
OpenAI опубликовали DALL-E — нейросетевую модель для генерации изображения по текстовому описанию. Архитектура DALL-E основывается на GPT-3, Transformer генеративной модели от OpenAI. Модель принимает на вход предложение с описанием целевого изображения и референсное изображение. На выходе модель отдаёт сгенерированное в соответствии с описанием изображение.
Подробнее про модель
DALL-E — это языковая модель, которая одновременно принимает на вход текстовое описание и изображение в формате последовательности токенов. Модель последовательно генерирует токены один за другим. Согласно исследователям, идея основывалась на успехе GPT-3 для задач обработки естественного языка и на успехе ImageGPT для задач компьютерного зрения.
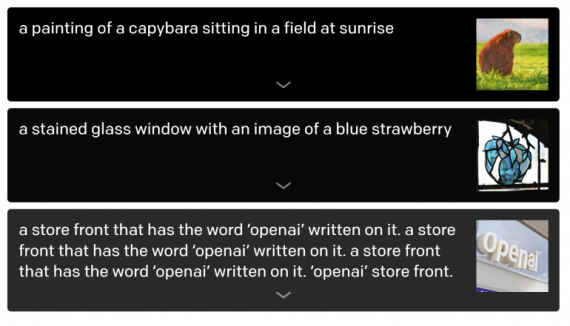
Исследователи проанализировали возможности модели генерировать реалистичные изображения с учётом описания. Модель тестировали на таких задачах, как рисование нескольких объектов, выучивание перспективы и 3D, разделение внутреннего и внешнего, контекстных деталей. Внизу — часть примеров того, какие изображения модель генерирует по запросу.
Новая модель показывает, что Transformer модели находят применение в задачах перевода текста в изображение. DALL-E состояла из 12 миллиардов параметров и выучивала корреляции между визуальными частями в языке.
Детали архитектуры и экспериментов доступны в официальном репозитории на GitHub.
