Image editing and compositing could be a fascinating creative process unless you need to spend most of your time on the tedious task of object selection. The process becomes even more time-consuming when some fuzzy boundaries and transparency are involved. Existing tools such as the magnetic lasso and the magic wand exploit only low-level cues and produce binary selections that need further refinement by the virtual artist to account for soft boundaries.
In this article, we are going to discover how neural networks may assist with this challenging task and create a set of layers that correspond to semantically meaningful regions with accurate soft transitions between different objects.
Suggested Approach
Group of researchers from MIT CSAIL (USA) and ETH Zürich (Switzerland), headed by Y. Aksoy suggested approaching this problem from a spectral segmentation angle. In particular, they propose a graph structure that combines the texture and color information from the input image as well as higher-level semantic information generated by a neural network. The soft segments are generated via eigendecomposition of the carefully constructed Laplacian matrix fully automatically. High-quality layers generated from the eigenvectors can then be utilized for quick and easy image editing. Combining elements from different images has always been a powerful way to produce new content, and now it’s also becoming much more efficient with the automatically created layers.

Overview of the suggested approach
Model Specifications
Let’s now discuss this approach to creating semantically meaningful layers step-by-step:
1. Spectral matting. The approach builds upon the work of Levin and his colleagues, who were first to introduce the matting Laplacian that uses local color distributions to define a matrix L that captures the affinity between each pair of pixels in a local patch. Using this matrix, they minimize the quadratic functional aᵀLa, subject to user-provided constraints, with a denoting a vector made of all the a values for a layer. So, each soft segment is a linear combination of the K eigenvectors corresponding to the smallest eigenvalues of L that maximizes matting sparsity.
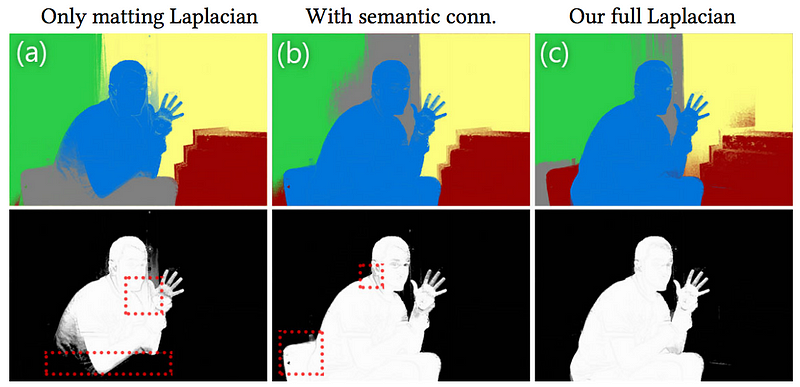
2. Color affinity. For defining nonlocal color affinity, the researchers suggest generating 2500 superpixels and estimate the affinity between each superpixel and all the superpixels within a radius that corresponds to 20% of the image size. This affinity essentially makes sure that the regions with very similar colors stay connected in challenging scene structures like the one depicted below.

Nonlocal color affinity
3. High-level semantic affinity. This stage was introduced to create segments that are confined in semantically similar regions. Semantic affinity encourages the grouping of pixels that belong to the same scene object and discourages that of pixels from different objects. Here the researchers build upon prior work in the domain of object recognition to compute a feature vector at each pixel that correlated with the underlying object. Feature vectors are computed via a neural network, which will be discussed in more details later. Semantic affinity is defined over superpixels similarly to color affinity. However, unlike the color affinity, the semantic affinity only relates nearby superpixels to favor the creation of connected objects. Combination of nonlocal color affinity and local semantic affinity allows creating layers that cover spatially disconnected regions of the same semantically coherent region (e.g., greenery, sky, other types of background).
Semantic affinity
4. Creating the layers. This part is carried out using the affinities defined earlier to form a Laplacian matrix L. The eigenvectors corresponding to the 100 smallest eigenvalues of L are extracted from this matrix, and then a two-step sparsification process is used to create 40 layers from these eigenvectors. Then, the number of layers is reduced by running the k-means algorithm with k = 5. This approach produced better results than trying to directly sparsify the 100 eigenvectors into 5 layers since such drastic reduction makes the problem overly constrained. The researchers have chosen a number of segments to be equal to 5 and claim that it is a reasonable number for most images. Still, this number can be changed by the user depending on the scene structure.

Soft segments before and after grouping
5. Semantic feature vectors. In this implementation, a semantic segmentation approach was combined with a network for metric learning. The base network of the feature extractor is based on DeepLab-ResNet-101 and trained with a metric learning approach to maximize the L2 distance between the features of different objects. Thus, the network minimizes the distance between the features of samples having the same ground-truth classes and maximizes the distance otherwise.
Qualitative Comparison to the Related Methods
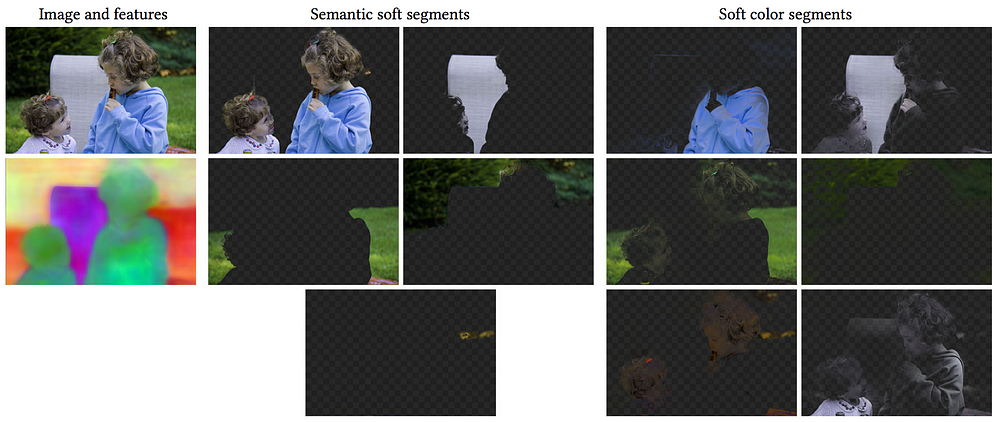
Comparison between the proposed soft segments and soft color segments by Aksoy
Figures below show the results of the suggested approach (marked as ‘Our result’) together with that of spectral matting as the most related soft segmentation method, and two state-of-the-art methods for semantic segmentation: the scene parsing method PSPNet and the instance segmentation method Mask R-CNN.


Qualitative comparison of the semantic soft segmentation approach with the related methods
You may observe that PSPNet and Mask R-CNN tend to produce inaccuracies around object boundaries, while the soft segments of spectral matting often extend beyond object boundaries. At the same time, the semantic soft segmentation approach, described here, captures objects in their entirety without grouping unrelated objects and achieves a high accuracy at edges, including soft transitions when appropriate. However, it should be noted that the semantic features in this method are not instance-aware, i.e. the features of two different objects of the same class are similar. This results in multiple objects being represented in the same layer such as cows or giraffes on the pictures above.
Image Editing with Semantic Soft Segments
Several use cases of soft segments for targeted editing and compositing are demonstrated below. As you see, the soft segments can also be used to define masks for specific adjustment layers such as adding motion blur to the train in (2), color grading the people and the backgrounds separately in (5, 6) and separate stylization of the hot-air balloon, sky, terrain and the person in (8). While these edits can be done via user-drawn masks or natural matting algorithms, automated defining of the semantically meaningful objects makes the targeted edits effortless for the visual artist.

Use of semantic soft segmentation in image editing tasks
Bottom Line
The proposed approach generates soft segments that correspond to semantically meaningful regions in the image by fusing the high-level information from a neural network with low-level image features fully automatically. However, the method has several limitations. First of all, it is relatively slow: runtime for a 640 x 480 image lies between 3 and 4 minutes. Secondly, the method does not generate separate layers for different instances of the same class of objects. And finally, as demonstrated below, the method may fail at the initial constrained sparsification step when the object colors are very similar (top example), or the grouping of soft segments may fail due to unreliable semantic feature vectors around large transition regions (bottom example).

Failure cases
Still, soft segments generated using the presented approach, provide a convenient intermediate image representation that makes it much easier to handle image editing and compositing tasks, which otherwise require lots of manual labor.