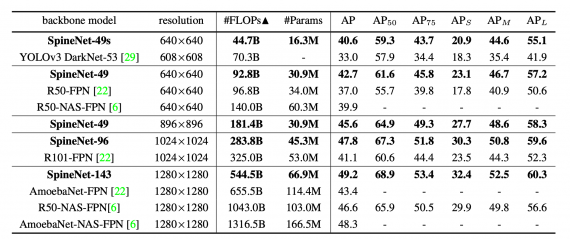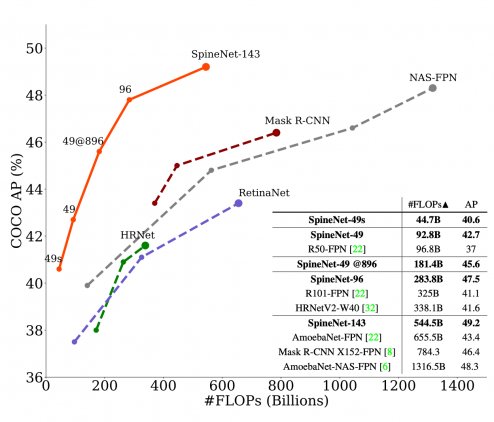
SpineNet — это backbone нейросетевая архитектура для задачи распознавания объекта. Разработкой модели занимались исследователи из Google Research. Модель обходит state-of-the-art подходы на задаче распознавания объектов на данных COCO. При этом SpineNet производит на 60% меньше вычислений и обходит ResNet-FPN на 6% по AP. Предложенную архитектуру также используют для классификации. SpineNet обходит state-of-the-art на 6% в точности на датасете iNaturalist.
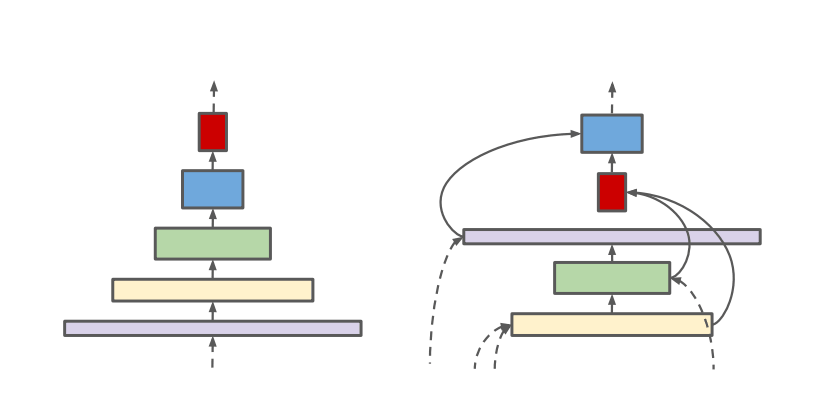
Сверточные нейросети обычно кодируют входное изображение в последовательность промежуточных признаков меньшей размерности. Такой подход работает для задачи классификации изображений, но плохо работает для задачи распознавания объектов. Чтобы решить это ограничение, предложили использовать архитектуры с кодировщиком и декодировщиком. Декодировщик применяется поверх backbone модели, которая разработана для задачи классификации. Исследователи заявляют, что такая архитектура неэффективна для генерации признаков разных масштабов, потому что в backbone модели масштаб изображения уменьшается.
Предложенная backbone модель SpineNet позволяет выучивать разномасштабные признаки из-за сверточных слоев смешанных размеров. Размеры слоев подбирались с помощью нейронного поиска архитектур (NAS).
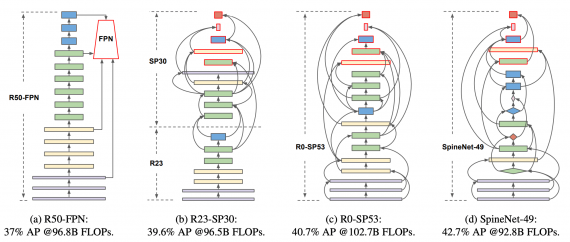
Тестирование работы модели
Исследователи сравнили SpineNet с конкурирующими backbones архитектурами вместе с RetinaNet на задаче распознавания объектов. Ниже видно, что использование SpineNet в качестве базовой модели в архитектуре дает прирост в точности (AP). При этом на обучение модели требуется меньше вычислительных ресурсов.