Switch Transformers — это архитектура Transformer-модели с триллионом параметров. Модель разрабатывали в Google Brain.
MoE модели с набором экспертов
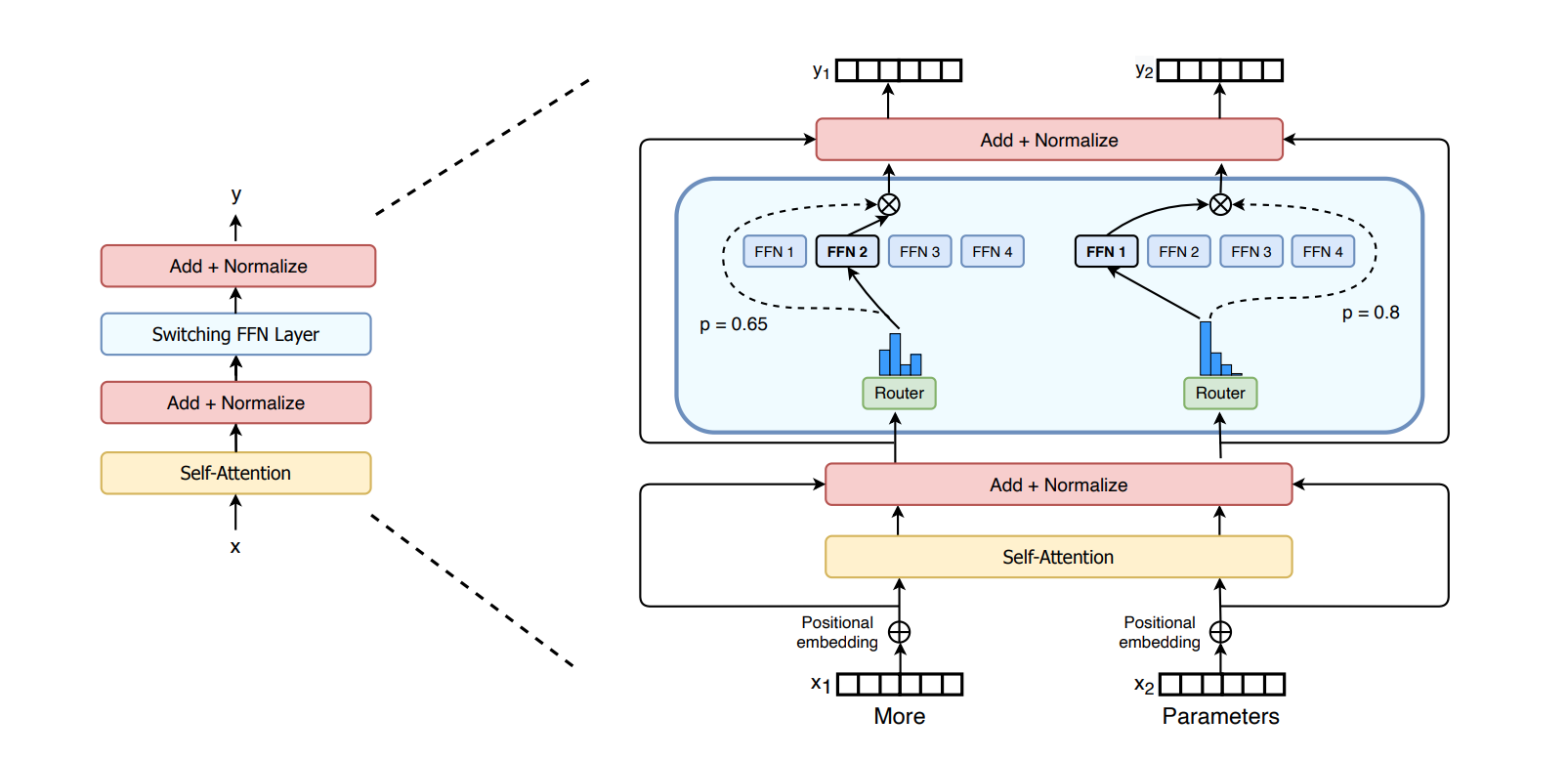
В глубоком обучении модели обычно переиспользуют одни и те же параметры для всех входных данных. Модели с набором экспертов (Mixture of Experts), в свою очередь, отбирают разные параметры для каждого входного объекта данных. Результатом является разреженно активированная модель с большим количеством параметров, но постоянными вычислительными затратами. Несмотря на успехи MoE моделей, основными их ограничениями являлись вычислительная сложность и нестабильность обучения. Исследователи из Google Brain обходят эти ограничения и предлагают архитектуру Switch Transformer. Исследователи упростили алгоритм маршрутизации в MoE и разработали улучшенные модели с уменьшенными затратами на вычисления и передачу параметров. Предложенные методы обучения позволяют избежать нестабильности обучения.
Подробности архитектуры
Архитектура моделей базируется на T5-Base и T5-Large. Switch Transformers в 7 раз быстрее предобучаются при тех же вычислительных ресурсах. Эти улучшения распространяются на мультилингвальный формат обучения. В этом случае предложенную архитектуру сравнивали с mT5-Base на 101 языках. Самая большая версия модели с триллионом параметров обучалась на датасете “Colossal Clean Crawled Corpus” в 4 раза быстрее, чем T5-XXL.
В Switch Transformer модифицировали блок с энкодером. Полносвязную сеть (FFN) заменили на разреженный слой Switch FFN. Слой работает независимо на токенах последовательности.
