
The Institute of Technological Innovations from the UAE has unveiled Falcon 180B, the largest open language model, displacing Llama 2 from the top spot in the rankings of pre-trained open-access language models by HuggingFace. The model was trained on 3.5 trillion tokens using the RefinedWeb dataset. Falcon boasts 180 billion parameters, which is 2.6 times more than the previous leader, Llama 70B, requiring 8 Nvidia A100 GPUs and 400GB of space for inference. You can test the model on HuggingFace, and the model’s code is also available there.
Model Architecture
Falcon 180B, a fine-tuned version of Falcon 40B, utilizes a multi-query attention mechanism for enhanced scalability. The conventional multi-head attention scheme features one query, key, and value for each head, whereas the multi-query approach uses a single key and value for all “heads.”
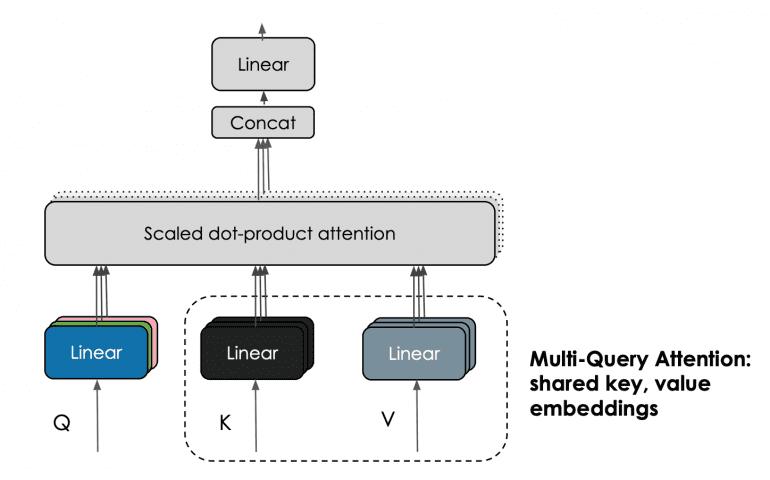
The model was trained on 4096 GPUs, which took approximately 7,000,000 GPU hours on Amazon SageMaker. Compared to Llama 2, training Falcon 180B required four times more computational power.
The dataset for Falcon 180B primarily comprises web data from the RefinedWeb dataset (approximately 85%). Additionally, selected data, including dialogues, technical articles, and code, were used, making it a versatile model for NLP tasks (around 3%).
Falcon 180B Results

Falcon 180B outperforms Llama 2 70B and GPT-3.5 from OpenAI on the MMLU benchmark, although it falls behind GPT-4. It also competes successfully with Google’s proprietary PaLM 2-Large on benchmarks such as HellaSwag, LAMBADA, WebQuestions, Winogrande, PIQA, ARC, BoolQ, CB, COPA, RTE, WiC, WSC, and ReCoRD:
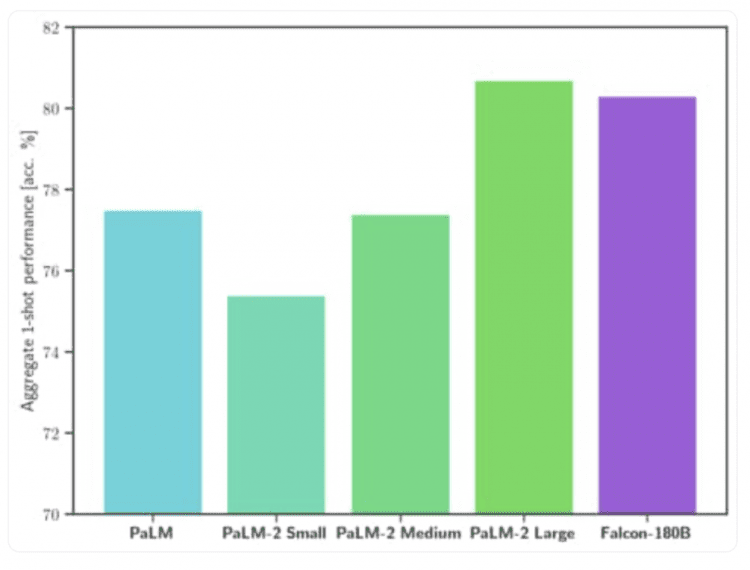
Although Falcon 180B is available on the Hugging Face Hub, its commercial usage is highly restricted. It is advisable to review the license and seek legal counsel for commercial purposes.









ررررروووووعه
How on GPT?
Gpt 3.5 is 175B params will falcon is 180
Google Bard 137B parameter