In the beginning of this year, researchers from Google DeepMind and Google Brain have published a paper where they propose the game of Hanabi as the newest challenge for AI systems. This proposal came as a continuation of the tradition to name domains which will represent frontiers for testing AI, and it is actually another domain following after the games of Go, Atari, poker etc.
Today, a group of researchers from Facebook AI Research (FAIR) has proposed a method that achieves state-of-the-art performance in the Hanabi game. In their paper named “Improving Policies via Search in Cooperative Partially Observable Games”, researchers describe a bot that outperforms previous algorithms by using real-time search to fine-tune its strategy and decision during the gameplay.
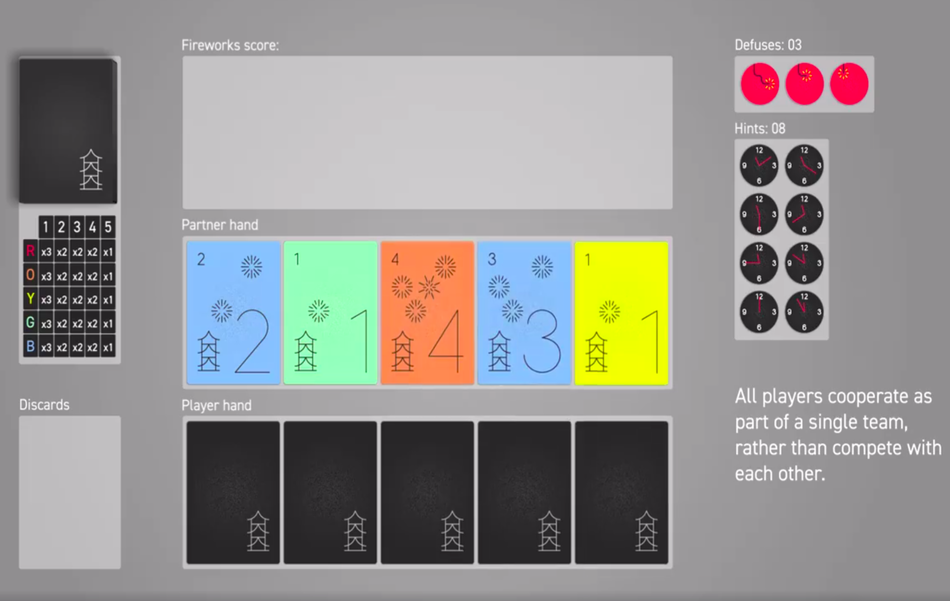
The uniqueness of the Hanabi game is that thing that makes it suitable for being the new frontier of AI research. There are two major characteristics that make Hanabi the perfect challenge for AI systems: cooperative gameplay and imperfect information.
In Hanabi, players must work together in a collaborative manner and they must try to understand the beliefs and intentions of other players. Moreover, players do not see the cards that all other players see and they can only share very limited hints, making it an imperfect-information game.
In order to solve a complex task as developing a strategy for Hanabi, researchers propose a search-based method that refines the strategy during gameplay. In fact, the proposed method uses a pre-computed full-game strategy only as a reference and uses the information from it to compute an improved strategy in real-time for the specific situation.
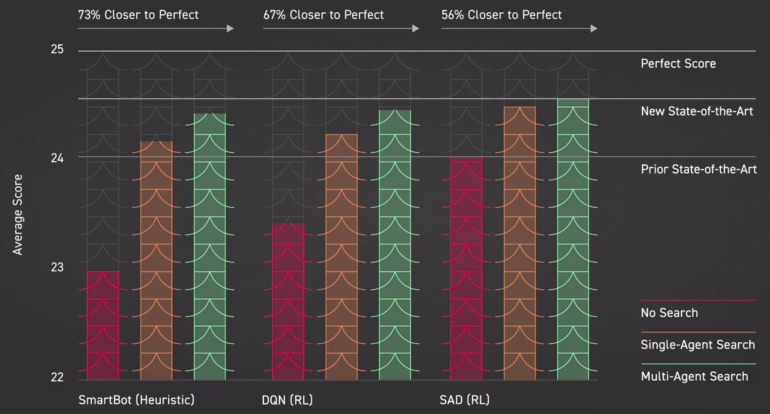
Researchers propose two different approaches for solving the problem: the first one where a single agent conducts the search and all the other players play using the pre-computed strategy, and a second one where a more complex multi-agent search is implemented.
The proposed method was evaluated and compared to existing methods and researchers showed that it outperforms all of them by a significant margin. They note that simply adding a single-agent search to a handcrafted bot for playing Hanabi results in significant performance improvements.
The implementation of the Hanabi bot was open-sourced and it is available here. More details about the search-based RL policies and the evaluation of the proposed method can be found in the paper published on arxiv.