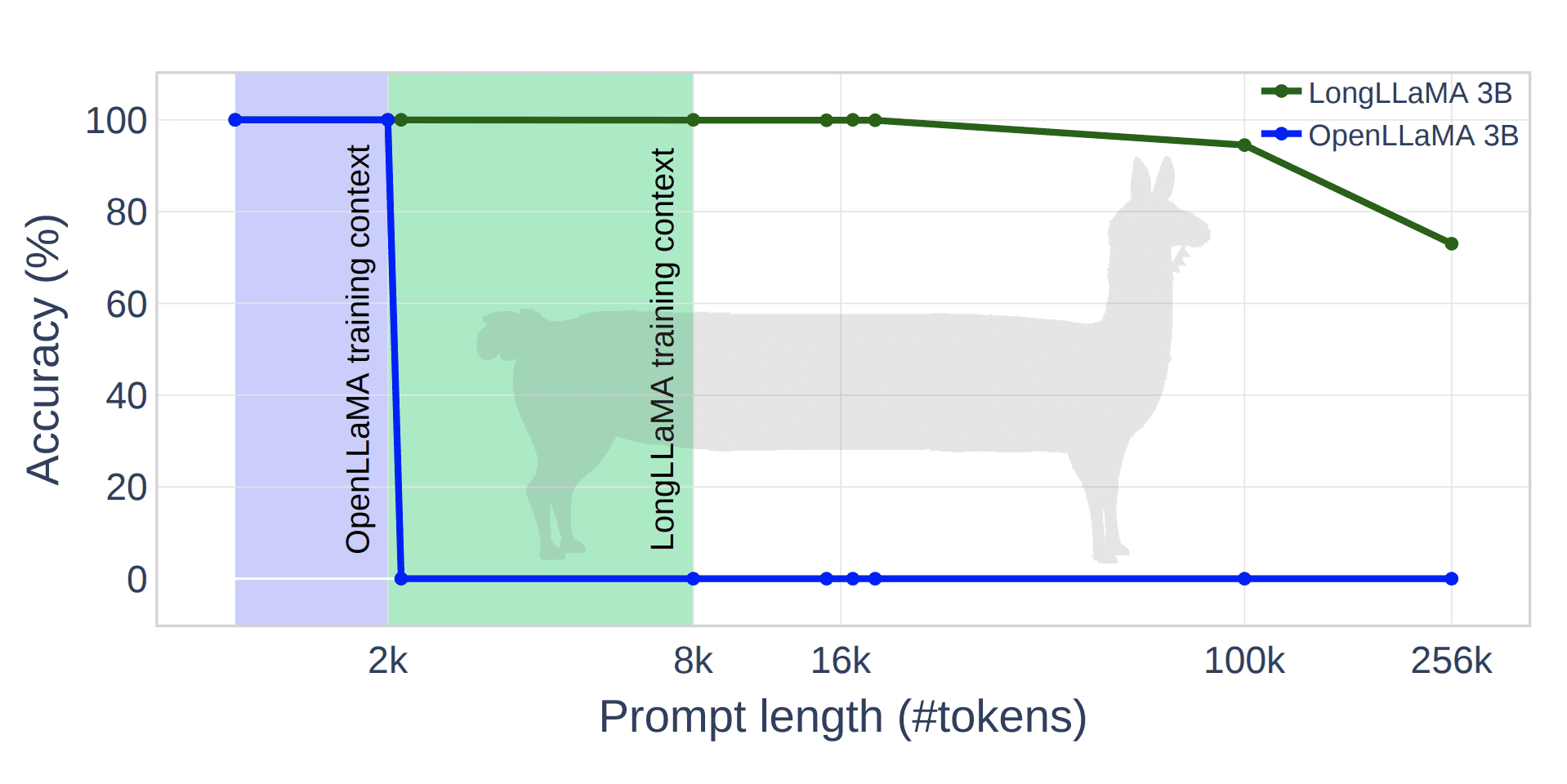
Новый метод Focused Transformer (FOT) позволяет дообучать большие языковые модели для расширения эффективного понимания контекста. Для демонстрации метода исследователи дообучиили open source модели OpenLLaMA 3B и 7B, результирующая модель LONGLLAMA показала прогресс в точности в задачах, требующих понимания длинного контекста. Модель LONGLLAMA-3B достигла точности 94,5% при 100 тысячах токенов и 73% при 256 тысячах токенов, в то время как базовая модель OpenLLAMA не способна обрабатывать контексты, превышающие ее длину обучения в 2 тысячи токенов. Код модели доступен на HuggingFace, подробнее о том, как запустить модель, смотрите на Colab.
Подробнее о методе
Новый метод решает проблему «отвлекающего фактора», при котором модели становится сложнее сосредотачиваться на релевантной информации по мере добавления несвязанных документов в контекст и точность предсказания падает. FOT использует подход на основе контрастного обучения, при котором модель обучается как на позитивных, так и на негативных примерах, чтобы улучшить структуру пространства (ключ, значение) и различать связанную и несвязанную информацию в контексте.
Архитектура модели
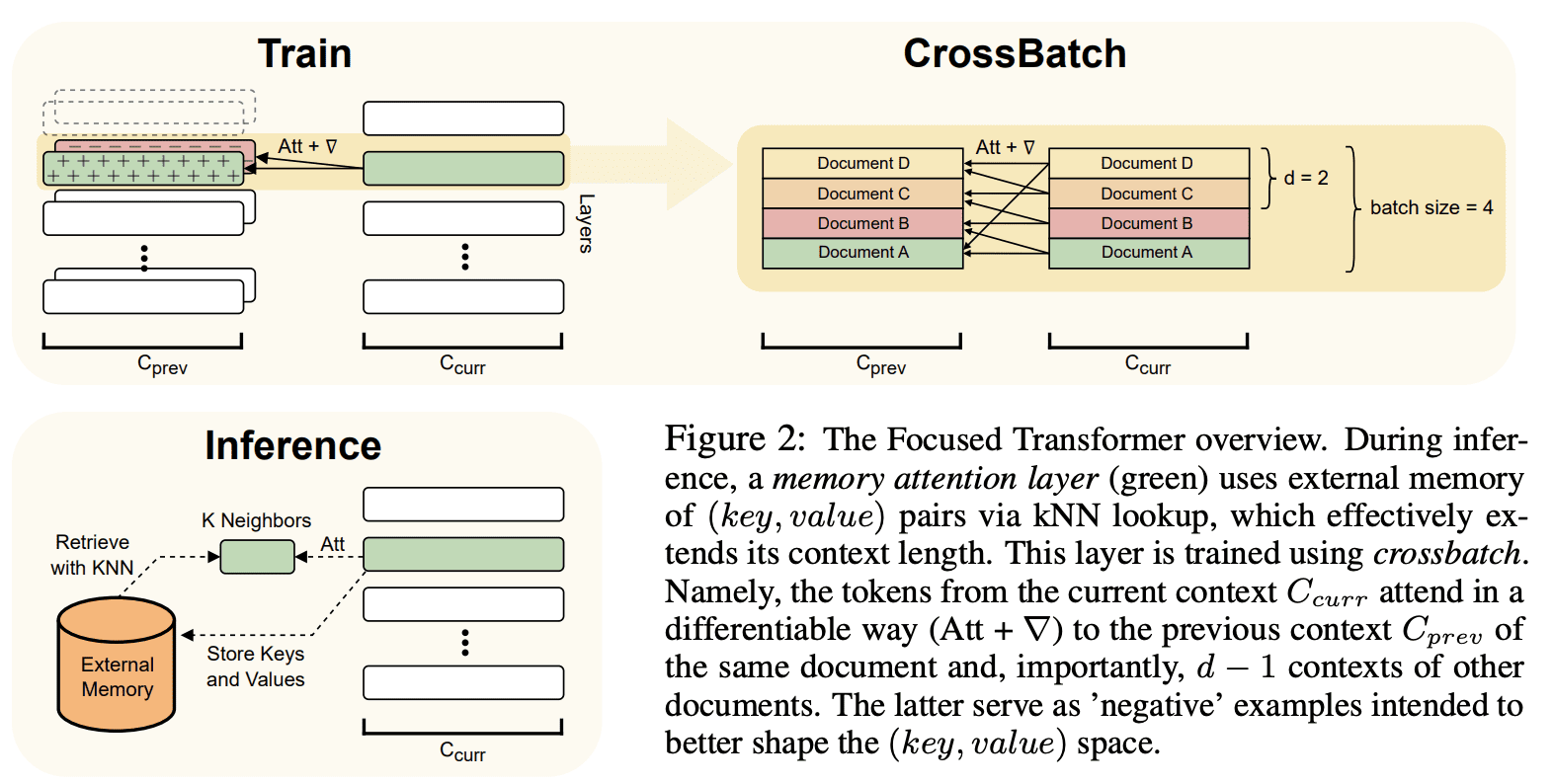
Архитектура FOT позволяет подмножеству слоев внимания получать доступ к внешней памяти пар (ключ, значение) через поиск ближайшего соседа. Модель обучается с использованием кросс-пакетов (crossbatch), где каждый элемент пакета соответствует отдельному документу. Модель обращается к предыдущему локальному контексту из того же документа (положительные примеры) и других документов (отрицательные примеры).
Результаты LONGLLAMA
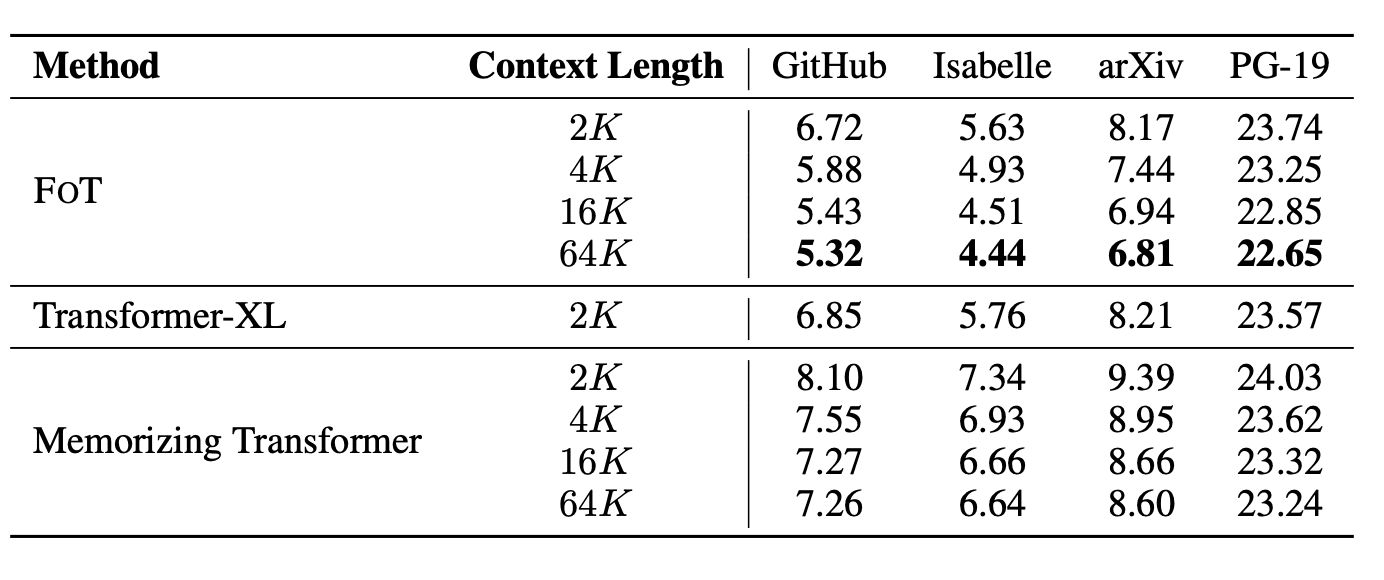
Исследователи оценили возможности метода FOT, настроив параметры модели OpenLLaMA для создания моделей LONGLLaMA. При выполнении задач, требующих более длинного контекста, модели LONGLLaMA показывают значительное улучшение точности по сравнению с моделями OpenLLaMA. FOT также достигает более низкой перплексии на датасетах с длинным контекстом, таких как PG-19, arXiv, GitHub и Isabelle.
Важно отметить, что LONGLLaMA обрабатывает контекст длиной 256 тысяч токенов при обучении с длиной контекста 8 тысяч.