
Команда исследователей OpenBMB представила MiniCPM4 — высокоэффективную языковую модель, разработанную специально для локальных устройств. MiniCPM4-8B достигает сопоставимой с Qwen3-8B производительности (81.13 против 80.55), при этом для обучения требуется в 4.5 раза меньше токенов: 8 триллионов против 36. На локальных устройствах MiniCPM4 работает в 7 раз быстрее Qwen3-8B при генерации ответов для 128K-токенных последовательностей. Эффективность достигается за счет улучшений в четырех ключевых направлениях: обучаемого разреженного внимания InfLLM v2, фильтрации данных UltraClean, оптимизированных алгоритмов обучения ModelTunnel v2 и фреймворка инференса CPM.cu. Модели MiniCPM0.5B и MiniCPM8B выпущены под лицензией Apache 2.0 и доступны на GitHub, а веса выложены на Hugging Face.
Архитектура модели
Разработчики MiniCPM4 применили системный подход, внедрив инновации в четырех критических областях. Архитектура модели получила новый механизм InfLLM v2 — обучаемое разреженное внимание, которое ускоряет как предварительное заполнение (prefilling), так и декодирование для длинных контекстов. Система использует семантические ядра размером 32 токена с шагом 16 для динамического выбора релевантных блоков ключ-значение, достигая 81% разреженности внимания без потери производительности.

Улучшение в обработке тренировочных данных реализована через UltraClean — стратегию фильтрации, сокращающую затраты верификации с 1,200 до 110 GPU-часов. Система использует предобученную 1B модель для оценки качества данных через двухэтапный процесс постепенного снижения скорости обучения, классификатор FastText обрабатывает 15 триллионов токенов за 1,000 CPU-против 6,000 GPU-часов у традиционных подходов. UltraChat v2 дополняет систему датасетом для контролируемого дообучения, включающим данные для интенсивного использования знаний, интенсивного рассуждения, следования инструкциям, длинного контекста и использования инструментов
Алгоритмы обучения были улучшены через ModelTunnel v2, который использует ScalingBench как индикатор производительности, устанавливая сигмоидную связь между функцией потерь и качеством выполнения последующих задач. Поблочное развертывание для сбалансированного обучения с подкреплением обеспечивает 60% снижение времени сэмплирования.

Фреймворк инференса CPM.cu интегрирующет разреженное внимание, квантизацию модели и спекулятивную выборку. FR-Spec сокращает словарь на 75% для ускорения черновой генерации, P-GPTQ обеспечивает квантизацию с учетом префикса, а ArkInfer поддерживает кросс-платформенное развертывание.
Результаты
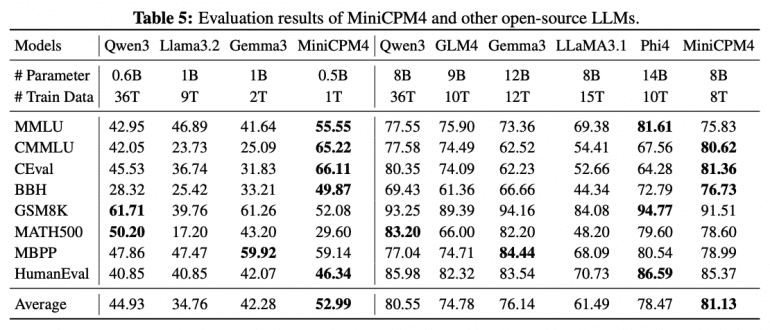
Экспериментальные результаты убедительно демонстрируют эффективность подхода. MiniCPM4-0.5B достигает 52.99 среднего балла против 44.93 у Qwen3-0.6B, в то время как MiniCPM4-8B показывает 81.13 балла против 80.55 у Qwen3-8B. Революционной представляется эффективность обучения: MiniCPM4 достигает сопоставимой производительности, используя всего 8 триллионов токенов против 36 триллионов у Qwen3-8B — это составляет лишь 22% от исходного объема данных.
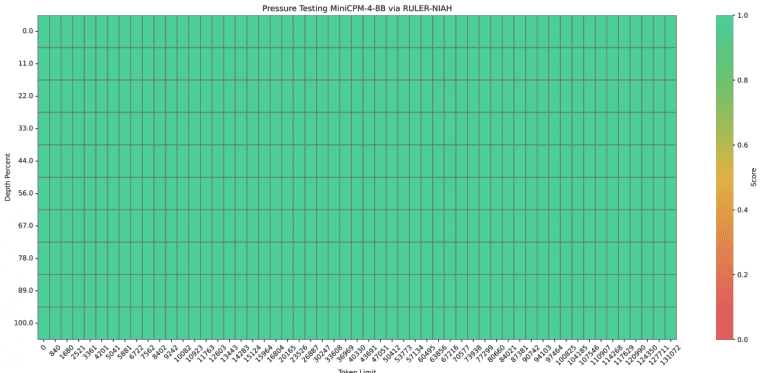
Производительность inference демонстрирует впечатляющие результаты. На платформе Jetson AGX Orin при обработке 128K контекста MiniCPM4 обеспечивает семикратное ускорение относительно Qwen3-8B. Система успешно справляется с экстремально длинными контекстами, достигая 100% точности в тесте RULER-NIAH при обработке до 128K токенов с экстраполяцией от базовых 32K.
Реальные применения
Практическая ценность MiniCPM4 подтверждается через специализированные модели. MiniCPM4-Survey для генерации научных обзоров использует архитектуру Plan-Retrieve-Write, достигая Content Quality 3.50 и рекордного показателя Fact Score 68.73, превосходя даже OpenAI Deep Research по фактуальным метрикам.
MiniCPM4-MCP адаптирована для работы с Model Context Protocol и демонстрирует выдающиеся результаты:
— точность для имен функций: 88.3%;
— точность для имен параметров: 76.1%.
Модель была обучена на 140,000 примеров данных для вызова инструментов через протокол MCP и превосходит базовую модель Qwen3-8B по всем ключевым метрикам. Система поддерживает совместимость с 16 различными MCP-серверами, включая Airbnb, GitHub, Slack, PPT и Calculator, обеспечивая широкую интеграцию с существующими инструментами разработки.
MiniCPM4 выпускается в двух конфигурациях с 0.5B и 8B параметров, обеспечивая оптимальное развертывание на ресурсо-ограниченных устройствах. Исследование демонстрирует возможность создания высокоэффективных языковых моделей через комплексную оптимизацию архитектуры, данных, алгоритмов и систем вывода, открывая перспективы доступного искусственного интеллекта.





