
Generating a realistic 3D model of an object out from 2D data represents a challenging task and this problem has been explored by many researchers in the past. The creation and rendering of a high-quality 3D model are itself challenging and estimating the 3D object shape out of a 2D image is a very difficult task. People have been trying to address this issue, especially while trying to digitize virtual humans (in many different contexts ranging from video games to medical applications). Although there has been an enormous success, the generation of high-quality, realistic 3D object models is still not a solved problem. Talking about human shape modeling, there has been a great success in constructing human face but for example much less in generating 3D hair models.
This problem (of generating 3D hair models) has been addressed recently by researchers from University of Southern California, USC Institute for Creative Technologies, Pinscreen, Microsoft Research Asia, who propose a deep learning based method for 3D hair reconstruction from a single 2D unconstrained image.
Different from previous approaches, the proposed method based on Deep Learning is, in fact, able to directly generate hair strands instead of volumetric grids or point cloud structures. The new approach, according to the authors achieves state-of-the-art performance on resolution and quality and brings significant improvement in speed and storage costs. Moreover, as a very important contribution, the model in the proposed method actually provides the smooth, compact and continuous representation of hair geometry and this enables smooth sampling and interpolation.

The Method
The proposed approach consists of three steps:
- Preprocessing that calculates the 2D orientation field of the hair region.
- A deep neural network that takes the 2D orientation field and outputs generated hair strands (in a form of sequences of 3D points).
- A reconstruction step that generates a smooth and dense hair model.
As mentioned before, the first step is the actual preprocessing of the image where the authors want to obtain the 2D orientation field but only of the hair region part. Therefore, the first filter is actually extracting the hair region. It is done using a robust pixel-wise hair mask on the portrait image. After that Gabor filters are used to detect the orientation and construct the pixel-wise 2D orientation map. It is also worth to note that the researchers use undirected orientation being only interested in the orientation but not the actual hair growth direction. In order to better improve the result on segmenting the hair region, they also apply a human head and body segmentation masks. Finally, the output of the preprocessing step is 3 x 256 x 256 image where the first two image channels encode the colour-coded orientation and the third one is the actual segmentation.
Deep Neural Network
Data Representation
The output of the hair prediction network is a hair model which is represented with sequences of ordered 3D points corresponding to each modeled hair strand. In the experiments, the size of each sequence is 100 3D points each of them containing attributes of position and curvature. Thus, a hair model would contain N number of strands (sequences).

The input orientation image is first encoded into a high-level feature vector and then decoded to 32 x 32 individual strand-features. Then, each of these features is decoded to a hair geometry represented by positions and curvatures for each of the points in the strand.
Network Architecture
The employed network is taking the orientation image as input and gives two matrices as output: the positions and curvatures, as explained above. The network has an Encoder-Decoder convolutional architecture that deterministically encodes the input image into a latent vector of fixed size: 512. This latent vector, in fact, represents the hair feature which is then decoded by the decoder part. The encoder consists of 5 convolutional layers and a max pooling layer. The encoded latent vector is then decoded with the decoder which consists of 3 deconvolutional layers into multiple strand feature vectors (as mentioned above) and finally, an MLP is used to further decode the feature vectors into the desired geometry consisting of curvatures and positions.
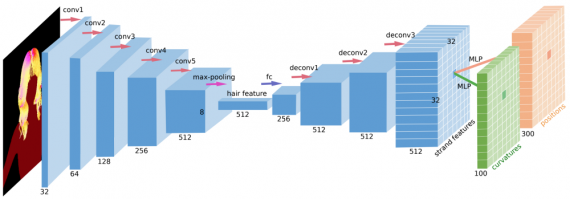
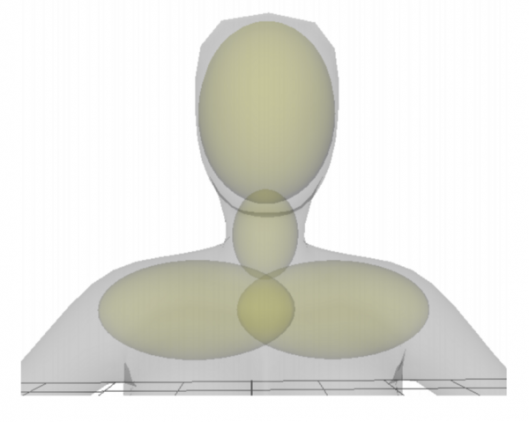
To perform the optimization of such a defined architecture and the specific problem, the authors employ 3 loss functions: two of them are the L2 reconstruction loss of the geometry (3D position and curvature) and the third one is actually a collision loss measuring the collision between the hair strand and the human body.
Evaluation and Conclusions
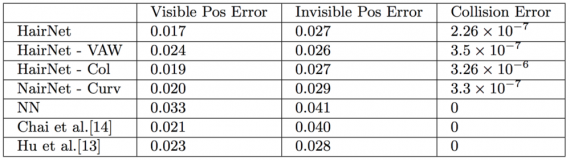
To evaluate the defined method and approach towards the problem of 3D hair reconstruction, the researchers use quantitative as well as qualitative evaluation metrics. In fact, for the quantitative analysis, they compute the reconstruction loss of the visible and the non-visible part of the hair separately to make a comparison. They create a synthetic test set with 100 random hair models and 4 images rendered from random views for each hair model. The results and the comparison with existing methods are given in the following table.

On the other hand, to be able to qualitatively evaluate the performance of the proposed approach, the researchers actually test a few real portrait photographs as input and they show that the method is able to handle different shapes (short, medium, long hair) as well as to reconstruct different levels curliness within hairstyles.

Moreover, they test also the smooth sampling and the interpolation. They show that their model is able to smoothly interpolate between hairstyles (from straight to curly or short to long).

Overall, the proposed method is interesting in many ways. It shows that an end-to-end network architecture is able to successfully reconstruct 3D hair from the 2D image, which is impressive itself but also to smoothly transition between hairstyles via interpolation, thanks to the employed encoder-decoder architecture.




