Исследователи из Computer Vision Lab в ETH Zurich предлагают метод обучения и масштабирования существующих моделей семантической сегментации. Метод работает для датасетов с большим количеством семантических классов без увеличения нагрузок на память.
В чем проблема
State-of-the-art модели для распознавания объектов и классификации изображений хорошо работают для датасетов с 9-10 тысячами классов. Однако количество классов в датасетах семантической сегментации ограничено. Это связано со сложностями в разметке и получении данных.
Подробнее про подход
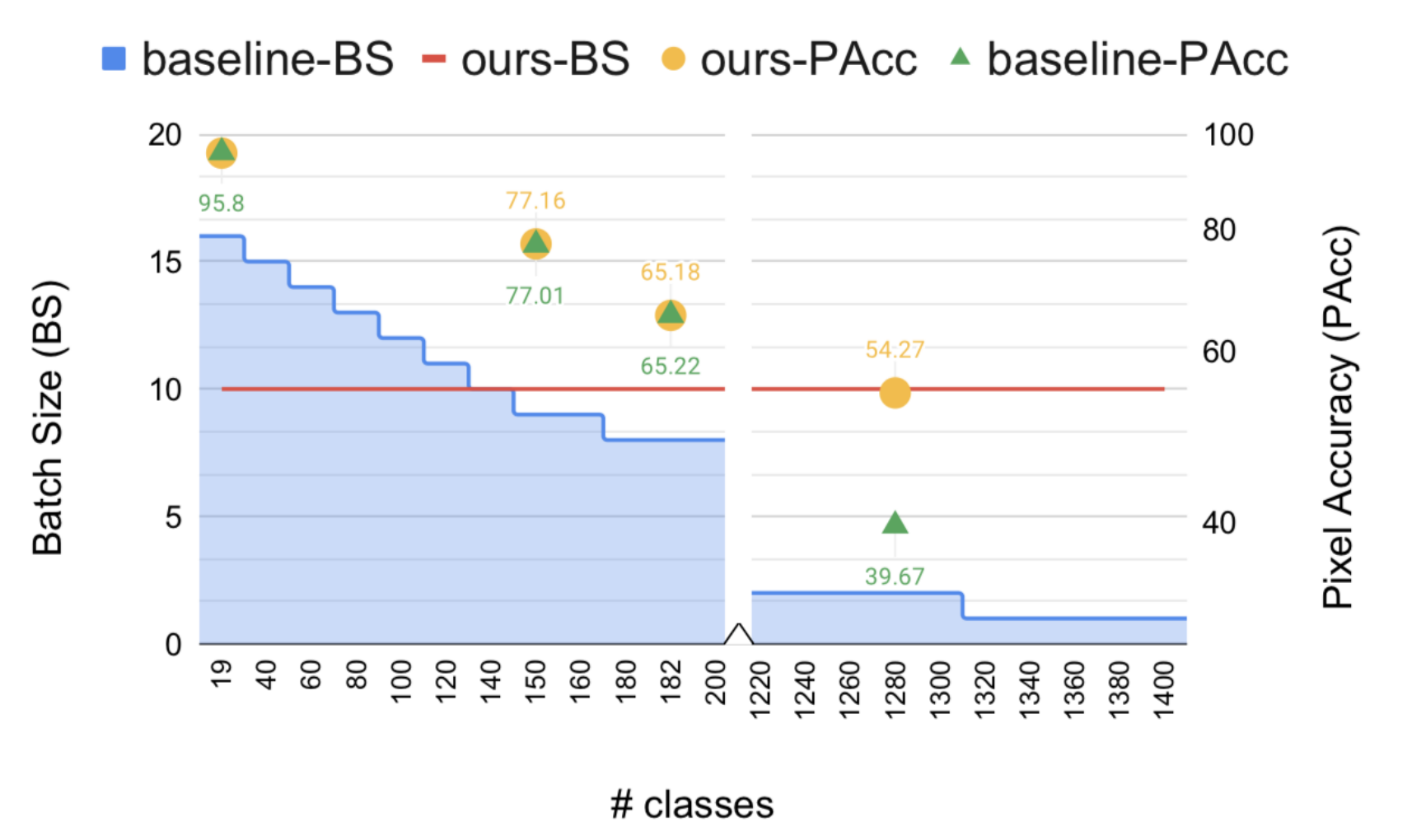
Предложенный подход для масштабирования сегментации основан на эмбеддингах. Сложность пространства выходов модели сегментации сокращается с O(C) до O(1). Кроме того, исследователи предлагают метод для аппроксимации вероятностей классов. Предложенный подход является универсальным и может использоваться в любой state-of-the-art модели сегментации. Подход полезен в том случае, если требуется решить задачу с большим количеством семантических классов на одной GPU.
Тестирование подхода
Метод тестировали на датасетах Cityscapes, Pascal VOC, ADE20k и COCOStuff10k. Он выдает схожие результаты с стандартной DeeplabV3+ моделью. На датасете с 1284 классами он выдает в три раза более точные предсказания (mIoU), чем DeeplabV3+ модель.
Код проекта доступен в открытом репозитории на GitHub.
