Команда из Shanghai Artificial Intelligence Laboratory и Пекинского университета опубликовала MinerU-Diffusion — фреймворк для распознавания текста в документах (OCR), который отказывается от классической авторегрессивной генерации в пользу диффузионного декодирования. Проект полностью открытый: код доступен на GitHub, а веса модели — на Hugging Face. Скорость декодирования выросла в 3.2 раза при сохранении точности, сравнимой с лучшими авторегрессивными (AR) конкурентами.
MinerU-Diffusion — это уже третье поколение в линейке MinerU: мы писали про MinerU2.5 в сентябре 2025 года — тогда команда показала, что 1.2B-модель обходит Gemini 2.5 Pro на бенчмарках документного парсинга. После выхода MinerU2.5 инструмент получил несколько обновлений на уровне фреймворка. В версиях 2.6–2.7 (октябрь 2025 — февраль 2026) добавили гибридный бэкенд, объединяющий pipeline и vlm, поддержку MLX-ускорения для Apple Silicon с приростом скорости 100–200%, обновили OCR-модели до ppocr-v5 с ростом точности на 40%+ для кириллицы и арабского, а установку упростили до одной команды. MinerU-Diffusion — это не очередное обновление фреймворка, а отдельная исследовательская работа с принципиально другим подходом к декодированию.
Недостатки авторегрессионного OCR
Большинство современных OCR-решений построены на архитектуре Vision-Language Model (VLM): визуальный энкодер переводит изображение в токены, а дальше авторегрессивный (AR) декодер генерирует текст токен за токеном — слева направо. Это работает, но у подхода есть принципиальный изъян. Когда модель генерирует токены по одному, каждый следующий зависит от всех предыдущих. Для длинного документа это медленно: задержка растёт линейно с длиной выхода. Хуже того, модель начинает опираться не только на картинку, но и на языковые паттерны — то есть «догадывается» о тексте, а не читает его буквально. Когда смысловая структура документа нарушается, AR-декодеры резко теряют точность именно из-за этой зависимости от языковых прайоров.
Авторы переформулируют задачу OCR как обратный рендеринг (inverse rendering). Документ двумерен: каждый элемент занимает конкретное место на странице. Чтобы подать его в языковую модель, нужно выстроить все элементы в одну строку токенов. AR-модели воспринимают этот порядок как обязательный и генерируют текст строго слева направо. Но выбор порядка — это просто инженерное решение при подготовке данных, никак не связанное с природой самого документа. MinerU-Diffusion использует это: раз порядок произвольный, токены можно восстанавливать параллельно, а не один за другим.
Как работает диффузионное декодирование
MinerU-Diffusion заменяет авторегрессию на диффузионную языковую модель (Diffusion Language Model, DLM) с дискретным маскированием. Идея простая: на старте весь выходной текст — это набор токенов [MASK]. На каждом шаге денойзинга модель смотрит на изображение документа и параллельно восстанавливает замаскированные токены, постепенно раскрывая текст.
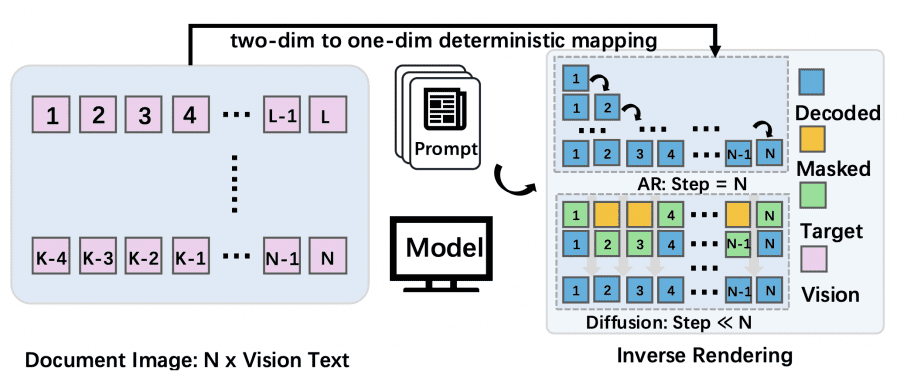
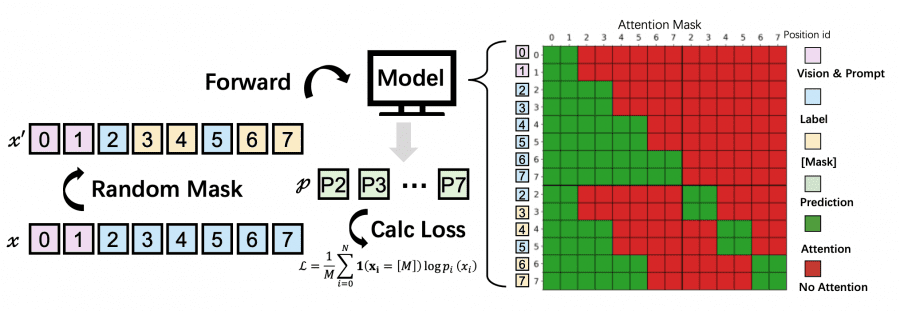
Но просто применить полное самовнимание ко всей последовательности — плохая идея: квадратичная сложность O(L²) убивает производительность на длинных документах. Вместо этого авторы вводят блочный диффузионный декодер (Block-Attn). Последовательность делится на B блоков. Внутри блока токены могут обращаться к любому другому токену блока (двунаправленное внимание). Между блоками — только каузальное внимание: каждый блок видит все предыдущие, но не следующие. Это даёт O(BL’²) вместо O(L²), плюс позволяет кэшировать KV-пары — так же, как в AR-моделях.
Умное управление параллелизмом: динамический порог уверенности
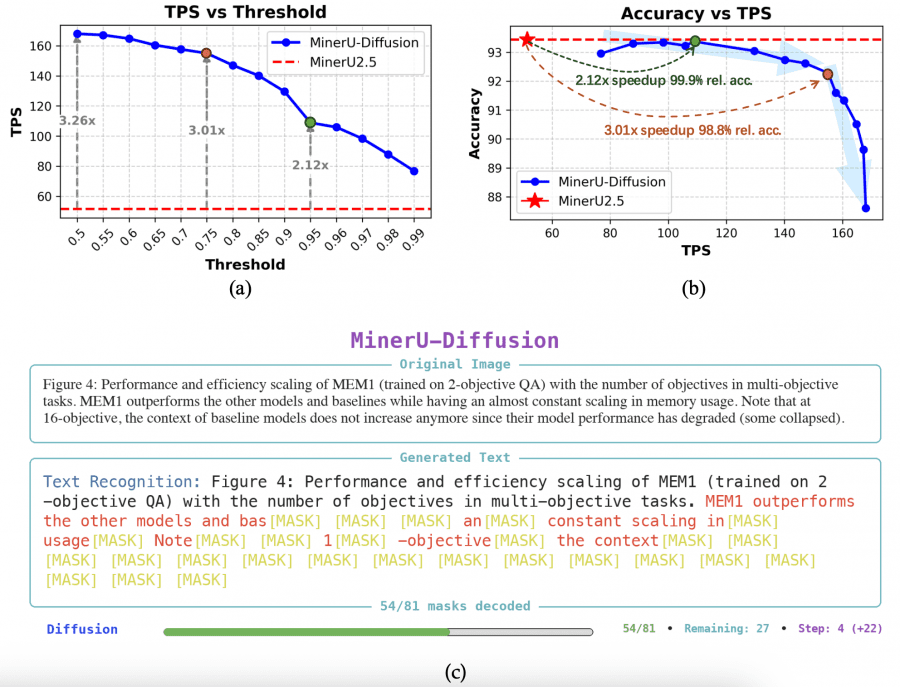
На каждом шаге денойзинга модель выдаёт для каждого токена вероятность. Если вероятность выше порога τ — токен «подтверждается» и больше не обновляется. Если ниже — остаётся маскированным до следующего шага. Порог τ напрямую управляет балансом скорость/точность. При τ = 0.5 почти все токены подтверждаются сразу — максимальная скорость, но выше риск ошибок. При τ = 0.99 модель работает почти как авторегрессивная — медленно, зато надёжно. При τ = 0.95 модель достигает 2.1× ускорения при 99.9% относительной точности по сравнению с MinerU2.5. При τ = 0.6 — пиковые 3.2× ускорения при точности выше 90%.
Двухэтапное обучение с учётом неопределённости
Диффузионные модели сложнее обучать, чем AR: маскирование разбрасывает обучающий сигнал, и модель менее эффективно использует данные. Авторы решают это через двухэтапный curriculum learning. На первом этапе модель обучается на широком датасете из ~6.9 миллиона примеров документов (Dbase). Цель — выучить общие паттерны верстки и распознавания. На втором этапе выбираются «трудные» примеры — те, где модель давала непоследовательные ответы при нескольких прогонах подряд. Непоследовательность измеряется метриками: PageIoU для разметки, CDM для формул, TEDS для таблиц. Эти примеры размечают с участием человека, и модель дообучается на них.

Semantic Shuffle: проверка на галлюцинации
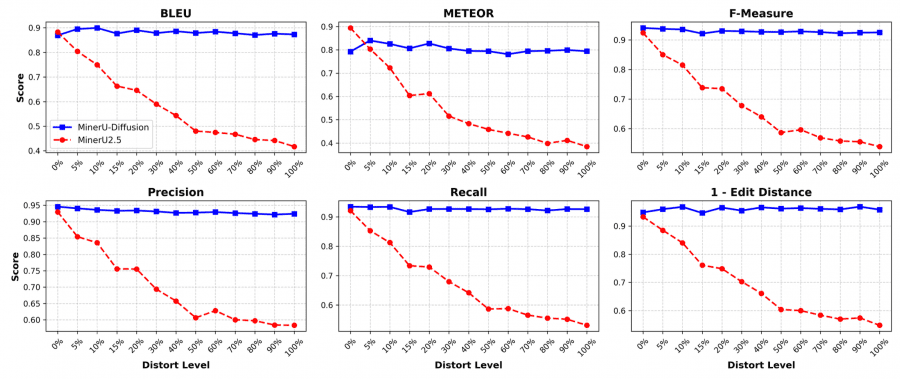
Чтобы проверить, читает ли модель картинку или просто угадывает текст по языковым паттернам, авторы придумали отдельный бенчмарк. Берут 112 английских документов, перемешивают слова в случайном порядке и рендерят результат в новые изображения с сохранением форматирования. Если модель опирается на визуальный сигнал — она должна воспроизвести бессмыслицу так же точно, как осмысленный текст. Если опирается на языковые прайоры — начнёт «исправлять» текст и терять точность.
AR-декодеры при росте степени перемешивания резко теряют качество по всем метрикам. MinerU-Diffusion при этом остаётся почти стабильным — BLEU, METEOR, F-Measure и edit distance практически не меняются при любом уровне искажения.
Результаты
Скорость в OCR-задачах измеряется в TPS (tokens per second — токенов в секунду). MinerU2.5 выдаёт ~52 TPS. MinerU-Diffusion при пороге τ = 0.95 достигает 108.9 TPS — в 2.1× быстрее при практически той же точности. На пиковой скорости (τ = 0.6) — 164.8 TPS, то есть 3.2× быстрее. Для сравнения: PaddleOCR-VL выдаёт 40.77 TPS, статическое декодирование с 32 шагами — всего 21.86 TPS.
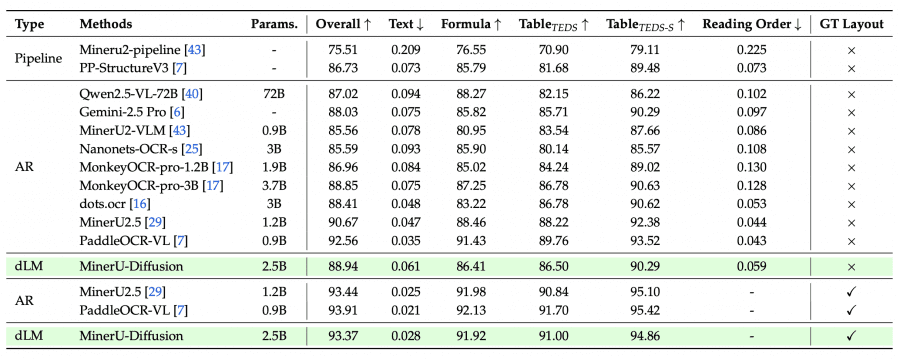
MinerU2.5 — это 1.2B AR-модель с двухэтапной стратегией: сначала анализ разметки на уменьшенном изображении, потом распознавание фрагментов в нативном разрешении. Она набирает 90.67 Overall на OmniDocBench без подсказки о разметке и 93.44 с подсказкой. MinerU-Diffusion — это 2.5B диффузионная модель с теми же задачами, но принципиально другим декодером. Без подсказки о разметке она набирает 88.94 Overall — чуть хуже MinerU2.5. С подсказкой — 93.37, практически на одном уровне. При этом на одинаковой точности MinerU-Diffusion работает в 2.1× быстрее, а на пиковой скорости — в 3.2× быстрее. Плата за это — размер модели в два раза больше (2.5B против 1.2B).
По формулам: MinerU-Diffusion набирает 91.6 на CPE (сложные печатные выражения) — хуже, чем MinerU2.5 (96.6). По таблицам: TEDS-S 88.66 на OCRBench v2 против 90.62 у MinerU2.5. Разрыв небольшой, и авторы указывают, что главный bottleneck — качество детекции разметки, а не само распознавание.
Edit distance (редакционное расстояние) — метрика, которая считает, сколько операций нужно сделать (вставить, удалить или заменить символ), чтобы превратить распознанный текст в эталонный. Чем меньше значение — тем точнее распознавание: 0.0 означает идеальное совпадение, 1.0 — полное несовпадение.
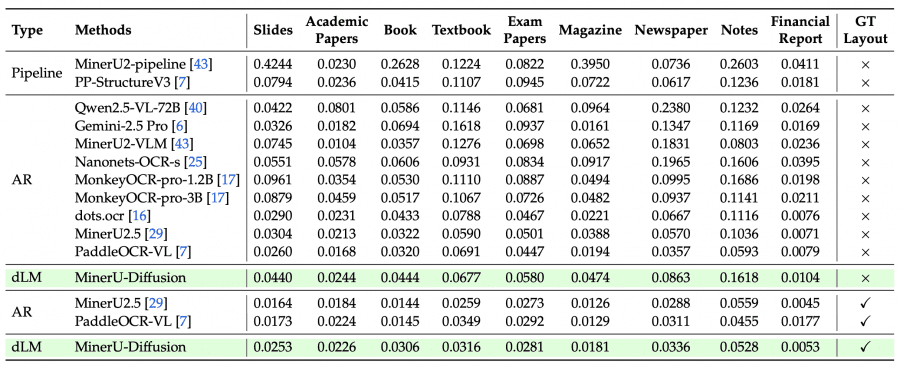
В разбивке по типам страниц видна более детальная картина. MinerU-Diffusion особенно хорошо справляется с финансовыми отчётами — 0.0053 с GT Layout, лучший результат среди всех моделей. Хорошие результаты на учебниках (0.0316) и экзаменационных работах (0.0281). Слабее всего — рукописные заметки (0.1618 без GT Layout) и слайды (0.0440): именно там нестандартная верстка требует точной детекции разметки, которая пока остаётся главным узким местом.
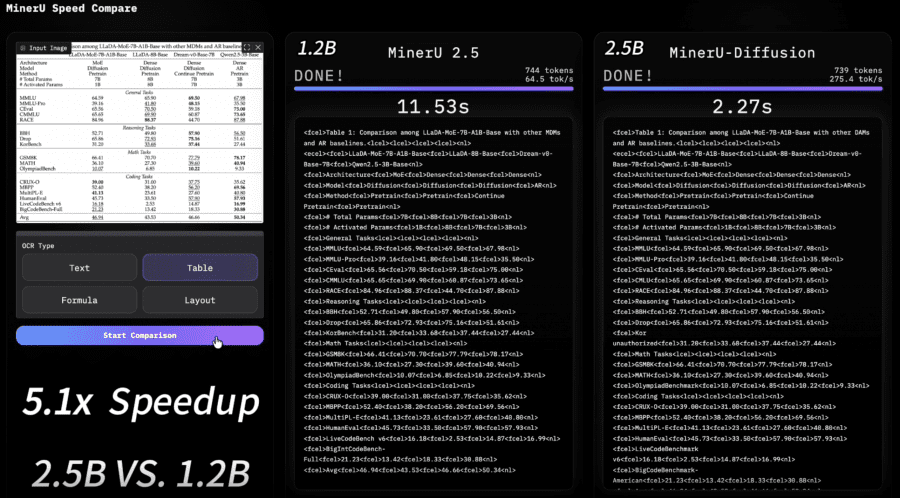
Чтобы понять разницу в скорости на практике, возьмём конкретный пример — пейпер MinerU-Diffusion, который мы сейчас разбираем: 33 страницы плотного академического текста с формулами и таблицами. Академические PDF в среднем дают ~1000 токенов выхода на страницу — это отраслевой ориентир из исследования olmOCR. Для этого пейпера с его плотными формулами возьмём 1200 токенов на страницу, итого ~39 600 токенов.
При 52 TPS (MinerU2.5) парсинг занял бы ~762 секунды, то есть около 12.7 минуты. При 108.9 TPS (MinerU-Diffusion, τ = 0.95) — ~364 секунды, около 6 минут. При пиковых 164.8 TPS (τ = 0.6) — ~240 секунд, около 4 минут. Разница между MinerU2.5 и MinerU-Diffusion на рабочем пороге составляет ~109% — MinerU2.5 потратила бы вдвое больше времени. Это всего лишь оценка — реальные цифры зависят от конкретной реализации и железа.
Итог
MinerU-Diffusion — первая диффузионная VLM, которая на реальных бенчмарках OCR конкурирует с лучшими авторегрессивными моделями и при этом значительно быстрее. По сравнению с MinerU2.5 новая модель больше по размеру и немного хуже в абсолютных цифрах точности, но устойчивее к смысловым нарушениям в документе — что подтверждает Semantic Shuffle — и быстрее при высокой нагрузке. Авторы считают диффузионный подход принципиально более подходящим для OCR: текст в документе — это детерминированное отображение визуального контента, а не вероятностная языковая генерация.





