
PF-AFN is a neural network that generates images of people trying on different kinds of clothes. The model accepts an image of a person and an image of a garment as input. At the output, the model gives an image in which the target person is wearing a garment. The neural network bypasses the previous approaches, which are based on the model of segmentation of human parts.
Limitations of previous approaches
The task is to superimpose the image of the target object of clothing on the image of a person. Previous approaches relied on the markup of a person’s image. However, minor segmentation errors resulted in unrealistic images that contained visual artifacts. Recent work has used a knowledge distillation approach to reduce the model’s dependence on parsing a person in an image. In this case, the fitting images generated by the parser-based method are used as markup for training the “student” model. The “student” model does not rely on the markup of the person in the image when generating images with fitting. In turn, learns to replicate the behavior of the teacher model. However, the quality of the “student” model is limited by the teacher model, which is based on a parser. To get around this limitation, researchers propose a “teacher-tutor-student” approach to the distillation of knowledge.
More about the neural network
The proposed approach allows generating highly realistic images without segmentation of a person in the image. This approach allows you to use the images generated by the parser method as the tutor’s knowledge. Artifacts in such images can be corrected in a self-supervised format using the teacher’s knowledge, which is extracted from images of real people.
Comparison of the proposed model with an alternative approach that does not use a human parser
Researchers formulate the knowledge distillation problem to generate fitting images as distilling the flows of appearance between the image of a person and the image of a garment. This allows you to find matches between them and generate high-quality images.
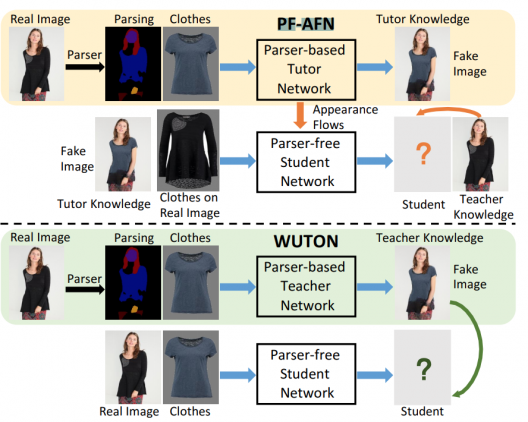
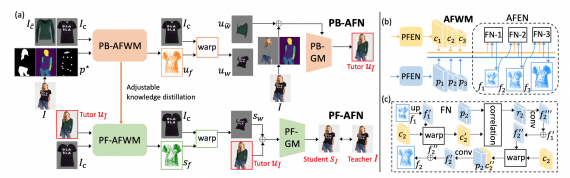
In comparison with state-of-the-art approaches that are based on parsers, and those that do not use a human-in-image parser, the proposed model produces more realistic results. Parser-based methods include CP-VTON, ClothFlow, CP-VTON +, and ACGPN. The only alternative model without a parser is WUTON.







