Исследователи из Shanghai AI Laboratory и Fudan University опубликовали Yume1.5 — модель для генерации интерактивных виртуальных миров, которыми можно управлять прямо с клавиатуры. В отличие от обычной генерации видео, здесь можно двигаться по виртуальному пространству клавишами WASD (как в играх) и поворачивать камеру стрелками. Модель создает бесконечные видео-миры из одного изображения или текстового описания. Главное — скорость работы 12 кадров в секунду на одной видеокарте A100, что в 70 раз быстрее предыдущих решений. Код для запуска модели опубликован на Github, веса модели обещают выложить позже.
Существующие решения и их проблемы
До Yume1.5 уже существовали попытки создать интерактивные миры. Genie от DeepMind генерирует 2D-миры с управлением действиями, GAIA-1 от Wayve специализируется на реалистичных симуляциях вождения, а WORLDMEM использует память для поддержания согласованности в длинных видео. Matrix-Game от Skywork AI создает интерактивные игровые миры с клавиатурным управлением, а оригинальный Yume также поддерживает управление камерой.
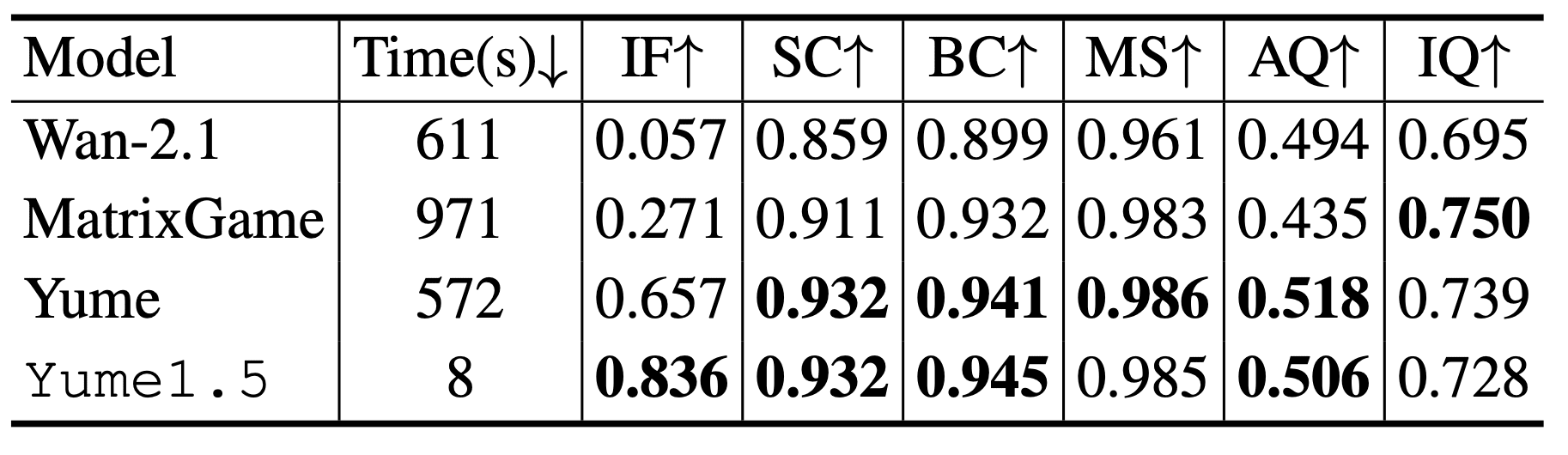
Проблема в том, что эти модели либо слишком медленные, либо плохо справляются с реалистичными сценами. Wan-2.1 генерирует видео за 611 секунд с очень низкой точностью следования командам (0.057 по метрике Instruction Following). Matrix-Game работает еще медленнее — 971 секунду, хотя точность лучше (0.271). Даже предыдущая версия Yume, которая показала лучший результат по точности (0.657), требует 572 секунды на генерацию. Все эти модели используют 50 шагов диффузии, что делает их непригодными для интерактивного исследования в реальном времени.
Главные проблемы существующих подходов: обучение на игровых датасетах создает разрыв с реальными городскими сценами, высокая вычислительная стоимость препятствует генерации в реальном времени, а отсутствие текстового контроля не позволяет добавлять события в мир динамически.
Три режима работы
Yume1.5 поддерживает три способа создания миров. В режиме text-to-world модель генерирует мир из текстового описания — например, «стильная женщина идет по токийской улице с неоновыми вывесками». В режиме image-to-world она превращает статичное изображение в исследуемый мир. Третий режим — редактирование событий через текст, когда можно добавить в уже созданный мир новое событие вроде «появилось привидение». Во всех режимах управление идет через непрерывный ввод с клавиатуры — WASD двигает персонажа, стрелки управляют камерой.

Как работает TSCM
Когда модель генерирует длинное видео, количество предыдущих кадров постоянно растет, что создает огромную вычислительную нагрузку. TSCM (Temporal-Spatial-Channel Modeling) решает эту проблему через два параллельных вида сжатия. Для временно-пространственного сжатия исторические кадры прореживаются с разной степенью: недавние кадры сжимаются меньше (1, 2, 2), более старые — сильнее (1, 4, 4) и (1, 8, 8). Одновременно для канального сжатия те же кадры сжимаются до 96 каналов. Первый поток обрабатывается стандартным вниманием, второй — линейным вниманием.

Сравнение показало эффективность подхода. При генерации 18 блоков видео время инференса у TSCM стабилизируется после 8 блоков на уровне 1.5 секунд. У пространственного сжатия оно растет до 3 секунд. Полный контекст занял бы 12.41 секунд к 18-му блоку.

Ускорение через Self-Forcing
Yume1.5 использует дистилляцию для ускорения: «быстрая» модель (ученик) учится повторять траекторию «настоящей» модели (учитель) через минимизацию расхождения распределений. Ключевое отличие — модель использует свои собственные сгенерированные кадры как контекст, а не реальные данные. Это уменьшает расхождение между обучением и выводом. Результат — 4 шага вывода вместо 50 при сохранении качества.

Датасеты
Для обучения собрали три типа данных. Основной — Sekai-Real-HQ с траекториями камеры, конвертированными в команды клавиатуры. Датасет переразметили по-разному: для текст-в-видео оставили описания сцен, для изображение-в-видео создали описания событий через InternVL3-78B. Добавили 50,000 синтетических видео для сохранения общих способностей и 4,000 видео специфичных событий.
Результаты
Yume1.5 набрала 0.836 по метрике Instruction Following, значительно опережая Wan-2.1 (0.057), Matrix-Game (0.271) и Yume (0.657). При этом скорость — всего 8 секунд на тест против 572-971 у конкурентов. Для 30-секундных видео Aesthetic Score в последнем сегменте — 0.523 против 0.442 без Self-Forcing, Image Quality — 0.601 против 0.542.
Ограничения
Модель показывает артефакты: машины едут задом, персонажи ходят в обратную сторону, качество падает при высокой плотности людей. Авторы связывают это с ограниченной емкостью модели на 5 миллиардов параметров и рассматривают архитектуры Mixture-of-Experts (MoE) как решение для увеличения параметров без роста времени вывода.
Главный вывод: Yume1.5 показывает путь к созданию интерактивных виртуальных миров в реальном времени через эффективное сжатие контекста и дистилляцию. Скорость 12 fps делает технологию практически применимой для исследования виртуальных пространств.