We, as human beings are able to digest a sound video with almost no effort. Being able to detect and track objects within the frames of a video allows us to gain contextual information and understand more or less what is going on in the video. On the other hand, we are able to process audio information very tightly coupled with those frames and gain an even better understanding of the action happening in the video.
Previous work
Quite a lot of research has been done exploring the relationship between vision and sound. A number of problems arise from this relationship and a number of methods have been proposed to solve some of them. In the past and especially in the recent past, researchers have addressed problems such as sound localization in videos, sound generation in silent videos, self-supervision in videos using audio signal etc.
State-of-the-art idea
Recent work, conducted and published by researchers from Massachusetts Institute of Technology, MIT-IBM Watson AI Lab and Columbia University has explored the relationship between vision and sound in a different way. In fact, researchers proposed a novel self-supervised method that learns to locate image regions which produce sounds and separate the input sounds into a set of components that represents the sound from each pixel.
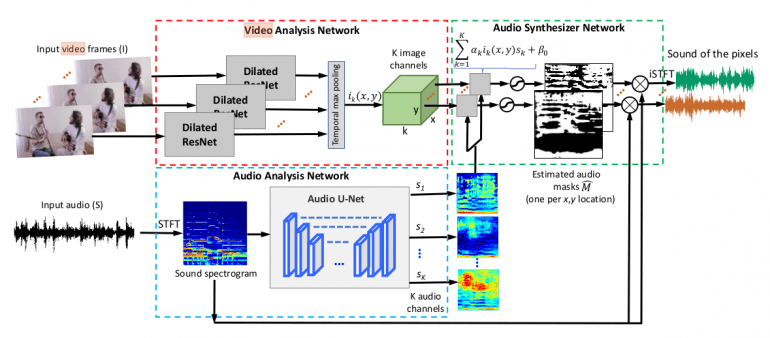
Method
Their approach is focused on leveraging the natural synchronization of the visual and audio information to learn to separate and locate sound components within a video in a self-supervised manner. They introduce their system called PixelPlayer that is able to learn to recognize and localize objects in images and to separate the audio component coming from each object. Additionally, the researchers introduced new musical instrument video dataset, called MUSIC built for the purpose of this work.

As mentioned before, the proposed method localizes sound sources in a video and separates the audio into its components without supervision. It is composed of three major modules: Video analysis network, audio analysis network and audio synthesizer network. This kind of architecture allows extracting visual and audio features for the goal of audio-visual source separation and localization.
Video Analysis Network
The video analysis network is trying to extract visual features for each frame in the video. Temporal pooling is applied to each of the per-frame extracted features to obtain a visual feature vector for each pixel. To do so, the researchers employ a variation of the popular ResNet-18 network with dilated convolutions.
Audio Analysis Network
Parallel to the extraction of visual features, the audio analysis network is trying to split the input sound from the video into K components. To solve this problem, the researchers propose to use sound spectrograms instead of raw sound waveforms and employ a convolutional architecture that has proven successful with audio data in the past. Their choice here falls on Audio U-Net. Using this kind of encoder-decoder architecture, they are able to extract K feature maps out of the spectrogram containing features of different components of the input sound. Previously, they use STFT (Short-Time Fourier Transform) to obtain the sound spectrogram which is used as input to the network.
Audio Synthesizer Network
The core module of the proposed method is the synthesizer network which takes both the output from the video analysis network as well as the audio analysis network. More precisely, it takes the pixel-level visual feature and the audio feature and it outputs a mask that could separate the sound of that pixel from the input spectrogram. The way the final resulting sound for each pixel is obtained is by taking the corresponding mask and multiplying it with the input spectrogram. To get the resulting sound as a waveform, inverse STFT is applied.
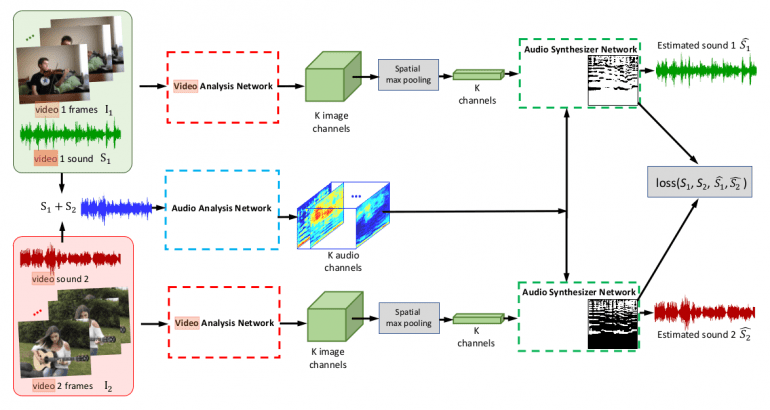
In order to train such an architecture in an unsupervised (or self-supervised) manner, the researchers proposed a training framework that they call Mix-and-Separate. Their idea builds upon the assumption that sounds are approximately additive. Therefore, they mix sounds from different videos to generate a complex audio input signal and then the learning objective is to separate a sound source of interest conditioned on the visual input associated with it.
Results
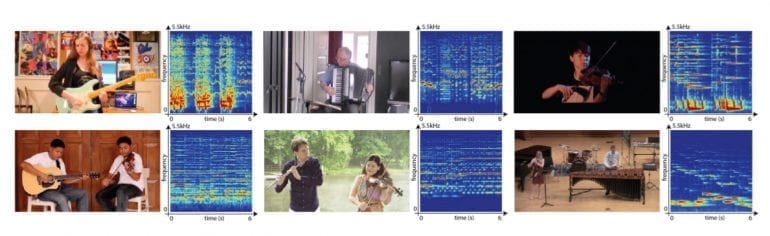
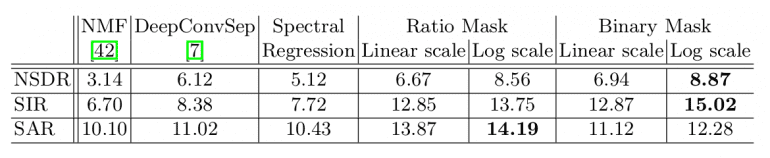
In order to perform an initial evaluation, the authors use again their training framework called Mix-and-Separate. They created a validation set of synthetic mixture audios and the separation is evaluated on this set. Since the goal is to learn and predict the spectrogram they do qualitative evaluation by comparing the ground-truth and the estimated spectrogram. For a quantitative evaluation, they use Normalized Signal-to-Distortion Ratio (NSDR), Signal-to-Interference Ratio (SIR), and Signal-to-Artifact Ratio (SAR) as evaluation metrics on the validation set of the synthetic videos.

Conclusion
Overall, the proposed method is interesting from several points of view. First, it shows that self-supervised learning can be applied to problems like this. Second, the method is able to jointly perform several tasks such as locating image regions which produce sounds and separating the input sounds into a set of components that represents the sound from each pixel. And third, it represents one of the first studies that explore the correspondence between single pixels and sound in videos.



