
Редактирование изображений и создание коллажей было бы весьма захватывающим процессом, если бы не приходилось тратить бо́льшую часть времени на кропотливую разметку объектов. Задача еще усложняется, когда границы объектов размыты или присутствует прозрачность. Инструменты “Photoshop”, такие как «магнитное лассо» и «волшебная палочка», не очень интеллектуальны, поскольку ориентируются лишь на низкоуровневые признаки изображения. Они возвращают жёсткие (Hard) границы, которые затем нужно исправлять вручную. Подход Semantic Soft Segmentation от исследователей Adobe помогают решить эту непростую задачу, разделяя изображение на слои, соответствующие семантически значимым областям, и добавляя плавные переходы на краях.
«Мягкая» сегментация
Группа исследователей из лаборатории CSAIL в MIT и швейцарского университета ETH Zürich, работающая под руководством Ягыза Аксоя, предложила подойти к этой проблеме, основываясь на спектральной сегментацией, добавив к ней современные достижения глубокого обучения. С помощью текстурной и цветовой информации, а также высокоуровневых семантических признаков, извлечённых нейросетью, по изображению строится граф специального вида. Затем по этому графу строится матрица Кирхгофа (Laplacian matrix). Используя спектральное разложение этой матрицы, алгоритм генерирует мягкие контуры объектов. Полученное с помощью собственных векторов разбиение изображения на слои можно затем использовать для редактирования.
-

Обзор предложенного подхода

Описание модели
Рассмотрим метод создания семантически значимых слоёв пошагово:
1. Спектральная маска. Предложенный подход продолжает работу Левина и его коллег, которые впервые использовали матрицу Кирхгофа в задаче автоматического построения маски. Они строили матрицу L, которая задаёт попарное сходство между пикселями в некоторой локальной области. С помощью этой матрицы они минимизируют квадратичный функционал αᵀLα с заданными пользователем ограничениями, где α задаёт вектор значений прозрачности для всех пикселей данного слоя. Каждый мягкий контур является линейной комбинацией K собственных векторов, соответствующих наименьшим собственным значениям L, которая максимизирует так называемую разреженность маски.
2. Цветовая близость. Для вычисления признаков нелокальной цветовой близости исследователи генерируют 2500 суперпикселей и оценивают близость между каждым суперпикселем и всеми суперпикселями в окрестности радиусом 20% размера изображения. Использование нелокальной близости гарантирует, что области с очень похожими цветами останутся связными в сложных сценах, подобных изображённой ниже.
-
Нелокальная цветовая близость

3. Семантическая близость. Эта стадия позволяет выделять семантически связные области изображения. Семантическая близость поощряет объединение пикселей, которые принадлежат одному объекту сцены, и штрафует за объединение пикселей разных объектов. Здесь исследователи используют предыдущие достижения в области распознавания образов и вычисляют для каждого пикселя вектор признаков, коррелирующий с объектом, в который входит данный пиксель. Векторы признаков вычисляются с помощью нейросети, о чём мы поговорим далее более подробно. Семантическая близость, как и цветовая, определяется на суперпикселях. Однако, в отличие от цветовой близости, семантическая близость связывает только ближайшие суперпиксели, поощряя создание связных объектов. Сочетание нелокальной цветовой близости и локальной семантической близости позволяет создать слои, которые покрывают разъединённые в пространстве изображения фрагмента одного семантически связанного объекта (например, растительность, небо, другие типы фона).
-
Семантическая близость
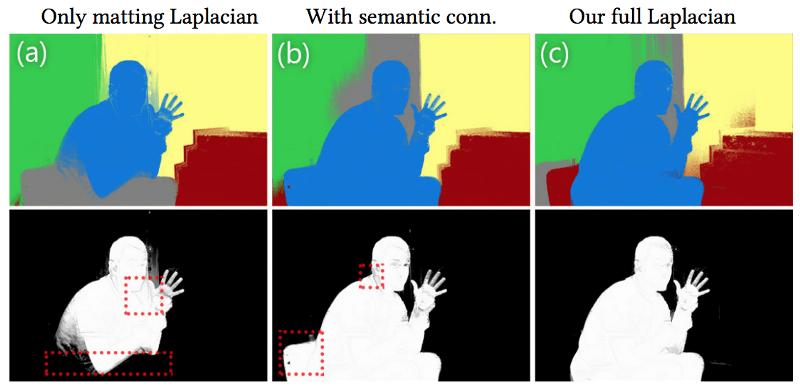
4. Создание слоёв. На этом шаге с помощью вычисленных ранее близостей строится матрица L. Из этой матрицы извлекаются собственные векторы, соответствующие 100 наименьшим собственным значениям, а затем применяется алгоритм разреживания, который извлекает из них 40 векторов, по которым строятся слои. Затем количество слоёв ещё раз уменьшается с помощью алгоритма кластеризации k-means при k = 5. Это работает лучше, чем простое разреживание 100 собственных векторов до пяти, поскольку такое сильное сокращение размерности делает задачу переопределённой. Исследователи выбрали итоговое число контуров равным 5 и утверждают, что это разумное число для большинства изображений. Тем не менее, это число можно изменить вручную в зависимости от обрабатываемого изображения.

5. Семантические векторы признаков. Для вычисления семантической близости использовались векторы признаков, посчитанные с помощью нейросети. Основой нейросети стала DeepLab-ResNet-101, обученная на задаче предсказания метрики. При обучении поощрялась максимизация L2-расстояния между признаками разных объектов. Таким образом, нейросеть минимизирует расстояние между признаками, соответствующими одному классу, и максимизирует расстояние в другом случае.
Качественное сравнение со схожими методами
Изображения, приведённые ниже, показывают результаты работы предложенного подхода (подписанные как «Our result») в сравнении с результатами наиболее близкого подхода мягкой сегментации — спектрального метода построения маски — и двумя state-of-the-art методами семантической сегментации: методом обработки сцен PSPNet и методом сегментации объектов Mask R-CNN.


Можно заменить, что PSPNet и Mask R-CNN склонны ошибаться на границах объектов, а мягкие контуры, построенные спектральным методом, часто заходят за границы объектов. При этом описанный метод полностью охватывает объект, не объединяя его с другими, и достигает высокой точности на краях, добавляя мягкие переходы, где это требуется. Однако стоит заметить, что семантические признаки, использованные в данном методе, не различают два разных объекта, принадлежащих к одному классу. В результате множественные объекты представлены на одном слое, что видно на примере изображений жирафов и коров.
Редактирование изображений с помощью мягких семантических контуров

Ниже приведено несколько примеров применения мягких контуров для редактирования изображений и создания коллажей. Мягкие контуры можно использовать для применения конкретных изменений к разным слоям: добавления размытия, изображающего движение поезда (2), раздельной цветовой коррекции для людей и для фона (5, 6), отдельной стилизации для воздушного шара, неба, ландшафта и человека (8). Конечно, то же самое можно сделать с помощью созданных вручную масок или классических алгоритмов выделения контура, но с автоматическим выделением семантически значимых объектов такое редактирование становится значительно проще.
-
Использование мягкой семантической сегментации для редактирования изображений

Заключение
Данный метод автоматически создаёт мягкие контуры, соответствующие семантически значимым областям изображения, используя смесь высокоуровневой информации от нейронной сети и низкоуровневых признаков. Однако у этого метода есть несколько ограничений. Во-первых, он относительно медленный: время обработки изображения с размерами 640 x 480–3–4 минуты. Во-вторых, этот метод не создаёт отдельные слои для разных объектов одного класса. И в-третьих, как показано ниже, этот метод может ошибиться на начальных этапах обработки в случаях, когда цвета объектов очень похожи (верхний пример), или во время объединения мягких контуров возле больших переходных областей (нижний пример).
-
Случаи ошибок алгоритма

Тем не менее, мягкие контуры, созданные с помощью описанного метода, дают удобное промежуточное представление изображения, позволяющее тратить меньше времени и сил при редактировании изображений.






