Исследователи из UC Berkeley и Google DeepMind предложили новый метод оптимизации вычислений на этапе инференса для LLM и продемонстрировали, что увеличение вычислительных мощностей на этапе инференса может быть более эффективным, чем масштабирование параметров модели.
Этот подход открывает новые возможности для повышения производительности моделей без необходимости в увеличении их размера и затрат на предобучение.
Баланс между инференсом и предобучением
Традиционно повышение производительности LLM достигается за счет увеличения размера модели и количества вычислительных ресурсов, затрачиваемых на предобучение. Однако такой подход имеет ограничения, связанные с большими затратами на обучение и эксплуатацию. Исследователи предложили альтернативу: использование дополнительных вычислений на этапе инференса для повышения точности ответов моделей на сложные запросы. Это позволяет развертывать меньшие модели с производительностью, сравнимой с более крупными моделями, но с меньшими затратами на предобучение.
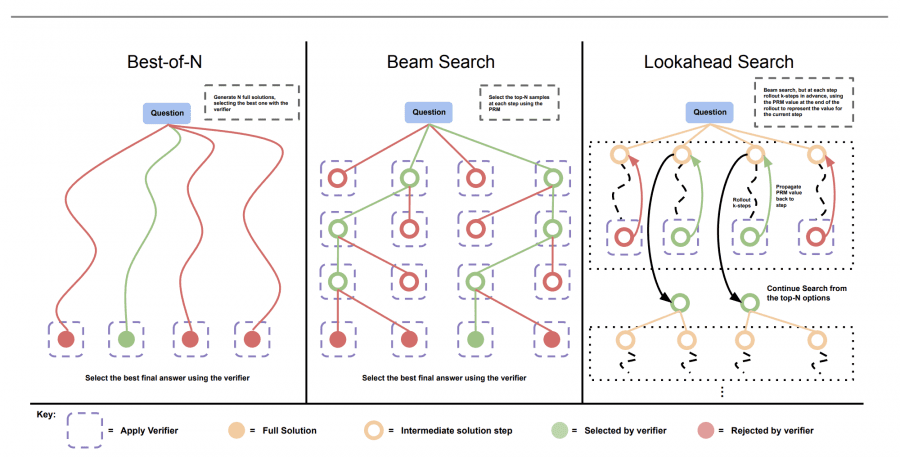
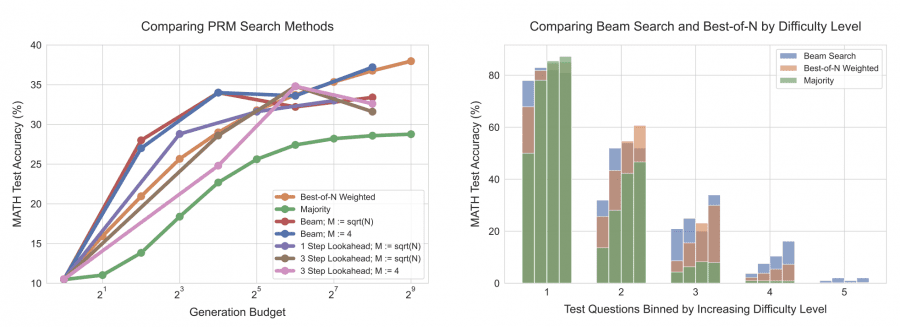
Сравнение методов поиска оптималного ответа:
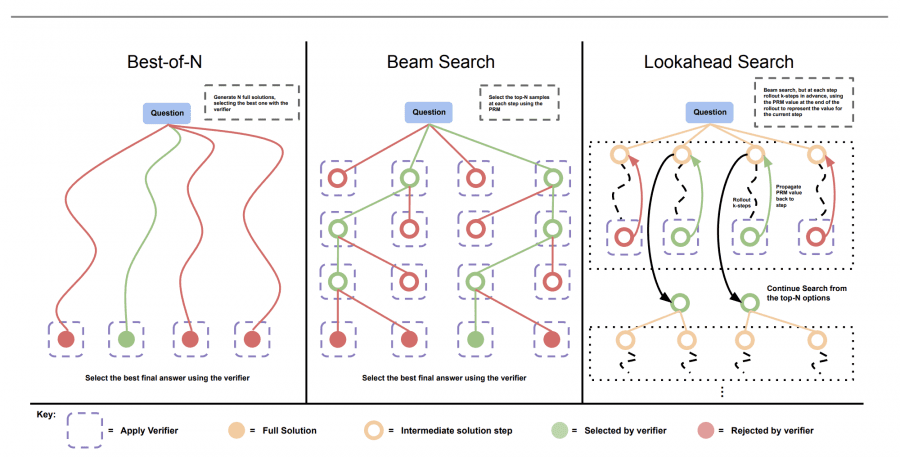
Основные стратегии оптимизации вычислений на этапе инференса
Исследование рассматривает два основных подхода к оптимизации инференса:
- Dense verifier reward models (плотные модели вознаграждения верификатора)
Этот метод использует модель, которая верифицирует правильность и релевантность сгенерированных ответов. Модель вознаграждения помогает выбрать наиболее подходящие ответы среди множества возможных вариантов и отправляет их в верификатор. - Adaptive updates to response distributions (адаптивные обновления распределения ответов)
Модель динамически корректирует свои ответы, анализируя уже полученные данные и перераспределяя ресурсы в зависимости от сложности задачи.
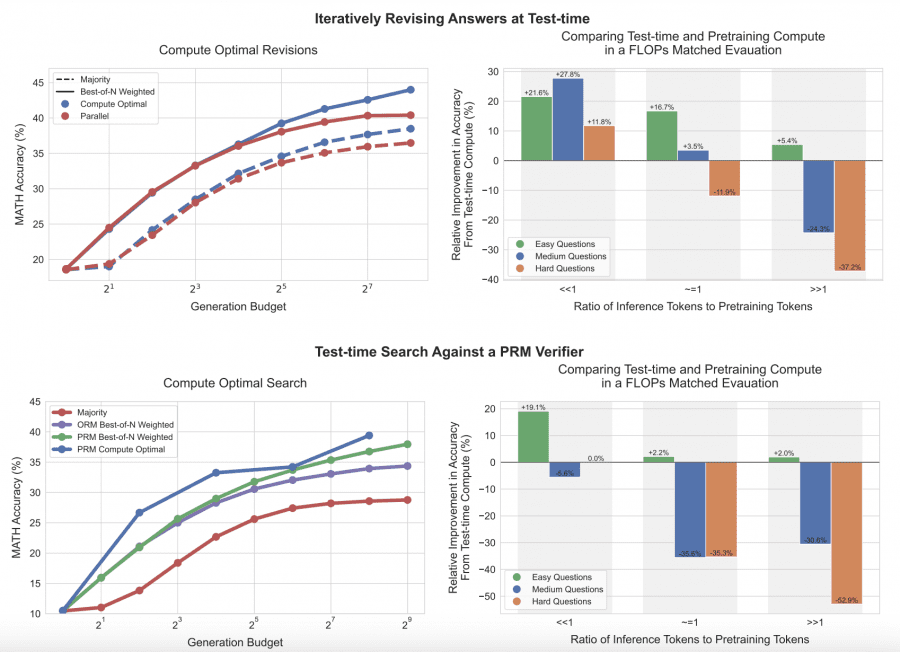
Lookahead Search улучшает производительность на сложных задачах
Описание: На этом графике показано, что при небольшом объеме вычислений лучшую производительность демонстрирует метод поиска лучшего ответа, однако с увеличением объема вычислений его эффективность снижается.
Lookahead Search использует лучевой поиск с прогнозом на несколько шагов вперед (k-шагов). На каждом этапе модель оценивает ценность решений, анализируя их влияние на последующие шаги. Затем значения наград PRM возвращаются обратно, чтобы корректировать поиск на предыдущих шагах. Это позволяет модели лучше предсказывать качество решений на ранних этапах и значительно улучшает производительность в сложных задачах. Lookahead Search демонстрирует преимущество перед стандартным лучевым поиском и другими методами, особенно при решении задач, требующих многоступенчатого анализа.
Применение адаптивных стратегий для улучшения инференса
В совокупности, модели вознаграждения верификатора, адаптивное обновление распределения ответов и Lookahead Search работают вместе, чтобы оптимизировать процесс инференса. Эти методы не конкурируют друг с другом, а дополняют друг друга, предоставляя модели возможность адаптироваться к различным уровням сложности задачи и эффективно распределять вычислительные ресурсы.
Для простых задач последовательные исправления оказались более эффективными, чем параллельная генерация множества вариантов ответов. В сложных задачах методы, такие как Lookahead Search, дают значительные преимущества за счет прогнозирования на несколько шагов вперед.
Оптимизация вычислений и замена предобучения
Исследователи также провели сравнение моделей с разным количеством параметров. В некоторых случаях оптимизация вычислений на этапе инференса позволила меньшим моделям показывать производительность, сопоставимую с моделями, которые в 14 раз больше по размеру. Это открывает перспективы для снижения затрат на обучение и эксплуатации моделей.
Заключение
Исследование показывает, что оптимизация вычислений на этапе инференса может быть более эффективной стратегией по сравнению с масштабированием параметров модели. Применяя такие методы, как Lookahead Search и адаптивное распределение вычислений, модели могут значительно улучшить производительность на сложных задачах без необходимости увеличения размеров моделей или затрат на предобучение.