
3D hair reconstruction is a problem with numerous applications in different areas such as Virtual Reality, Augmented Reality, video games, medical software, etc. As a non-trivial problem, researchers have proposed various solutions in the past, some of them more some of them less successful. Generating realistic 3D hair model represents a challenge even when done in controlled, relatively sterile environments. Therefore, the generation of 3D hair model in-the-wild out of ordinary photos or videos is a challenging task.
Previous works
Recently, we wrote about an approach for realistic 3D hair reconstruction out of a single image. This kind of methods work well, but fail to produce high-fidelity results of 3D hair reconstruction models due to the limitations and ambiguity of the problem. Other approaches use multiple images or views and yield improved results while increasing the complexity of the solution. These approaches require controlled environments with 360 views of the person and multiple images.
Additionally, some approaches require input such as hair segmentation, making the whole process of 3D hair reconstruction more cumbersome.
State-of-the-art idea
A new approach proposed by researchers from the University of Washington can take in an in-the-wild video and automatically output a full head model with a 3D hair-strand model. The input to the proposed method is a video whose frames are used by a few components to produce hair strands – estimated and deformed in 3D (rather than 2D as in state of the art) thus enabling superior results.
Method
The method is composed of 4 components which are shown in the illustration below:
A: Module which uses structure from motion to get relative camera poses, depth maps and a visual hull shape with view-confidence values.
B: Module in which hair segmentation and gradient direction networks are trained to apply on each frame and obtain 2D strands.
C: The segmentations from module B are used to recover the texture of the face area, and a 3D face morphable model is used to estimate face and bald head shapes.
D: The last module and the core of the algorithm where the depth maps and 2D strands are used to create 3D strands. These 3D strands are used to query a hair database and the strands from the best match are refined both globally and locally to fit the input frames from the video.
In this way, a robust and flexible method is obtained which can successfully recover 3D hair strands from in-the-wild video frames.
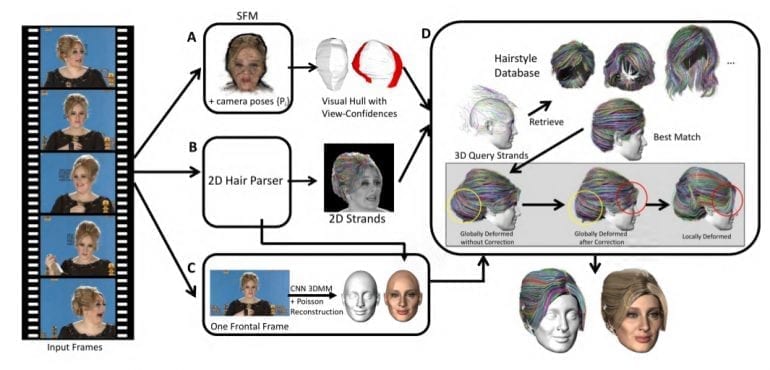
Module A: The first module is used to obtain a rough head shape. Each frame of the videos is pre-processed using semantic segmentation to separate the background from a person. The goal here is to estimate camera pose per frame and to create a rough initial structure from all the frames.
First, after pre-processing and removing the background, the head moving within all frames is extracted by using structure from motion approach – estimation of camera poses per frame and per-frame depth for all frames in the video. The output of this module is a rough visual hull shape.
Module B: The second module contains the trained hair segmentation and hair directional classifiers to label and predict the hair direction in hair pixels of each video frame inspired by strand direction estimation method of Chai et al. 2016.

Module C: In this module, the segmented frames are used to select the frame that is closest to frontal face (where yaw and pitch are approximately 0), and fed to a morphable-model-based face model estimator.
Module D: The last, in fact, the core module is estimating 3D hair strands using the outputs of modules A, B and C. Initially, since in this module each frame has an estimation of 2D strands, 3D hair strands are obtained by projecting them to depths to obtain the initial estimate of 3D strands. Then, those 3D hair strands are used to query a database of 3D hair models since the initial strands are incomplete. In their work, the researchers use the hair dataset created by Chai et al. 2016, which contains 35, 000 different hairstyles, each hairstyle model consisting of more than 10, 000 hair strands. A global and also a local deformation is applied in the end to refine the obtained 3D hair strands.
Results
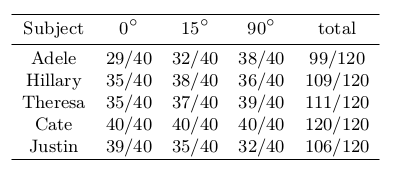
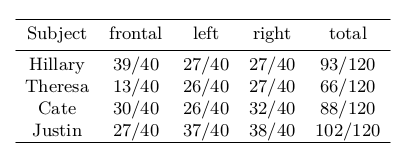
To evaluate the proposed approach, the researchers use both quantitative and qualitative evaluation as well as human study comparison. A quantitative comparison is made by projecting the reconstructed hair as lines onto the images, computing the intersection-over-union rate to the ground truth hair mask per frame. The results are shown in the table below. A larger IOU means that the reconstructed hair approximates the input better.

The approach was evaluated qualitatively against some state-of-the-art methods. Moreover, human preference tests using Mechanical Turk have been done, and the results are shown in the tables.

Conclusion
In this paper, researchers from the University of Washington proposed a fully automatic way of 3D hair reconstruction out of in-the-wild videos, which can have a wide variety of potential applications. Although the method itself is quite complex and involves many steps, the results are more than satisfactory. The approach shows that higher fidelity in the results can be obtained by incorporating information from multiple frames of videos where slightly different views are present. The proposed system is exploiting this to reconstruct 3D hair model while not restricted to specific views and head poses.








