Исследователи из Fudan University и StepFun опубликовали PixelSmile — диффузионную модель для точного редактирования мимики на портретах и аниме-изображениях. Вместо обучения на дискретных метках, например, «страх/не страх», модель использует непрерывные числовые оценки интенсивности эмоций и симметричное контрастное обучение (symmetric contrastive learning), благодаря которому модель различает похожие эмоции в обе стороны: если страх отличается от удивления, то и удивление должно отличаться от страха. PixelSmile не просто добавляет эмоцию, но и плавно управляет степенью её выраженности. Проект полностью открытый: код опубликован на GitHub, веса на Hugging Face под лицензией Apache 2.0, попробовать модель можно в онлайн-демо.
Проблемы существующих подходов
Человеческое лицо устроено так, что злость и отвращение часто выглядят очень похоже: нахмуренные брови, напряжённый взгляд, общее выражение недовольства. Если обучать генеративную модель на бинарных метках, она получает противоречивые примеры, и её латентное пространство запутывается — при попытке сгенерировать злость модель частично генерирует и отвращение тоже.
Это называется семантическим перекрытием или запутанностью признаков. По сути, в пространстве признаков соседние эмоции лежат слишком близко и не разделены чёткой границей. Авторы подтвердили это экспериментально: люди-аннотаторы, классификаторы и генеративные модели систематически путают одни и те же пары эмоций. При этом нейросеть-классификатор ставит фотографии удивлённого человека оценку страха 0.95, то есть с уверенностью принимает удивлённого человека за испуганного.
Датасет FFE
Первый шаг к улучшению существующих методов, предложенный исследователями — заменить дискретные метки на числовые векторы. Для этого авторы создали датасет FFE (Flex Facial Expression), который содержит 60 000 изображений в двух доменах: реальные портреты и аниме-персонажи. Каждому изображению вместо одной метки присвоен 12-мерный вектор оценок интенсивности эмоций — по одному числу от 0 до 1 на каждую из 12 эмоций. Например, фотография может получить «радость» 0.85, «уверенность» 0.55 и близко к нулю по всем остальным категориям.
Построение датасета шло в четыре этапа: сбор базовых идентичностей (около 6 000 реальных портретов и 6 000 аниме-персонажей из 207 аниме-произведений), составление библиотеки текстовых промптов для 12 эмоций, генерация изображений с разными интенсивностями с помощью редактирующей модели Nano Banana Pro, и наконец — автоматическая разметка с помощью Gemini 3 Pro с частичной проверкой людьми-аннотаторами. Это позволило получить непрерывные мягкие метки (continuous soft labels), которые честно отражают семантическое перекрытие между эмоциями, а не скрывают его.
Помимо датасета, авторы создали бенчмарк FFE-Bench с четырьмя метриками:
- mSCR (Mean Structural Confusion Rate, средний уровень семантической спутанности) — чем ниже, тем лучше модель разделяет похожие эмоции;
- HES (Harmonic Editing Score, гармонический балл редактирования) — оценка, которая штрафует модель, если та хорошо меняет выражение, но портит внешность человека, или наоборот — хорошо сохраняет лицо, но почти не меняет эмоцию. Высокий балл только при одновременно хорошем результате по обоим критериям.;
- CLS (Control Linearity Score, оценка линейности управления) — корреляция Пирсона между заданным коэффициентом интенсивности α и реально предсказанной интенсивностью: чем выше, тем более предсказуемо ведёт себя модель;
- Acc — доля изображений, где предсказанная доминантная эмоция совпала с целевой.
FFE-Bench содержит 198 задач для оценки (98 реальных портретов и 100 аниме), доступен на Hugging Face. Код для запуска оценки будет опубликован в репозитории на GitHub.
Как работает PixelSmile
PixelSmile построена на Qwen-Image-Edit-2511 — открытой диффузионной модели от Alibaba для редактирования изображений по текстовым инструкциям. На вход подаётся одно RGB-изображение с лицом и текстовый промпт с целевой эмоцией. На выход — отредактированное изображение того же разрешения. Референсные изображения не нужны — всё управление через коэффициент интенсивности α.
Архитектура строится поверх предобученного Multi-Modal Diffusion Transformer (MMDiT) с LoRA. Ключевая идея — в том, как именно PixelSmile управляет интенсивностью эмоции во время инференса и как обучается на семантически близких эмоциях.
Интерполяция в текстовом латентном пространстве. Во время инференса не нужны референсные изображения. Берётся нейтральный текстовый промпт и промпт с целевой эмоцией, оба прогоняются через энкодер — получаются два эмбеддинга. Дальше строится линейная интерполяция между ними с коэффициентом α от 0 до 1: при α=0 получаем нейтральное лицо, при α=1 — максимальную интенсивность. При α > 1 можно получить ещё более выраженную эмоцию, и авторы показывают, что это работает без потери структурной согласованности.
Полностью симметричное совместное обучение. Это главное техническое нововведение. Обычно контрастивное обучение (contrastive learning) несимметрично: берём пример A как «якорь», B — как позитивный пример, C — как негативный. Но если делать так только в одну сторону для пары «страх/удивление», модель будет по-разному обрабатывать эти эмоции. Авторы применяют обучение сразу в обе стороны: в одном прогоне страх — позитивный, удивление — негативный; в следующем — наоборот. Это убирает направленную асимметрию и заставляет модель одинаково чётко разделять обе эмоции.
Полная функция потерь состоит из трёх компонент: flow-matching loss (согласует визуальную интенсивность с коэффициентом α из непрерывных аннотаций), симметричный контрастивный loss (разводит семантически близкие эмоции в пространстве признаков CLIP-энкодера), и identity loss на основе ArcFace (не даёт модели «сползти» к другой внешности при сильном редактировании).
Что показали эксперименты
Все количественные результаты получены на FFE-Bench. Авторы сравнивали PixelSmile с двумя группами бейзлайнов. Первая группа — универсальные ИИ-редакторы: Nano Banana Pro, GPT-Image-1.5, Seedream-4.5 (закрытые) и Qwen-Image-Edit, FLUX-Klein, LongCat (открытые). Вторая группа — методы для линейного контроля атрибутов: K-Slider, SliderEdit, ConceptSlider, AttributeControl.
По точности редактирования шести базовых эмоций PixelSmile набирает 0.8627 — лучший результат среди всех моделей, выше Nano Banana Pro (0.8431) и GPT-Image (0.8039). Но самый показательный результат — по метрике семантической спутанности mSCR: PixelSmile достигает 0.0550, тогда как GPT-Image — 0.1107, Nano Banana Pro — 0.1754, а большинство других моделей превышают 0.2000. Значение mSCR, близкое к 0.5, означает, что модель фактически сводит семантически близкие эмоции к одной эмоции — то есть вообще не различает их.
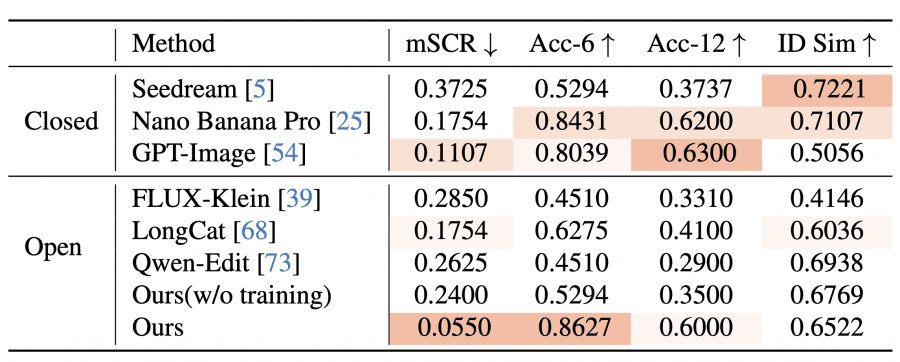
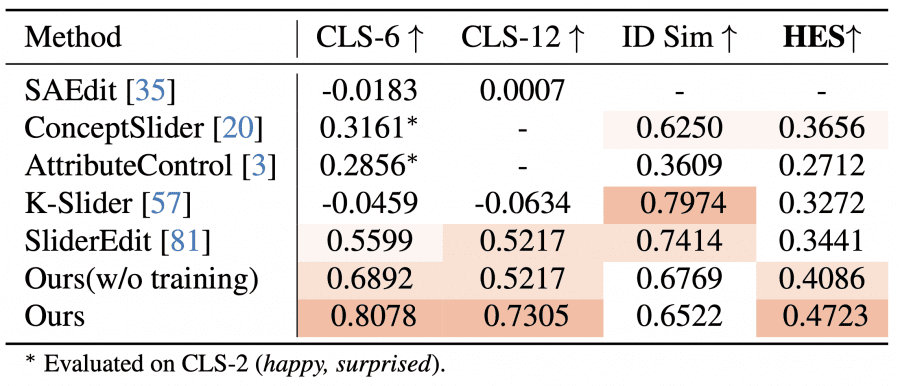
По сравнению с методами линейного контроля PixelSmile набирает CLS-6 = 0.8078 и HES = 0.4723 — снова лучший результат. Важный нюанс про конкурентов: K-Slider имеет отрицательный CLS, то есть интенсивность не растёт, а хаотично меняется при увеличении α. SliderEdit резко теряет сходство с оригиналом (ID similarity падает до ~0.4), когда эмоция достигает средней интенсивности. PixelSmile, напротив, удерживает ID similarity в диапазоне 0.6–0.7 при expression score до ~0.8 — что соответствует реалистичному диапазону, описанному в литературе.
Смешивание эмоций как побочный эффект
Поскольку модель обучена управлять интенсивностью каждой из 12 эмоций по отдельности, её можно попросить одновременно двигаться в сторону двух разных эмоций — и посмотреть, что получится. Авторы перебрали все 15 попарных комбинаций шести базовых эмоций. В 9 случаях из 15 результат выглядел осмысленно — например, «счастье + удивление» даёт что-то вроде восторженной радости, а «грусть + отвращение» — брезгливое уныние. Оставшиеся 6 комбинаций либо схлопывались в одну из эмоций (страх + удивление слишком похожи, чтобы смешаться), либо давали физически невозможное выражение лица — например, злость и счастье одновременно. Это говорит о том, что модель не просто выучила шаблоны «как выглядит злость», а действительно поняла, как эмоции соотносятся друг с другом в пространстве человеческой мимики.
Пользовательское исследование
В пользовательском исследовании 10 обученных аннотаторов оценивали три метода: PixelSmile, K-Slider и SliderEdit. Оценивалось два критерия — непрерывность изменений и сохранность личности, по шкале от 1 до 5. PixelSmile получил (4.48, 3.80) — наилучший баланс. K-Slider — (1.36, 4.06): личность сохраняет хорошо, но изменения почти не заметны. SliderEdit — (3.16, 1.14): эмоции меняет, но личность сильно искажает. Это совпадает с автоматическими метриками и подтверждает, что HES как метрика работает корректно.
Как запустить
PixelSmile строится поверх Qwen-Image-Edit-2511 — открытой диффузионной модели от Alibaba для редактирования изображений по текстовым инструкциям. Это мультимодальный диффузионный трансформер (MMDiT), который принимает исходное изображение и текстовый промпт и возвращает отредактированное изображение. В версии 2511 улучшена консистентность персонажей, снижен image drift и добавлена встроенная поддержка LoRA. Модель выпущена под лицензией Apache 2.0 и загружается отдельно с Hugging Face. Поверх неё накладывается LoRA-адаптер PixelSmile — файл PixelSmile-preview.safetensors весом ~4 МБ, который и отвечает за управляемое редактирование мимики.
На вход подаётся одно RGB-изображение с лицом и текстовый промпт с целевой эмоцией. На выход — одно или несколько изображений (по числу заданных значений α) того же разрешения с изменённым выражением лица. Референсные изображения не нужны.
Установка (Python 3.10, conda):
git clone https://github.com/Ammmob/PixelSmile.git
cd PixelSmile
conda create -n pixelsmile python=3.10
conda activate pixelsmile
pip install -r requirements.txt
bash scripts/patch_qwen_diffusers.shПоследняя команда — обязательный патч для исправления бага в текущей версии библиотеки diffusers при работе с Qwen-Image-Edit. Без него инференс не запустится.
Поддерживается два способа запуска. Первый — с дефолтными аргументами, которые можно отредактировать прямо в скрипте:
bash scripts/run_infer.shВторой — с явными аргументами из командной строки:
bash scripts/run_infer.sh
--image-path /path/to/input.jpg
--output-dir /path/to/output
--model-path /path/to/Qwen-Image-Edit-2511
--lora-path /path/to/PixelSmile.safetensors
--expression happy
--scales 0 0.5 1.0 1.5
--seed 42Параметр --scales задаёт значения коэффициента α — модель сгенерирует одно изображение для каждого значения. При α=0 лицо остаётся нейтральным, при α=1 — полное выражение, при α=1.5 эмоция усиливается сверх тренировочного диапазона. По умолчанию используется 50 шагов инференса (inference steps) — это видно в онлайн-демо. Поддерживаются все 12 выражений: happy, sad, angry, surprised, fear, disgust, anxious, contempt, confident, shy, sleepy, confused.
На момент публикации доступна preview-версия весов только для реального домена (human). Поддержка аниме и более стабильная версия анонсированы. Для обучения дополнительно нужен pip install -r requirements-train.txt и вспомогательные веса, полный список которых авторы обещают опубликовать отдельно. Обучение проводилось на 4 × NVIDIA H200.
Итог
PixelSmile решает конкретную и давнюю проблему генеративных моделей: их неспособность чётко разделять семантически близкие эмоции. Переход от дискретных меток к непрерывным аффективным аннотациям плюс симметричное контрастивное обучение дают модель, которая одновременно превосходит закрытые коммерческие редакторы по точности разделения эмоций и превосходит специализированные методы линейного контроля по предсказуемости и стабильности управления.





