Google представила Gemini 2.5 Flash Image aka Nano Banana — новую модель генерации изображений
26 августа 2025

Google представила Gemini 2.5 Flash Image aka Nano Banana — новую модель генерации изображений
Google представила Gemini 2.5 Flash Image (с внутренним кодовым названием nano-banana) — модель для генерации и редактирования изображений. Модель поддерживает комбинирование нескольких изображений в одно, сохраняет консистентность персонажей между генерациями,…
Реставрация старых фото онлайн: топ-8 нейросетей
25 августа 2025

Реставрация старых фото онлайн: топ-8 нейросетей
В жизни часто возникают ситуации, когда необходимо освежить старые фото: улучшить четкость, удалить царапины, желтизну и прочие следы времени. Самый легкий путь – это реставрация старых фото онлайн, то есть…
RRNCB — первый российский открытый бенчмарк для оценки RAG-моделей
25 августа 2025
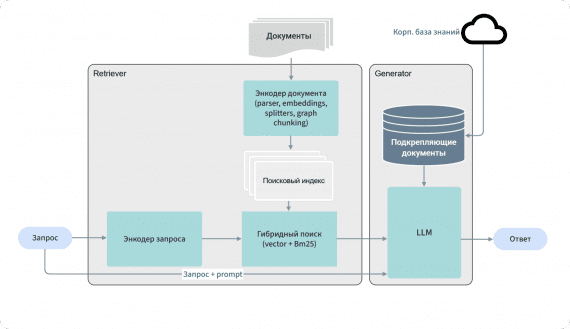
RRNCB — первый российский открытый бенчмарк для оценки RAG-моделей
RRNCB (Russian RAG Normative — Corporate Benchmark) — первый российский открытый бенчмарк для комплексной оценки RAG-моделей при работе с нормативной, правовой и технической документацией компаний. RRNCB адаптирован под специфику русскоязычных…
Nemotron Nano 2 9B: модель от NVIDIA обходит Qwen3-8B на бенчмарках, работает в 6 раз быстрее и поддерживает контекст 128k
20 августа 2025

Nemotron Nano 2 9B: модель от NVIDIA обходит Qwen3-8B на бенчмарках, работает в 6 раз быстрее и поддерживает контекст 128k
Команда исследователей NVIDIA представила Nemotron-Nano-9B-v2 — гибридную Mamba-Transformer языковую модель, которая выдает ответы в 6 раз быстрее Qwen-3-8B на задачах рассуждения, превосходя ее в точности. Модель с 9 миллиардами параметров…
Matrix-3D: открытый фреймворк для генерации всенаправленных исследуемых 3D-миров из одного изображения
14 августа 2025

Matrix-3D: открытый фреймворк для генерации всенаправленных исследуемых 3D-миров из одного изображения
Исследователи из Skywork AI, Гонконгского университета науки и технологий представили Matrix-3D — фреймворк для создания полностью исследуемых трехмерных миров из одного изображения или текстового описания. Matrix-3D решает проблему ограниченного поля…
3D-R1: открытая модель с рассуждениями для 3D-сцен превосходит современные методы на 10% на 3D-бенчмарках
6 августа 2025

3D-R1: открытая модель с рассуждениями для 3D-сцен превосходит современные методы на 10% на 3D-бенчмарках
Исследователи из Шанхайского университета инженерных наук и Пекинского университета представили 3D-R1 — новую foundation-модель, которая значительно улучшает способности к рассуждению в трёхмерных vision-language моделях (VLM). Модель демонстрирует среднее улучшение производительности…
Seed Diffusion: новый state-of-the-art в балансе скорость-качество для моделей генерации кода
6 августа 2025

Seed Diffusion: новый state-of-the-art в балансе скорость-качество для моделей генерации кода
Команда исследователей ByteDance Seed совместно с Институтом AIR Университета Цинхуа представила Seed Diffusion Preview — языковую модель на основе дискретной диффузии, демонстрирующую рекордную скорость инференса. Модель достигает 2,146 токенов в…
Gemini 2.5 Pro показала уровень золотого медалиста на Международной математической олимпиаде IMO 2025, решив 5 из 6 задач
25 июля 2025

Gemini 2.5 Pro показала уровень золотого медалиста на Международной математической олимпиаде IMO 2025, решив 5 из 6 задач
Большие языковые модели хорошо справляются с математическими бенчмарками вроде AIME, однако задачи Международной математической олимпиады (IMO) требуют глубокого понимания, креативности и формального рассуждения. Китайские исследователи использовали Google Gemini 2.5 Pro…
Show-o2: открытая мультимодальная 7B модель обходит 14B-модели на бенчмарках, используя в разы меньше данных для обучения
11 июля 2025

Show-o2: открытая мультимодальная 7B модель обходит 14B-модели на бенчмарках, используя в разы меньше данных для обучения
Исследователи из Show Lab Национального университета Сингапура и ByteDance представили Show-o2 — второе поколение мультимодальной модели, которая демонстрирует превосходные результаты в задачах понимания и генерации изображений и видео. Show-o2 использует…
Фреймворк TreeQuest: адаптивные команды LLM превосходят отдельные модели на 30%
8 июля 2025

Фреймворк TreeQuest: адаптивные команды LLM превосходят отдельные модели на 30%
Исследователи из Sakana AI представили Adaptive Branching Monte Carlo Tree Search (AB-MCTS) — революционный подход к созданию «команд мечты» из больших языковых моделей, который позволяет им динамически сотрудничать для решения…
MiniCPM4: открытая локальная модель достигает производительности Qwen3-8B при 7-кратном ускорении инференса
15 июня 2025

MiniCPM4: открытая локальная модель достигает производительности Qwen3-8B при 7-кратном ускорении инференса
Команда исследователей OpenBMB представила MiniCPM4 — высокоэффективную языковую модель, разработанную специально для локальных устройств. MiniCPM4-8B достигает сопоставимой с Qwen3-8B производительности (81.13 против 80.55), при этом для обучения требуется в 4.5…
Строгое on-policy обучение с оптимальным бейзлайном: Microsoft представила упрощенный алгоритм для RLHF
4 июня 2025
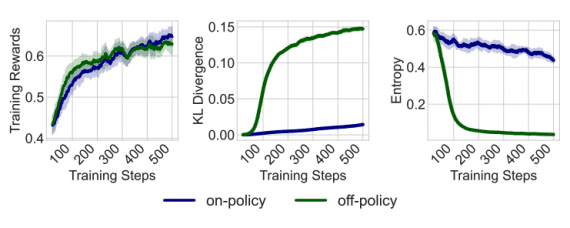
Строгое on-policy обучение с оптимальным бейзлайном: Microsoft представила упрощенный алгоритм для RLHF
Исследовательская команда Microsoft Research представила On-Policy RL with Optimal reward baseline (OPO) — упрощенный алгоритм обучения с подкреплением для выравнивания больших языковых моделей. Новый метод решает ключевые проблемы современных RLHF…
NVIDIA Canary достигла 90% точности предсказания временных меток в синхронном переводе
28 мая 2025

NVIDIA Canary достигла 90% точности предсказания временных меток в синхронном переводе
Исследовательская команда NVIDIA представила подход для генерации временных меток на уровне слов в модели синхронного перевода Canary. Точная информация о времени критически важна для создания синхронизированных субтитров. Исследователи опубликовали код…
Mistral Agents API: фреймворк для создания AI-агентов с веб-поиском, генерирующих код и изображения
28 мая 2025
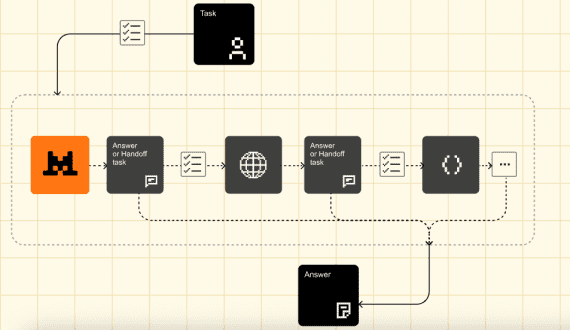
Mistral Agents API: фреймворк для создания AI-агентов с веб-поиском, генерирующих код и изображения
Французский стартап Mistral AI представил Agents API — фреймворк для создания автономных AI-агентов со встроенными коннекторами, постоянной памятью и возможностями оркестрации. Разработчики могут создавать неограниченнное число агентов и выстраивать пайплайны…
Visual-ARFT: новый метод обучения AI-агентов обходит GPT-4o в мультимодальных задачах
22 мая 2025
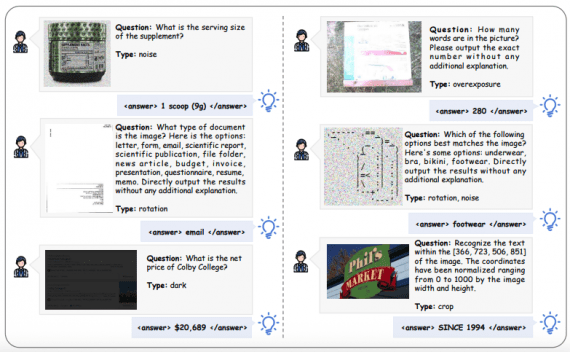
Visual-ARFT: новый метод обучения AI-агентов обходит GPT-4o в мультимодальных задачах
Исследовательская группа из Шанхайского университета Цзяо Тонг и Шанхайской лаборатории искусственного интеллекта представила Visual Agentic Reinforcement Fine-Tuning (Visual-ARFT) — новый подход к обучению крупных мультимодальных моделей агентным возможностям. Методика демонстрирует…
NVIDIA Isaac 5.0: обучение роботов с продвинутой физикой сенсоров и генерацией синтетических данных с открытым кодом
19 мая 2025

NVIDIA Isaac 5.0: обучение роботов с продвинутой физикой сенсоров и генерацией синтетических данных с открытым кодом
NVIDIA представила обновления своей экосистемы Isaac для разработки роботов на выставке COMPUTEX 2025, которые улучшают возможности генерации синтетических данных и совершенствуют тестирование моделей на всех этапах разработки. Isaac Sim 5.0:…
ZEROSEARCH: открытый фреймворк, снижающий затраты на обучение LLM поиску на 88%
9 мая 2025
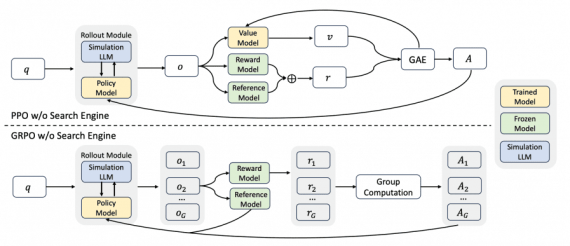
ZEROSEARCH: открытый фреймворк, снижающий затраты на обучение LLM поиску на 88%
Исследовательская команда NLP Alibaba официально открыла исходный код ZEROSEARCH, полноценного фреймворка для обучения LLM способности к поиску в интернете без использования реальных поисковых систем. ZEROSEARCH основан на ключевом наблюдении: LLM…
Phi-4-reasoning: 14B модель от Microsoft превосходит масштабные модели в задачах сложного рассуждения
4 мая 2025

Phi-4-reasoning: 14B модель от Microsoft превосходит масштабные модели в задачах сложного рассуждения
Microsoft представила модель Phi-4-reasoning с 14 миллиардами параметров, которая демонстрирует исключительную производительность на сложных задачах рассуждения, превосходя модели, превышающие её по размеру в 5-47 раз, и требуя значительно меньше вычислительных…
DeepMath-103K: датасет для обучения с подкреплением моделей рассуждения от Tencent
21 апреля 2025
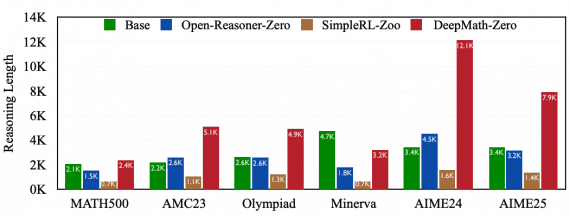
DeepMath-103K: датасет для обучения с подкреплением моделей рассуждения от Tencent
Исследователи из Tencent и Шанхайского университета Цзяо Тонг опубликовали DeepMath-103K — крупный математический датасет, созданный для разработки продвинутых моделей рассуждения с помощью обучения с подкреплением. Создание набора данных стоило исследователям…
MedSAM2: открытая SOTA модель сегментации медицинских 3D-изображений и видео
13 апреля 2025

MedSAM2: открытая SOTA модель сегментации медицинских 3D-изображений и видео
В последние годы был достигнут значительный прогресс в разработке как специализированных, так и универсальных моделей сегментации 2D медицинских изображений, однако область 3D и видеосегментации остается недостаточно исследованной. Группа исследователей из…
Fractal TechDocs: русскоязычный ИИ-ассистент для работы с техдокументацией для инженеров и проектировщиков
9 апреля 2025

Fractal TechDocs: русскоязычный ИИ-ассистент для работы с техдокументацией для инженеров и проектировщиков
ИИ-стартап Аватар Машина выпустил Fractal TechDocs — ИИ-ассистента для строителей, инженеров, архитекторов и проектировщиков, которым требуется точная работа с нормативными документами: ГОСТы, СП, СНиПы. В эпоху ChatGPT и других универсальных…