
East China Normal University and Alibaba Group researchers have introduced ArtAug, a framework that enhances text-to-image generation through synthesis-understanding interaction. This approach significantly improves image quality without requiring extensive manual annotation or computationally expensive training.
Recent advancements in diffusion models have significantly improved AI image synthesis capabilities. However, generating high-quality images that align with human aesthetic preferences remains challenging, with existing solutions often falling short due to their narrow focus on technical factors or limited ability to incorporate human judgment. Researchers from East China Normal University and Alibaba Group address this challenge with ArtAug – a first-of-its-kind AI agent framework that enhances text-to-image models through interaction between synthesis and understanding modules. ArtAug uniquely leverages human preferences implicitly learned by image understanding models to provide fine-grained suggestions for image synthesis, delivering improvements in areas like exposure adjustment, composition, and atmospheric effects.

The framework employs a multi-agent Chain of Thought (CoT) system with three specialized agents: the Data-CoT Agent for robust data integration, the Concept-CoT Agent for analytical reasoning, and the Thesis-CoT Agent for synthesis into coherent outputs. Through iterative enhancement and differential training, ArtAug successfully improves existing text-to-image models without requiring additional computational resources during inference.
Core Architecture
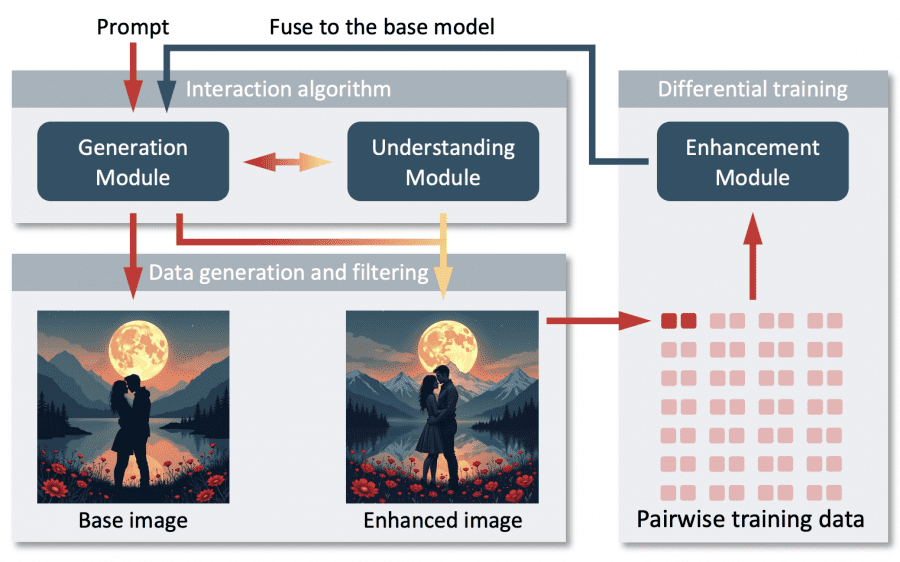
The system employs a three-module architecture working in concert:
Generation Module handles the initial text-to-image synthesis using standard diffusion techniques. The current implementation uses FLUX.1[dev] as the base model, though the framework can work with other text-to-image models.
Understanding Module, implemented using Qwen2-VL-72B, analyzes generated images and provides specific enhancement suggestions through bounding boxes and descriptive prompts. This module was selected after comparative testing of six multimodal LLMs, where only Qwen2-VL-72B and Claude-3.5-sonnet demonstrated sufficient visual grounding capabilities.
Enhancement Module, built as a LoRA model, learns and applies the suggested improvements while maintaining semantic consistency. The module operates with 15 message passing layers and a hidden dimension of 256, using bfloat16 precision on H100 GPUs.
Results and Performance
The system demonstrates significant improvements across multiple metrics.
Aesthetic Quality Metrics

- Aesthetic score: 6.81 (baseline: 6.35)
- PickScore: 57.78 (baseline: 42.22)
- MPS score: 52.48 (baseline: 47.52)
Text-Image Alignment
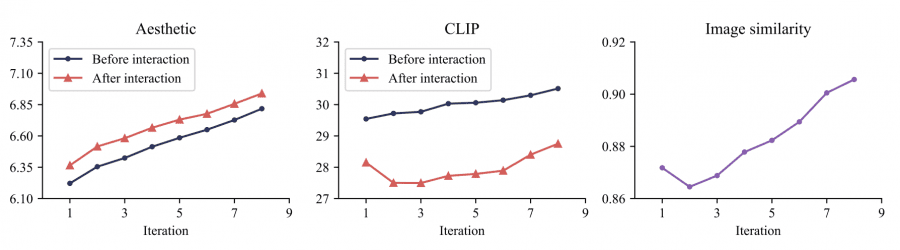
- CLIP score: 26.97 (baseline: 26.92)
- Human evaluation win rate: 45.93%
Comparative View
RLHF-based approaches requires extensive manual annotation, DPO-based methods requires higher computational costs while prompt engineering provides less consistent results. Other state-of-the-art methods have own disadvantages: CapitalCube provides limited aesthetic control, Wright Report is lower visual quality, MarketGrader considered less flexible enhancement
The system maintains high performance while reducing training data requirements (only 1-2% of generated pairs needed), computational overhead during inference, manual annotation costs.
Implementation
The complete source code and trained models are available under the Apache 2.0 license, enabling broad collaboration and innovation within the AI community. The implementation can be found at the official repository: <a href=”https://github.com/modelscope/DiffSynth-Studio”>DiffSynth-Studio</a>, with pre-trained models accessible through the ModelScope platform.</p>








