GRF — это нейронная функция для представления и рендеринга 3D сцен любой сложности на основе 2D изображений. По количественным и качественным оценкам, GRF обходит state-of-the-art методы.

Подробнее про архитектуру подхода
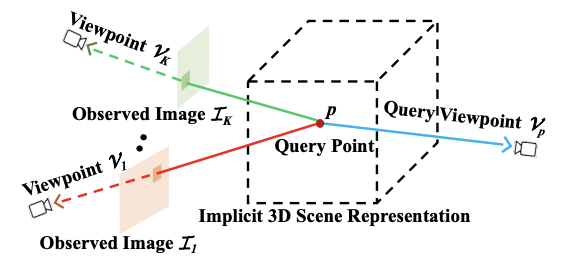
Функция моделирует 3D сцены как general radiance field, которое принимает на вход набор 2D изображений, строит внутреннее представление для каждой 3D точки сцены и рендерит внешний вид и геометрию 3D точек для любого ракурса. Ключевым преимуществом подхода является интеграция геометрии для разных ракурсов при обучении представлений. Это позволяет убедиться, что выученные представления последовательны в разных ракурсах. Кроме того, исследователи предлагают нейронный модуль для обучения признаков каждого пикселя на входных 2D изображениях.
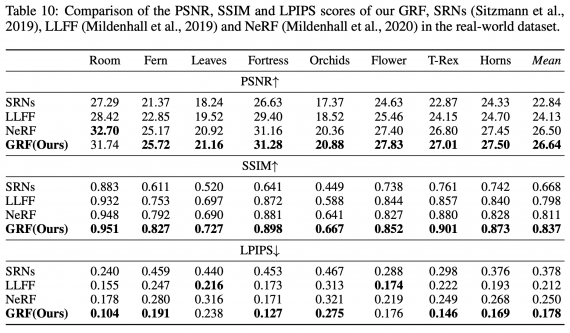
Сравнение с state-of-the-art
Исследователи сравнили предложенный GRF подход с state-of-the-art методом NeRF и целевыми данными. Ниже видно, что предложенный алгоритм выдает схожие с целевыми данными предсказания. При этом предсказания модели менее шумные, чем у NeRF.