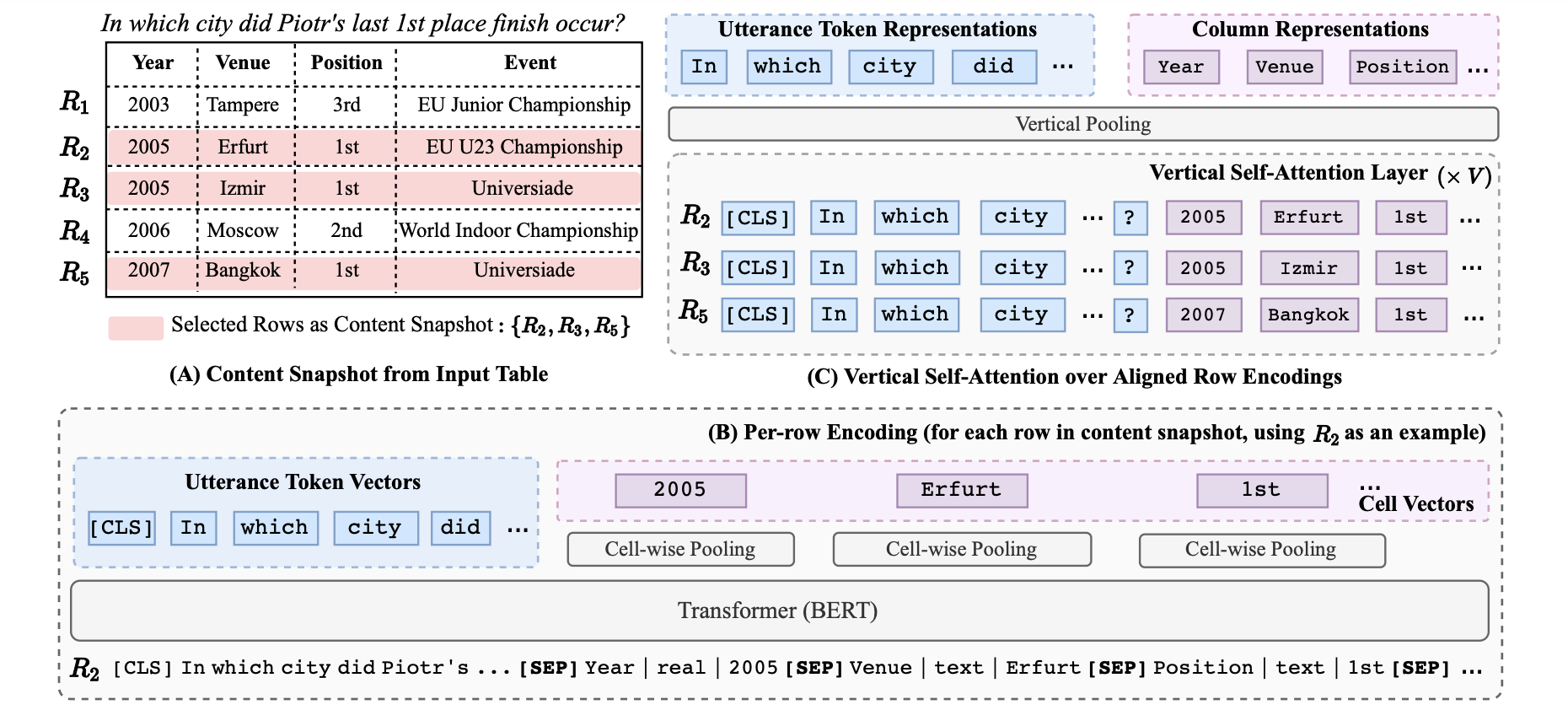
TaBERT — это нейросеть, которая переводит запросы данных с естественного языка на SQL. В основе модели лежит трансформер-архитектура BERT, которая является state-of-the-art в обработке естественного языка.
TaBERT предобучили на задаче представления предложений на естественном языке и табличных данных. Такие представления полезны для задач понимания одновременно естественного языка и баз данных. Например, вопрос “У какой страны самый высокий ВВП?” соотнесется с SQL-запросом, который извлечет из базы ответ на этот вопрос. Исследователи заявляют, что TaBERT — это первый случай предобучения на данных одновременно из структурированной и неструктурированной областей.
Процесс обучения
Нейросеть обучили на корпусе из 26 миллионов таблиц и соответствующих им предложениях на английском. При обучении на вход модель принимает подтаблицы и те предложения на английском, которые лучше всего описывают содержание подтаблиц.
Предыдущие предобученные языковые модели обычно обучались исключительно на текстах на естественном языке, написанных в свободной форме. Несмотря на то, что такие модели полезны для задач выявления смыслов из текстов на естественном языке, они неприменимы для QA-системы по базе данных.
Проверка работы модели
Тестировали модель на двух задачах:
- Задача перевода текста в SQL (данные размечены);
- Парсинг данных из датасета WikiTableQuestions (данные частично размечены)
Задача с частичной разметкой значительно сложнее полностью supervised задачи из-за того, что парсер не имеет доступа к правильному запросу. Этот запрос ищется в большом пространстве запросов. Результаты тестов показали, что TaBERT обходит существующие state-of-the-art подходы.
