Realistic, humanlike chracters represent a very important area of computer animation. These characters are vital components of many applications, such as cartoons, computer games, cinematic special effects, virtual reality, artistic expression etc. However, character animation production typically goes through a number of creation stages and as such it represents a laborious task.
Previous Work
Such a labor-intensive task represents a bottleneck in the whole process of computer animation creation. In the past, there have been a number of attempts to overcome this problem and make this task supported by automatic tools, or even completely automated.
Many of the proposed approaches in the past have failed when it comes to producing robust and naturalistic motion controllers that enable virtual characters to perform complex skills in physically simulated environments. The first attempts and approaches have focused mostly on understanding the physics and biomechanics and trying to formulate and replicate motion patterns to virtual characters. More recently, data-driven approaches have caught the attention. However, most data-driven approaches, save for a few exceptions, are based on motion capture data, which often requires costly instrumentation and heavy pre-processing.
State-of-the-art Idea
Recently, researchers from Berkeley AI Research at the University of California have proposed a novel Reinforcement Learning-based approach for learning character animation from videos.
Combining motion estimation from videos and deep reinforcement learning, their method is able to synthesize a controller given a monocular video as input. Additionally, the proposed method is able to predict potential human motions from still images, by forward simulation of learned controllers initialized from the observed pose.
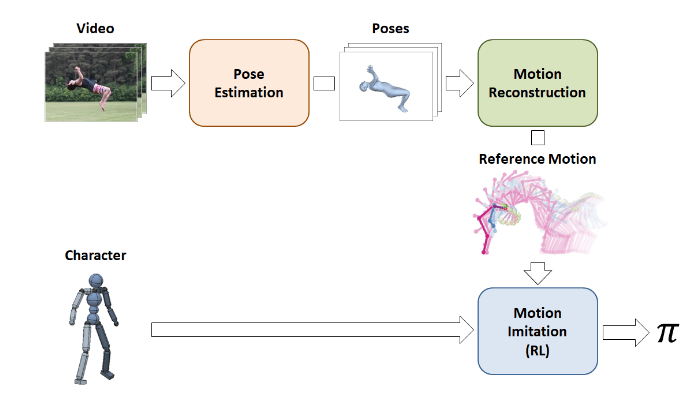
Method
The researchers propose a framework that takes a monocular video and outputs motion imitation done by a simulated character model. The whole approach is based on pose estimation in the frames of the video, which is later used for motion reconstruction and motion imitation to achieve the final goal.
First, the input video is processed by the pose estimation stage, where a learned 2D and 3D pose estimators are applied to extract (estimate) the pose of the actor in each frame. Next, the set of predicted poses proceeds to the motion reconstruction stage, where a reference motion trajectory is optimized such that it is consistent with both the 2D and 3D pose predictions, while also enforcing temporal-consistency between frames. The reference motion is then utilized in the motion imitation stage, where a control policy is trained to enable the character to reproduce the reference motion in a physically simulated environment.
Pose Estimation Stage
The first module in the pipeline is the pose estimation module. At this stage, the goal is to estimate the pose of the actor from single still image i.e. each video frame. There are a number of challenges that have to be addressed at this point, in order to obtain accurate pose estimation. First, the variability in the body orientation among different actors performing the same movement is very high. Second, pose estimation is to be done at each frame independently from the previous or next frames, not accounting for temporal consistency.
To address both of those issues, the researchers propose to use an ensemble of already existing and proven methods for pose estimation. Along with that they use a simple data augmentation technique to improve pose predictions in the domain of acrobatic movements.
They train an ensemble of estimators on the augmented dataset and obtain 2D and 3D pose estimations for each frame, which define the 2D and 3D motion trajectories, respectively.

Motion Reconstruction Stage
In the motion reconstruction stage, the independent predictions from the pose estimators are consolidated to form the final reference motion. The ultimate goal that the researchers were aiming for in this stage is to improve the quality of the reference motions by fixing errors and removing motion artifacts often manifested as nonphysical behaviours. According to the researchers, these motion artifacts appear due to inconsistent predictions across adjacent frames.
Again, an optimization technique is applied at this stage, optimizing for a common 3D pose trajectory for the pose estimators, while at the same time enforcing temporal consistency between consecutive frames. The optimization is done in the latent space, using the pose estimators leveraging their encoder-decoder architecture.
Motion Imitation Stage
In the final stage, deep reinforcement learning is applied to reach the final objective. From a machine learning perspective, the goal here is to learn a policy that enables the character to reproduce the demonstrated skill in (video) simulation. The reference motion extracted previously is used to define an imitation objective, and a policy is then trained to imitate the given motion.
The reward function is designed to incentivize the character to track the joint orientations from the reference motion. In fact, quaternion differences of joint rotations are computed between the character’s joint rotations and the joint rotations of the extracted reference motion.
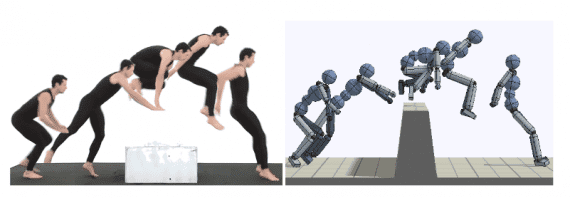
Results
To demonstrate the proposed framework and evaluate the proposed method, the researchers employ a 3D humanoid character and a simulated Atlas robot. A qualitative evaluation was done by comparing snapshots of the simulated characters with the original video demonstrations. All video clips were collected from YouTube and they depict human actors performing various acrobatic motions. As they mention in the paper, since it is a difficult challenge to quantify the difference between the motion of the actor in the video and the simulated character, performance was evaluated with respect to the extracted reference motion. The figures below show overlapping snapshots of the real videos and the simulated characters for a qualitative evaluation.
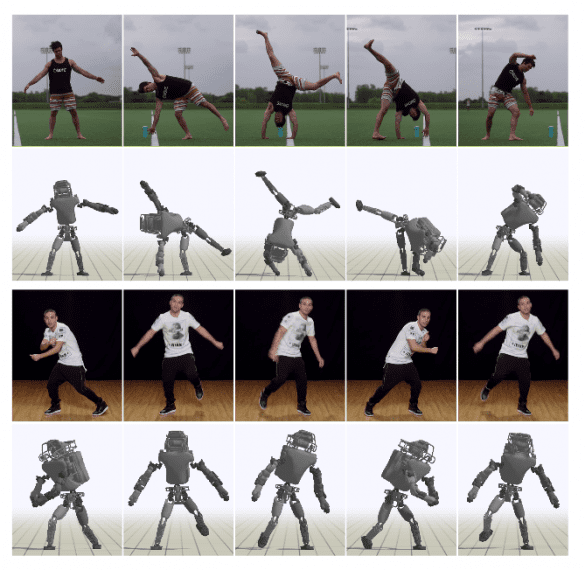



Conclusions
The proposed method for data-driven animation creation leverages the abundance of publicly available video clips from the web to learn full-body motion skills and as such it represents a significant contribution. The proposed framework shows the potential of combining multiple, different techniques to build a whole framework and reach a specific objective. As such, there exists a big advantage of the modular design since new advances, relevant to the various stages of the pipeline can be incorporated at later stages to further improve the overall effectiveness of the framework.