Команда исследователей Apple представила Manzano — унифицированную мультимодальную большую языковую модель, которая объединяет возможности понимания и генерации визуального контента через гибридный токенизатор изображений и тщательно подобранную стратегию обучения. Авторегрессивная модель предсказывает высокоуровневую семантику в форме текстовых и визуальных токенов, а вспомогательный диффузионный декодер затем преобразует токены изображений в пиксели. Модель достигает SOTA результатов среди унифицированных моделей и конкурирует со специализированными моделями, особенно на задачах понимания текста в изображениях.
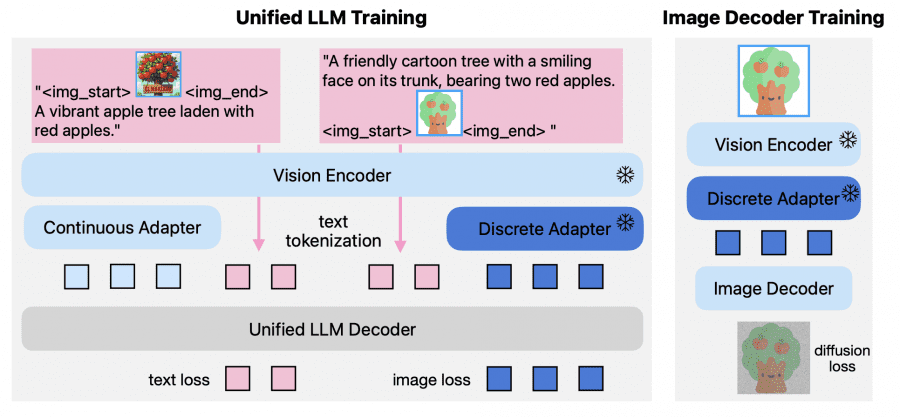
Архитектура модели Manzano
Основной проблемой существующих унифицированных моделей является конфликт между требованиями к визуальной токенизации для понимания и генерации. Авторегрессивная генерация обычно работает с дискретными токенами изображений, тогда как задачи понимания показывают лучшие результаты с непрерывными представлениями. Manzano решает эту проблему через гибридный подход.
Гибридный токенизатор изображений состоит из трех компонентов:
- стандартного визуального трансформера (Vision Transformer, ViT) в качестве основы,
- адаптера непрерывных представлений (continuous adapter) для задач понимания;
- адаптера дискретных представлений (discrete adapter) для генерации.
Адаптер непрерывных представлений применяет слой пространственно-канального преобразования 3×3 (Spatial-to-Channel) для сжатия пространственных токенов в 9 раз (с 42×42×1024 до 14×14×9216), затем использует многослойный перцептрон для проекции в размерность большой языковой модели. Адаптер дискретных представлений также начинает со сжатия, но дополнительно квантизует признаки через конечную скалярную квантизацию (Finite Scalar Quantization) с кодбуком размером 64k.
Унифицированный LLM декодер использует предобученные языковые модели и расширяет таблицу векторных представлений на 64K токенов изображений. Для понимания изображений токенизатор извлекает непрерывные признаки и подает их в языковую модель со стандартной функцией потерь следующего токена (next-token loss) на текстовых целях. Для генерации изображений адаптер дискретных представлений конвертирует входные изображения в последовательность дискретных идентификаторов токенов, делая мэппинг на токены изображений через расширенную таблицу векторных представлений.
Декодер изображений строится на архитектуре диффузионного трансформера (DiT-Air), которая использует послойное разделение параметров, сокращая размер стандартной модели многомодального диффузионного трансформера (MMDiT) примерно на 66% при сохранении сопоставимой производительности. Декодер использует конвейер сопоставления потоков (flow-matching pipeline) для транспорта гауссовского шума в реалистичные изображения, обусловленный дискретными токенами от большой языковой модели.
Трехэтапная стратегия обучения
Manzano использует специально разработанную методологию обучения, состоящую из трех этапов с различными пропорциями данных и целями.
Предварительное обучение (pre-training) проводится на смеси данных в пропорции 40/40/20: понимание изображений, генерация изображений и только текст. Модели до 3B параметров обучаются на 1.6 триллионах токенов, версия 30B — на 0.8 триллионах. Используются крупномасштабные корпуса: 2.3 миллиарда пар изображение-текст для понимания и 1 миллиард пар для генерации.
Продолженное предобучение (continued pre-training) добавляет 83 миллиарда высококачественных токенов с фокусом на документы, графики, многоязычный распознавание текста (OCR), синтетические описания и включает разделение изображений (image splitting) для лучшего понимания деталей.
Контролируемое дообучение (supervised fine-tuning) использует инструкционные данные в пропорции 41/45/14 для понимания, генерации и только текста соответственно. Для понимания применяется смесь 75% изображение-текст и 25% только текст, для генерации — комбинация реальных и синтетических данных объемом 4 миллиона примеров. Веса функций потерь балансируются в соотношении 1:0.5 для текста к изображениям
Результаты экспериментов
Manzano-3B превосходит унифицированные модели размером до 7B параметров и конкурирует со специализированными моделями. Наиболее впечатляющие результаты достигнуты на задачах понимания текста в изображениях: DocVQA (93.5 против 83.3 у Phi-3-Vision-4B и 40.8 у Janus-Pro-7B), OCRBench (85.7 против 63.7 у Phi-3-Vision-4B) и MathVista (69.8 против 44.5 у Phi-3-Vision-4B и 42.5 у Janus-Pro-7B). При масштабировании до 30B параметров модель достигает лидирующих позиций: ScienceQA (96.2), MMMU (57.8) и MathVista (73.3).
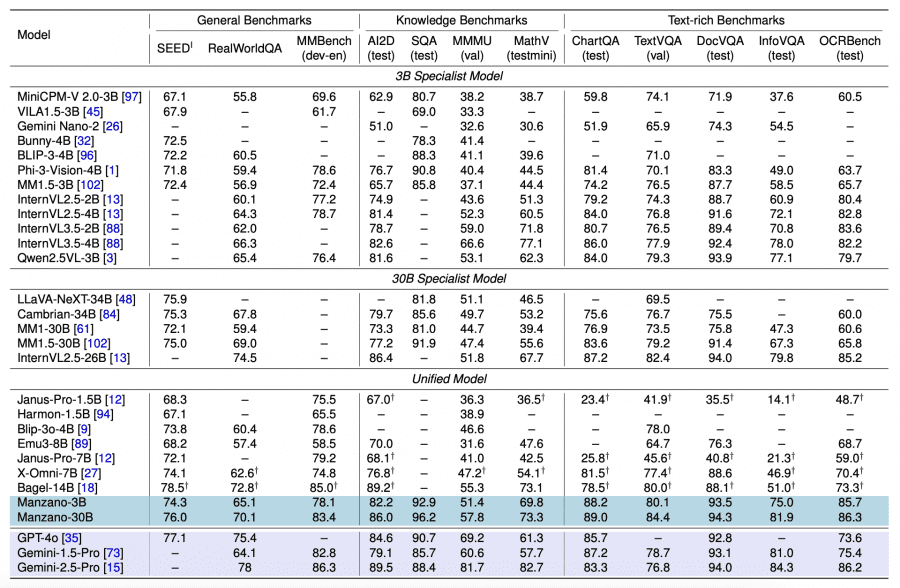
При масштабировании LLM decoder от 300M до 30B параметров наблюдаются консистентные улучшения по всем метрикам. Manzano-3B показывает прирост +14.2 (General), +18.8 (Knowledge), +10.9 (Text-rich) по сравнению с версией 300M. Дальнейшее масштабирование до 30B приносит меньшие, но устойчивые улучшения.
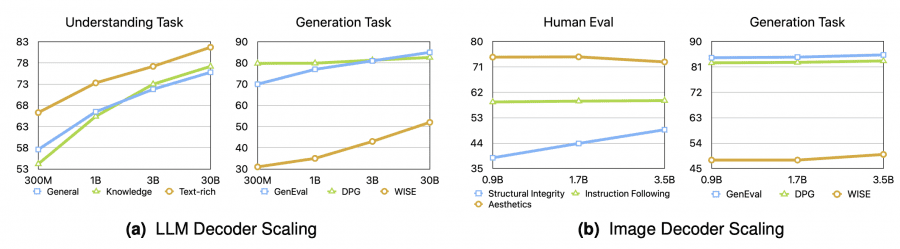
Исследование конфликта задач показывает минимальную деградацию: унифицированная модель показывает незначительное снижение производительности по сравнению с моделями, обученными только на понимании или только на генерации. При размере 3B разрыв составляет менее 1.0 балла, что демонстрирует успешность гибридного подхода.
Генерация изображений
На бенчмарках GenEval и WISE модель достигает state-of-the-art результатов среди унифицированных MLLM. Manzano-3B показывает конкурентные или превосходящие результаты по сравнению с гораздо большими унифицированными моделями. Масштабирование до 30B дает значительный прирост на WISE (+13 баллов), что подтверждает способность архитектуры к масштабированию.

Качественная оценка подтверждает количественные результаты. Модель справляется со сложными инструкциями, включая контринтуитивные запросы («птица летит под слоном»), точный рендеринг текста и создание изображений в различных художественных стилях.
Практические применения
Manzano поддерживает расширенные возможности редактирования изображений благодаря совместной работе LLM и декодера изображений с референсным изображением. Модель выполняет редактирование по инструкциям, перенос стиля, заполнение областей (inpainting), расширение границ (outpainting) и оценку глубины, сохраняя семантическую целостность при точном контроле на уровне пикселей.
Архитектура позволяет независимо масштабировать компоненты: декодер большой языковой модели отвечает за семантическое понимание, а декодер изображений — за детальный рендеринг. Это создает гибкую основу для дальнейшего развития унифицированных мультимодальных моделей.
Результаты исследования показывают, что объединение задач понимания и генерации не влечет за собой снижение точности. При грамотном архитектурном проектировании и качественных визуальных представлениях компактная и масштабируемая модель способна показывать высокие результаты в обеих областях одновременно.