Алгоритмы, которые восстанавливают 3D-модели головы из плоских изображений, должны учитывать позу, освещение, эмоции, гладкие поверхности лиц, ушей, шеи и, наконец, волос. Сейчас качественная реконструкция возможна в том случае, если входные фотографии сняты в специальной откалиброванной лабораторной обстановке или полукалибровке, когда человек участвует в сеансе захвата.
Однако реконструирование 3D-модели интернет-фотографий — открытая проблема из-за высокой степени изменчивости некалиброванных изображений. Освещение, поза, камера и разрешение резко отличаются от фотографии к фотографии. В последние годы большое внимание уделяется реконструкции лиц из Интернета. Однако все face-focused методы выделяют голову с помощью фиксированной маски и фокусируются только на области лица, а не всей головы.
Предыдущие работы
Калиброванное моделирование головы достигло потрясающих результатов за последнее десятилетие. Реконструкция 3D-моделей людей из интернет-фотографий тоже достигла относительно хороших результатов.
- Shlizerman et al. показали, что можно восстановить лицо по одной фотографии в Интернете, используя шаблонную модель другого человека. Один из способов приблизиться к задаче реконструкции головы — использовать подход, основанный на моделировании.
- Hsieh et al. показал, что лицо находится в линейном пространстве с изменяемыми моделями из 200 сканов лица, голову также реконструют по этому пространству. На практике методы изменяемой модели хорошо подходят для распознавания лиц.
- Adobe Research доказала, что моделирование волос можно сделать по одной фотографии путем подбора синтетических волос из базы данных или с помощью спиралей.
State-of-the-art идея
Новая идея относится к направлению реконструкции головы непосредственно из интернет-данных. Есть коллекция фотографий, полученная путем поиска фотографий конкретного человека в Google, задача — восстановить 3D-модель головы этого человека (основное внимание все равно уделяется области лица). Если есть только одна или две фотографии, задача сильно усложняется из-за несогласованности освещения, трудности в сегментировании профиля лица из фона и проблемы с объединением изображений. Ключевой идеей является то, что с большим количеством (сотнями) фотографий проблему можно преодолеть. Для знаменитостей можно быстро получить такие коллекции.
Метод работает следующим образом: коллекция фотографий человека делится на кластеры примерно одинакового азимутального угла 3D-позы. С учетом кластеров реконструируется карта глубины фронтальной поверхности, и алгоритм постепенно увеличивает реконструкцию, оценивая поверхностные нормали для каждого кластера, а затем урезает использование граничных условий, исходящих из соседних видов. Конечный результат — сетка головы, объединяющая все фотографии.

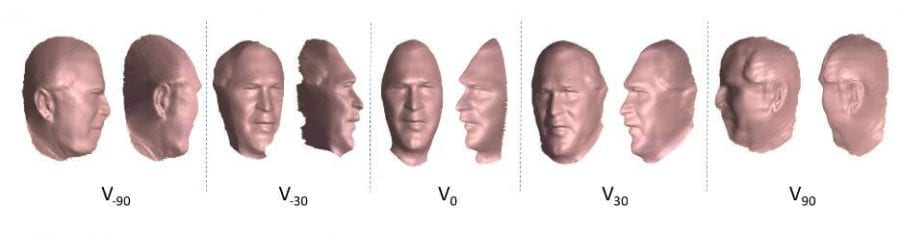
Данные фотографии делятся на кластер представлений как Vi. Фотографии в том же кластере имеют примерно одинаковые 3D-позы и азимутальный угол. Фотографии с 7 кластерами с азимутами: i = 0, -30,30, -60,60, -90,90. На рисунке 2 показаны средние значения для каждого кластера после жесткого выравнивания с использованием опорных точек (1-я строка) и после последующего выравнивания с использованием метода Collection Flow (2-й ряд), который вычисляет оптический поток для каждой кластерной фотографии в среднем по кластеру.
Инициализация мэша головы
Цель состоит в том, чтобы восстановить головную сетку M. Она начинается с оценки карты глубины и нормалей поверхности лобового кластера V0 и присваивает каждому восстановленному пикселю вершину сетки. Алгоритм выглядит следующим образом:
- Плотное 2D-выравнивание: cначала фотографии жестко выравниваются с использованием двумерных точек. Область головы, включая шею и плечо в каждом изображении, сегментируется с использованием семантической сегментации. Затем Сollection Flow запускается на всех фотографиях в V0, чтобы выровнять их со средней фотографией этого набора более точно. Трудные фотографии не влияют на метод; учитывая, что большая часть изображений хорошо сегментирована, Collection Flow будет исправлять несоответствия. Кроме того, Collection Flow помогает преодолевать различия в прическе, деформируя все фотографии до доминирующего стиля.
- Оценка нормалей поверхности: маска для лица используется для определения области лица на всех фотографиях. Фотометрическая стереосистема (PS) затем применяется к области лица выровненных по потоку фотографий. Область лица изображений расположена в матрице n × pk Q, где n — количество изображений, а pk — количество пикселей лица, определяемое матричной лицевой маской. Rank-4 PCA рассчитывается для факторизации в освещение и нормали: Q = LN. Получив оценку освещения L для каждой фотографии, вычисляют N для всех p головных пикселей, включая области уха, подбородка и волос. Два ключевых компонента, которые заставили PS работать с некалиброванными фотографиями на голове:
- Решение неоднозначности Generalized Bas-Relief (GBR) с использованием шаблона 3D-лица другого человека.
- Используя обычную оценку поверхности на пиксель, где каждая точка использует другой поднабор фотографий для оценки нормали.
- Оценка карты глубины: нормали поверхности интегрированы для создания карты глубины. Решая линейную систему уравнений, которые удовлетворяют градиентным ограничениям dz / dx = -nx / ny и dz / dy = -nx / ny, где (nx, ny, nz ) являются компонентами поверхностного нормали каждой точки. Объединяя эти ограничения, для z-значения на карте глубины:
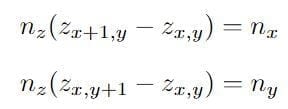
Это генерирует разреженную матрицу M размера 2p × 2p и решает:
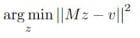
Граничный рост (Boundary-Value Growing)
Для завершения вида сбоку сетки вводится граничное значение. Начиная с фронтальной сетки V0, мы постепенно дополняем больше областей головы в порядке V30, V60, V90 и V-30, V-60, V-90 с двумя дополнительными ограничениями клавиш.
- Восстановление неоднозначности: вместо того, чтобы восстанавливать неоднозначность А, возникающую из Q = LA ^ (- 1) AN с использованием шаблонной модели, используется уже вычисленный соседний кластер, т. Е. Для V ± 30 используется N (ноль) для V ± 60, N — 30, а для V — 90 — N — 60. В частности, он оценивает внеплановую позу от 3D-начальной сетки V0 до среднего изображения кластера позы V30.
- Ограничение глубины: в дополнение к ограничениям градиента также изменяются граничные ограничения. Пусть Ω0 — граница D’0. Тогда часть Ω0, которая пересекает маску D30, будет иметь одинаковые значения глубины: D30 (Ω0) = D’0 (Ω0). Как с граничными ограничениями, так и с ограничениями градиента функция оптимизации может быть записана как:
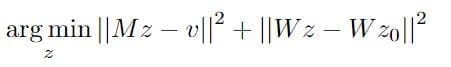
После каждого шага реконструкции глубины (0,30, 60, … градусов) расчетная глубина проецируется в головную сетку. Посредством этого процесса, голова постепенно заполняется путем сбора вершин из всех фотографий.
Результат
Ниже показано изображение реконструкции, которое позднее было объединено с одной сеткой. Например, ухо в 90 и -90 просмотрах хорошо реконструируется, в то время как другие виды не могут восстановить ухо.
На рисунке 5 показано, как два ключевых ограничения хорошо работают в процессе восстановления. Без правильных опорных нормалей и ограничений глубины реконструированная форма плоская, а профиль лицевой области размыт, что увеличило сложность выравнивания ее назад до фронтального вида.
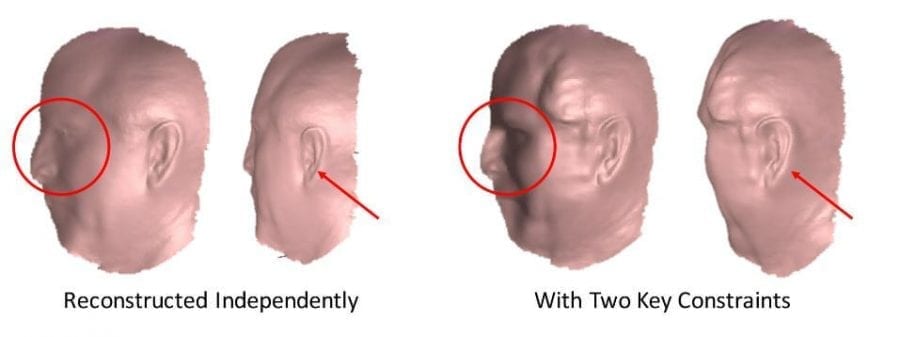
Левые две фигуры показывают модели без двух ключевых ограничений восстановленные независимо. Правые две фигуры показывают два результата с двумя ключевыми ограничениями. На рисунке 6 показан результат реконструкции для 4 предметов; каждая сетка поворачивается до пяти разных точек зрения.

Сравнение с другими моделями
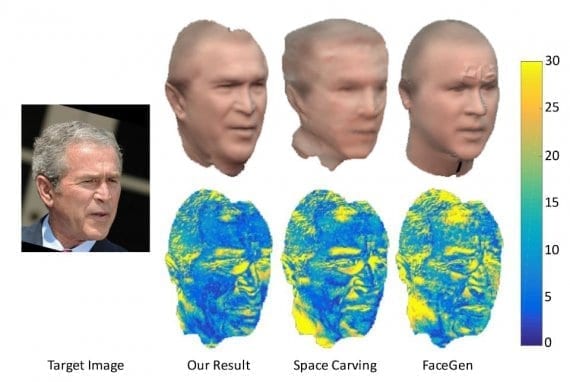
На рисунке 7 показано сравнение с программным обеспечением FaceGen, которое реализует подход изменяемой модели.
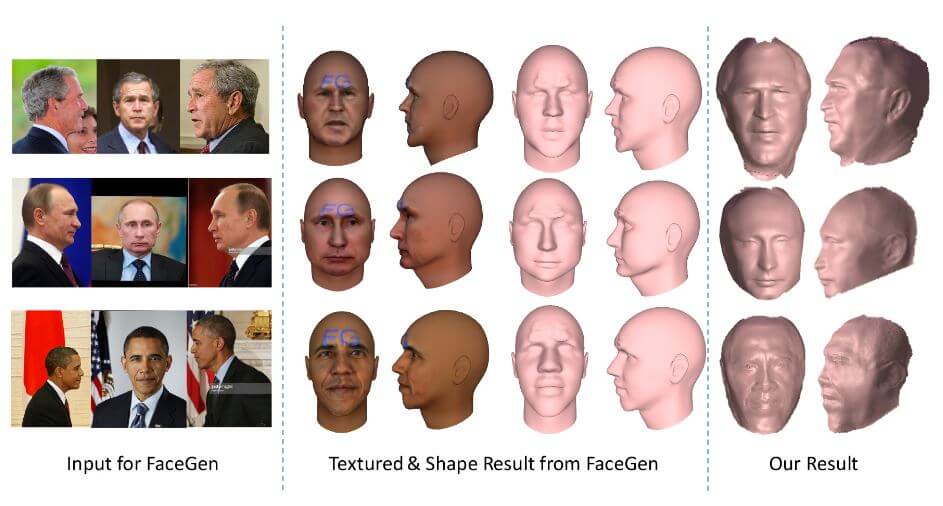
Для количественного сравнения для каждого человека ошибка репроцессинга рассчитывается с помощью трех методов (предлагаемый подход, Space Carving и FaceGen) до 600 фотографий в разных позах и вариациях освещения. Трехмерная форма получена от каждого метода реконструкции.
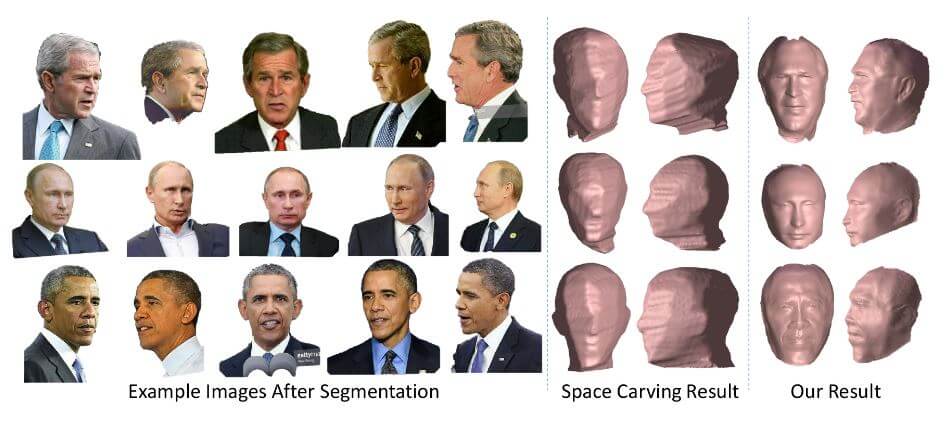
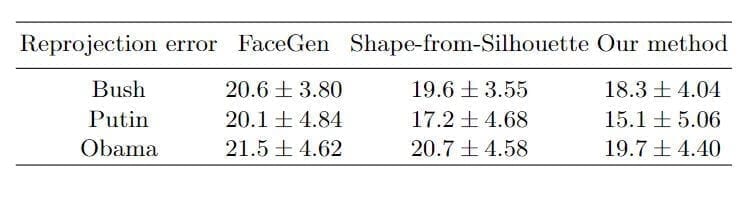
Карта ошибок изображения показана на рисунке 8. Обратите внимание, что формы из FaceGen и Space Carving могут выглядеть хорошо с фронтальной точки зрения, но они неверны при повороте в целевое представление. Посмотрите, как отличаются уши на рисунке.
Вывод
Подход показывает, что можно восстановить модель головы из интернет-фотографий. Однако этот подход имеет ряд ограничений.
Во-первых, он предполагает модель Ламберта для отражения поверхности. Хотя это хорошо работает, учет зеркал должен улучшить результаты.
Во-вторых, опорные точки для боковых представлений были помечены вручную.
В-третьих, полная модель не построена; верхняя часть головы отсутствует. Чтобы решить эту проблему, необходимо добавить дополнительные фотографии с разными углами обзора, а не просто сфокусироваться на изменении азимута.