Language models typically undergo two stages of training: unsupervised pretraining and fine-tuning to specific tasks and user preferences. The novel LIMA method (Less Is More for Alignment) challenges the traditional understanding of model training by proposing a hypothesis that can revolutionize the process.
Superficial Alignment Hypothesis
The Superficial Alignment Hypothesis suggests that most knowledge and skills of models are acquired during unsupervised pretraining. An important aspect of fine-tuning models for specific tasks is teaching them to select appropriate response formats. If this hypothesis holds true, fine-tuning a pretrained language model on a dataset containing just 1000 examples should suffice.
During the study of the LIMA method, researchers conducted experiments to validate this hypothesis. They pretrained the model using unsupervised pretraining and utilized a small set of examples to fine-tune it for specific tasks and user stylistic preferences.
LIMA Results
To test the Superficial Alignment Hypothesis, researchers selected 1000 examples resembling real user queries along with high-quality corresponding answers. The set consisted of 750 top-quality questions and answers extracted from forums like Stack Exchange and wikiHow, ensuring answer quality and topic diversity. Additionally, 250 examples were manually generated to provide a range of tasks and highlight a consistent AI-assistant-style response. The LIMA model, pretrained with LLaMa (a model with 65 billion parameters), underwent fine-tuning on this 1000-example dataset.
Researchers discovered that adding just 30 dialogue examples to the initial 1000 examples was sufficient to transition from following instructions to engaging in dialogue with users.

Remarkably, the LIMA model achieved high performance using only a small set of examples. It learned to produce responses in specific formats, including complex queries related to travel planning or speculations about alternative history. Furthermore, the model demonstrated strong generalization capabilities on unfamiliar tasks not included in the training data.
Comparison to State-of-the-Art Models
To compare LIMA with other models, researchers generated a single response for each test prompt. Volunteers then compared the responses of LIMA with those of other base models and selected the preferred one. The experiment was repeated with GPT-4 replacing the volunteers:
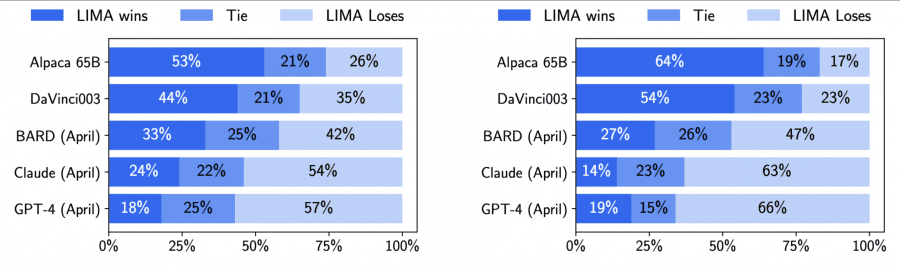
Volunteers found the responses from the LIMA model to be equivalent or even preferable compared to other state-of-the-art models such as GPT-4, Bard, and DaVinci003. When comparing against GPT-4, LIMA achieved better or equal results in 43% of cases, while against Bard and DaVinci003, this statistic reached 58% and 65% respectively.
The study revealed that the quality of the model’s output could significantly vary depending on the input, even when using 2000 examples. Particularly, a notable difference was observed between filtered and unfiltered answers from Stack Exchange:
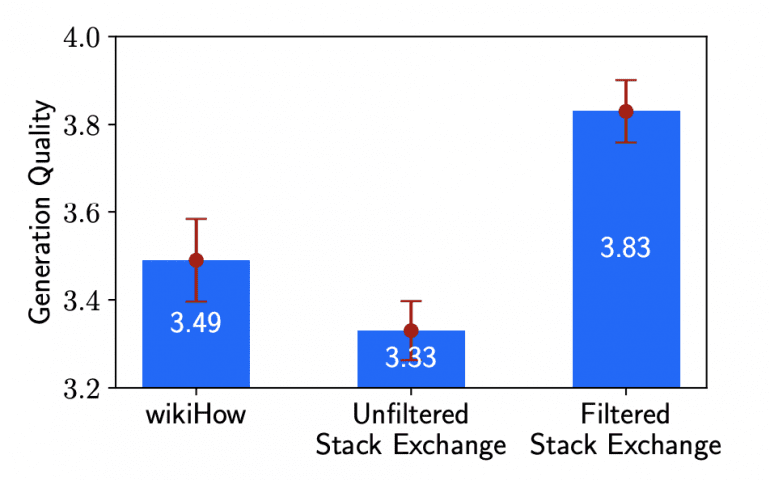
The research findings confirm the Superficial Alignment Hypothesis and indicate that a substantial portion of knowledge in large language models is acquired during unsupervised pretraining. Training a model on just 1000 examples can enable it to generate high-quality output for a specific task. This has the potential to substantially reduce training costs and make the process more efficient and accessible.
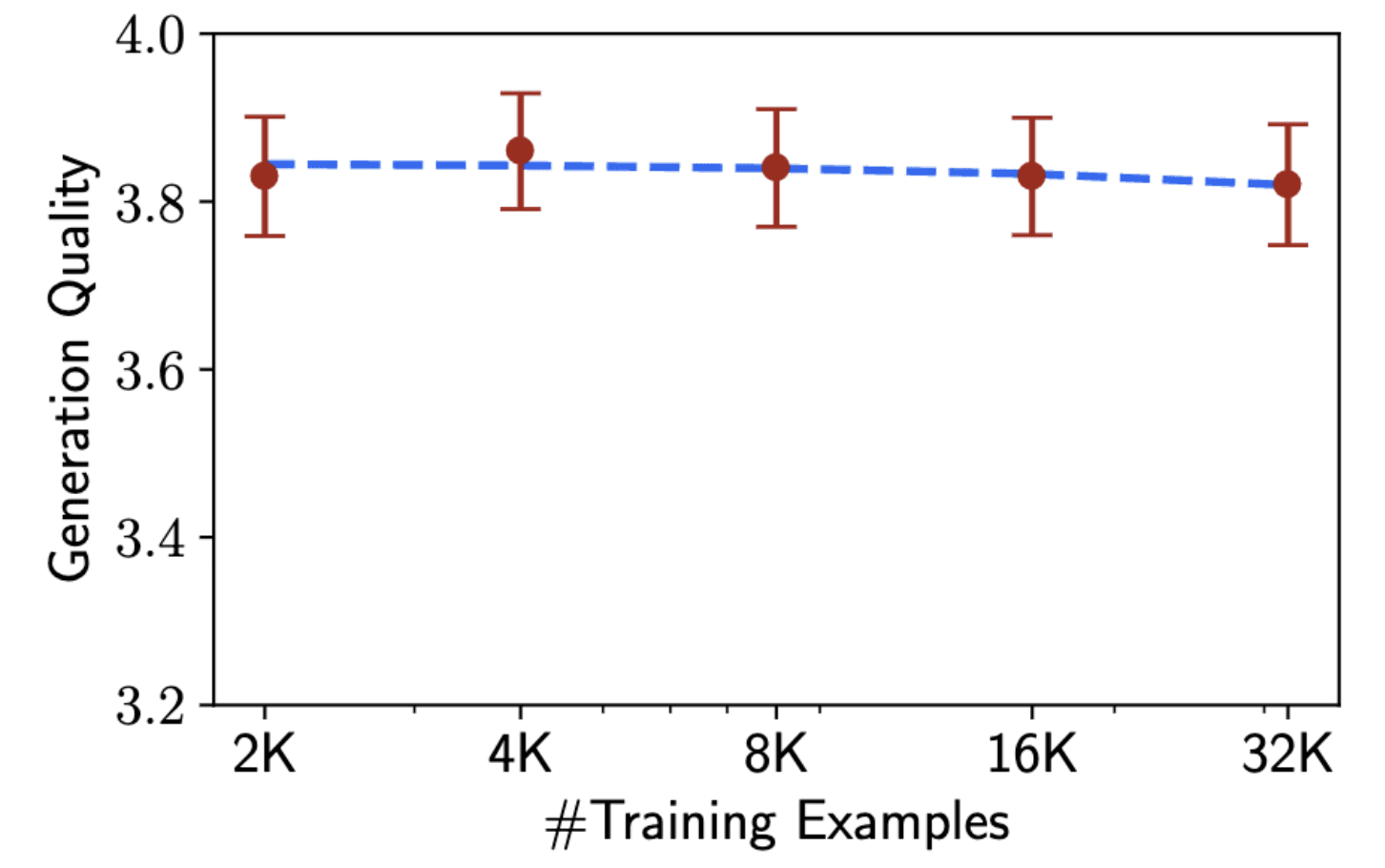
However, further research in this field is necessary to validate the LIMA method through additional experiments. Continued investigations may expand upon these findings and improve training methods for language models.
The LIMA method opens up new perspectives in language model training and could lead to the development of more efficient and accurate models. Confirming the Superficial Alignment Hypothesis will deepen our understanding of the model training process and optimize them for various natural language processing tasks.