Исследователи Alibaba Group представили фреймворк ArtAug для улучшения качества генерации изображений из текста без дополнительных вычислительных затрат на этапе инференса, используя взаимодействие между генеративными и понимающими (understanding) моделями.

Архитектура ArtAug реализует мультиагентную систему Chain of Thought (CoT) с тремя специализированными компонентами, работающими через дифференциальное обучение. Data-CoT агент обеспечивает интеграцию данных, Concept-CoT выполняет аналитическое рассуждение, а Thesis-CoT синтезирует результаты в финальное изображение.

Недавние достижения в области диффузионных моделей значительно улучшили возможности искусственного интеллекта по синтезу изображений. Однако генерация высококачественных изображений, соответствующих эстетическим предпочтениям человека, по-прежнему остается сложной задачей, и существующие решения часто не дотягивают до желаемого результата из-за узкой направленности на технические факторы или ограниченной способности учитывать человеческое суждение при оценке результатов. Исследователи из Восточного педагогического университета Китая и компании Alibaba Group решают эту проблему с помощью ArtAug — первой в своем роде структуры ИИ-агента, которая улучшает модели преобразования текста в изображение благодаря взаимодействию моделей генерации и понимания.
ArtAug уникально использует человеческие предпочтения, неявно усвоенные моделями понимания изображений, чтобы предоставлять детализированные рекомендации для синтеза изображений, достигая улучшений в таких областях, как регулировка экспозиции, композиция и атмосферные эффекты.
Техническая реализация ArtAug
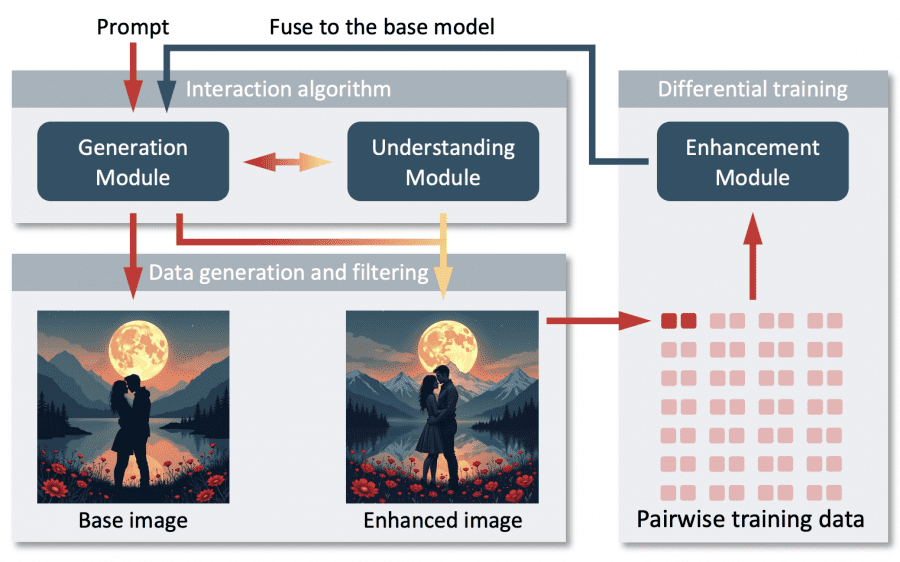
Фреймворк состоит из трех основных модулей.
Generation Module обрабатывает начальный синтез изображений, используя диффузионную модель FLUX.1[dev]. Архитектура поддерживает интеграцию других базовых моделей.
Understanding Module реализован на Qwen2-VL-72B и обеспечивает анализ изображений с предоставлением bounding box и промптов для улучшения. Модуль выбран после сравнительного тестирования шести мультимодальных LLM, где только Qwen2-VL-72B и Claude-3.5-sonnet продемонстрировали достаточные возможности визуального грундинга.
Enhancement Module использует LoRA для обучения и применения улучшений с сохранением семантической согласованности. Модуль работает с 15 слоями message passing, hidden dimension 256 и использует bfloat16 на GPU H100.
Метрики эффективности
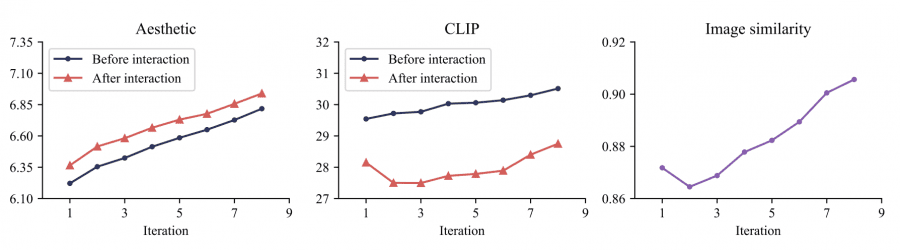
ArtAug демонстрирует существенные улучшения по всем ключевым метрикам качества. Эстетическая оценка улучшилась с 6.35 до 6.81, PickScore вырос с 42.22 до 57.78, а MPS score увеличился с 47.52 до 52.48.

При этом система сохраняет высокий уровень семантического соответствия текстовым промптам, что подтверждается CLIP-скором 26.97 (базовый уровень 26.92) и выигрышем в 45.93% случаев при человеческой оценке.
Преимущества перед существующими методами
В сравнении с традиционными подходами ArtAug показывает ряд преимуществ: не требует обширной ручной разметки как RLHF, имеет меньшую вычислительную сложность чем DPO, обеспечивает более стабильные результаты чем prompt engineering. Существующие готовые решения также имеют ограничения: CapitalCube предоставляет ограниченный контроль над эстетикой изображения, Wright Report демонстрирует более низкое качество, а MarketGrader менее гибок в улучшениях.
ArtAug поддерживает высокую производительность при значительном сокращении требований к обучающим данным (используется только 1-2% сгенерированных пар), вычислительным ресурсам при инференсе и затратам на ручную разметку.
Техническая имплементация
Исходный код и предобученные модели доступны под лицензией Apache 2.0 через официальный репозиторий DiffSynth-Studio. Предобученные модели распространяются через платформу ModelScope, что обеспечивает простую интеграцию в существующие пайплайны. Фреймворк позволяет расширять функциональность через дополнительные модули и поддерживает интеграцию различных базовых моделей генерации изображений.
В текущей версии имеются определенные ограничения, включая необходимость ручной проверки в процессе фильтрации данных. Однако открытый исходный код и модульная архитектура создают возможности для дальнейшего развития фреймворка сообществом разработчиков.