
SII-GAIR and Sand.ai have published daVinci-MagiHuman — an open-source multimodal 15B model based on a single-stream transformer that simultaneously generates video with precise lip sync and synchronized audio, producing a 5-second 256p clip in 2 seconds on a single H100 GPU. The full stack is released under Apache 2.0: the base model, distilled version, super-resolution module, and inference code are available on GitHub and Hugging Face, with a demo on Hugging Face Spaces. This is rare for models at this level — most competitors (Veo 3, Sora 2, Kling 3.0) are closed-source. Among open alternatives (Ovi, LTX-2), daVinci-MagiHuman achieves the best video quality and the lowest word error rate on generated speech — 14.60% versus 40.45% for Ovi 1.1 — indicating significantly clearer and more intelligible lip sync output.
Example lip sync video generated by daVinci-MagiHuman from a photo:

Why build a single stream instead of two?
Most modern models for joint video and audio generation work like this: one token stream processes video, another handles audio, and a cross-attention block sits between them to fuse the two. This is logical, but creates practical problems: non-standard computational patterns are hard to optimize on hardware, and the codebase becomes unwieldy. Lip sync quality also suffers when video and audio representations are not learned jointly from the start.
daVinci-MagiHuman takes a different approach. Text, video, and audio are simply concatenated into a single token sequence and passed through a unified transformer using self-attention only. No cross-attention, no separate modality fusion blocks. This single-stream architecture allows the model to learn lip sync alignment directly during joint denoising, rather than as a post-hoc fusion step.
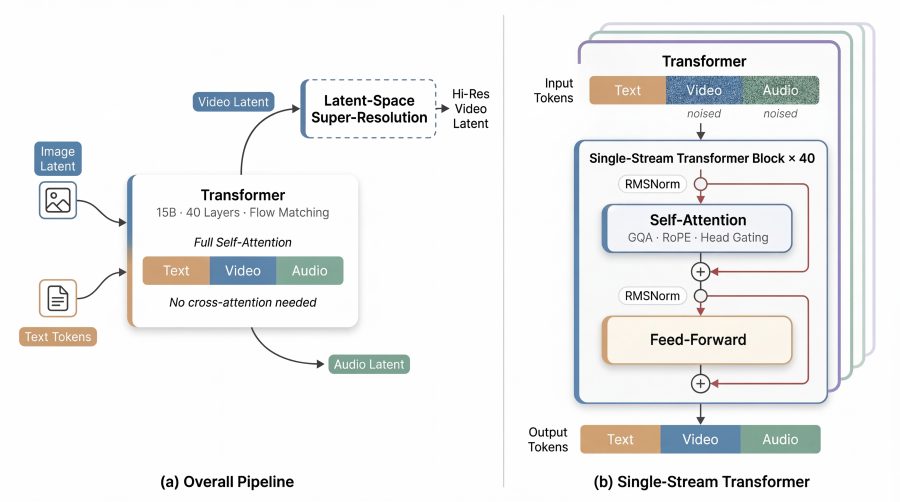
How the transformer is structured
The model has 15 billion parameters and 40 layers. The authors use a sandwich layout: the first and last 4 layers use modality-specific projections and RMSNorm normalization parameters to correctly read and write each modality, while the middle 32 layers share weights across all modalities. This is where deep multimodal mixing of latent representations — including the acoustic-visual alignment required for lip sync — takes place.
Two more non-standard design choices. First — the model operates without an explicit timestep embedding: instead of telling the model which denoising step it is on, the model infers its current state directly from the noisy latent inputs. Second — per-head gating: the output of each attention head is weighted by a learned scalar coefficient passed through a sigmoid. Formally, the output of the h-th head is multiplied by σ(g_h), where g_h is a learned parameter. This improves numerical stability during training while adding minimal computational overhead.
How the model generates fast lip sync video
Generating high-resolution lip sync video from scratch is expensive — the token count grows quadratically with resolution. The authors address this through latent-space super-resolution: the base model first generates video at low resolution (256p), then a dedicated super-resolution module refines the latent in 5 additional denoising steps directly in latent space — without an extra encode-decode pass through the variational autoencoder (VAE). Audio participates in super-resolution as an auxiliary signal, which is especially important for preserving lip sync accuracy when upscaling from coarse base-resolution frames.
Additional optimizations include: the Turbo VAE decoder (a lightweight re-trained decoder that substantially reduces decoding overhead), full computation graph compilation via MagiCompiler (~1.2× speedup on H100), and DMD-2 distillation — the distilled model runs in just 8 denoising steps without classifier-free guidance (CFG).
The result: on a single H100, the distilled model generates a 5-second lip sync video at 256p in 2 seconds, at 540p in 8 seconds, and at 1080p in 38.4 seconds.
How to run lip sync generation yourself
The authors offer two ways to run the model locally. The first is Docker: the team has prepared a sandai/magi-compiler image with a pre-configured environment where you simply mount the model weights folder. The second is conda with Python 3.12 and PyTorch 2.9. Both require Flash Attention for the Hopper architecture and MagiCompiler — Sand.ai’s own computation graph compiler responsible for the 1.2× speedup on H100.
Once installed, the repository includes ready-to-run scripts for each mode: base model at 256p, distilled model (8 steps, no CFG), super-resolution to 540p, and super-resolution to 1080p — each runs with a single bash command. Weights need to be downloaded from Hugging Face and paths set in the config files under example/.
How well does lip sync quality hold up?
For video quality, the authors used the VerseBench benchmark with VideoScore2 metrics (visual quality, text alignment, physical consistency). For audio and lip sync quality, they evaluated on TalkVid-Bench using WER — the share of incorrectly transcribed words in generated speech, where lower means cleaner and more intelligible output. daVinci-MagiHuman leads on three out of four metrics, with a WER of 14.60% — nearly three times lower than Ovi 1.1’s 40.45%, reflecting substantially better lip sync and speech clarity.
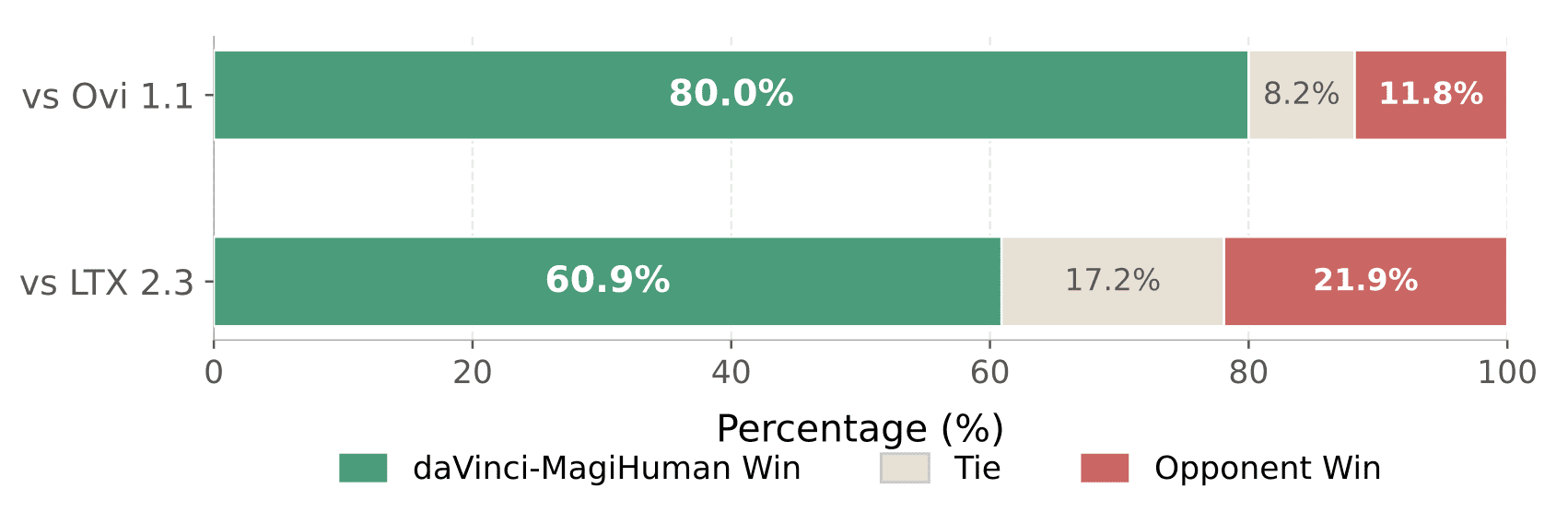
Beyond automatic metrics, the authors ran a pairwise human evaluation. Ten raters assessed 2,000 pairs of clips — 100 comparisons against each competitor per rater. daVinci-MagiHuman won 80.0% of comparisons against Ovi 1.1 and 60.9% against LTX 2.3.
Conclusion
daVinci-MagiHuman demonstrates that a single-stream architecture is not just simpler — it is also a more natural fit for lip sync generation, where speech and facial motion must be learned as a unified signal rather than fused after the fact. A single transformer is easier to optimize, easier to scale, and easier for the community to reproduce. The full stack released under Apache 2.0 — base model, distilled version, super-resolution module, and code — makes this especially valuable for researchers and developers working on lip sync video generation.




