A wide variety of images around us are the outcome of interactions between lighting, shapes and materials. In recent years, the advent of convolutional neural networks (CNN) has led to significant advances in recovering shape using just a single image. One of the problems which didn’t get much attention is material estimation which has not seen as much progress, which might be attributed to multiple causes. First, material properties can be more complex. Even discounting more complex global illumination effects, materials are represented by a spatially-varying bidirectional reflectance distribution function (SVBRDF), which is an unknown high-dimensional function that depends on incident lighting directions. Secondly, pixel observations in a single image contain entangled information from factors such as shape and lighting, besides material, which makes estimation ill-posed.
The researchers from Adobe developed a state-of-the-art technique to recover SVBRDF from a single image of a near-planar surface, acquired using the camera of the mobile phone. This is a contrast to conventional BRDF captures setups that usually require significant equipment and expenses. Convolutional Neural Networks is specifically designed to account for the physical form of NDRFs and the interaction of light with materials.
How It Works
A state of the art novel architecture that encodes the input image into a latent representation, which is decoded into components corresponding to surface normal, diffuse texture and specular roughness. The experiments demonstrate advantages over several baselines and prior works in quantitative comparisons, while also achieving superior qualitative results. The generalization ability of this network trained on the synthetic BRDF dataset is demonstrated by strong performance on real images, acquired in the wild, in both indoor and outdoor environments, using multiple different phone cameras. Given the estimated BRDF parameters, authors also demonstrate applications such as material editing and relighting of novel shapes. To summarise, the authors propose the following contributions:
- A novel lightweight SVBRDF acquisition method that produces state-of-the-art reconstruction quality.
- A CNN architecture that exploits domain knowledge for joint SVBRDF reconstruction and material classification.
- Novel DCRF-based post-processing that accounts for the microfacet BRDF model to refine network outputs.
- An SVBRDF dataset that is large-scale and specifically attuned to the estimation of spatially-varying materials.
Setup: Our goal is to reconstruct the spatially-varying BRDF of a near planar surface from a single image captured by a mobile phone with the flash turned on for illumination. Authors assume that the z-axis of the camera is approximately perpendicular to the planar surface (they explicitly evaluate against this assumption in our experiments). For most mobile devices, the position of the flashlight is usually very close to the position of the camera, which provides us with a univariate sampling of anisotropic BRDF. Our surface appearance is represented by a microfacet parametric BRDF model. Let di, ni, ri be the diffuse colour, normal and roughness, respectively, at pixel i. The BRDF model is defined as:
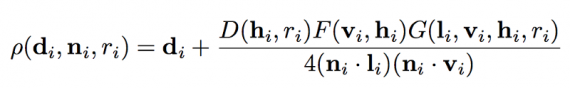
Where vi and li are the view and light directions and hi is the half-angle vector. Given an observed image I (di, ni, ri, L), captured under unknown illumination L, scientists wish to recover the parameters di, ni and ri for each pixel i in the image.
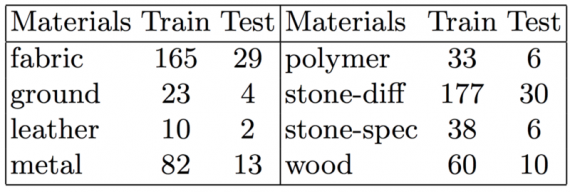
Dataset: The dataset has been used is Adobe Stock 3D Material dataset which contains 688 materials with high resolution (4096 x 4096) spatially-varying BRDFs. Scientists use 588 materials for training and 100 materials for testing. For data augmentation, authors randomly crop 12, 8, 4, 2, 1 image patches of size 512, 1024, 2048, 3072, 4096. The distribution is shown in figure 2.
Network Design
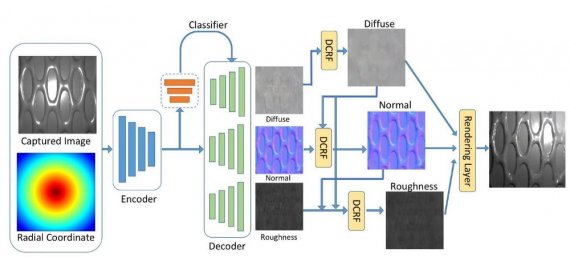
The basic network architecture consists of a single encoder and three decoders which reconstruct the three spatially-varying BRDF parameters: diffuse colour di, normal ni and roughness ri. The intuition behind using a single encoder is that different BRDF parameters are correlated, thus, representations learned for one should be useful to infer the others, which allows a significant reduction in the size of the network. The input to the network is an RGB image, augmented with the pixel coordinates as a fourth channel. Authors add the pixel coordinates since the distribution of light intensities is closely related to the location of pixels, for instance, the centre of the image will usually be much brighter. Since CNNs are spatially invariant, they need the extra signal to let the network learn to behave differently for pixels at different locations. Skip links are added to connect the encoder and decoders to preserve details of BRDF parameters. To this end, our encoder network has seven convolutional layers of stride 2, so that the receptive field of every output pixel covers the entire image.
For each BRDF parameter, authors have an L2 loss for direct supervision. For each batch, researchers create novel lights by randomly sampling the point light source on the upper hemisphere. This ensures that the network does not overfit to collocated illumination and is able to reproduce appearance under other light conditions. The final loss function for the encoder-decoder part of our network is:
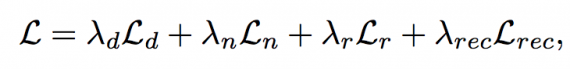
Where
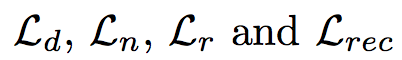
are the L2 losses for diffuse, normal, roughness and rendered image predictions, respectively. Given the highest level of features extracted by the encoder, the features are sent to a classifier to predict its material type. Then to evaluate the BRDF parameters for each material type and use the classification results as weights (the output of SoftMax layer). This averages the prediction from different material types to obtain the final BRDF reconstruction results. The classifier is trained together with the encoder and decoder from scratch, with the weights of each label set to be inversely proportional to the number of examples in figure 2 to balance different material types in the loss function. The overall loss function of our network with the classifier is:
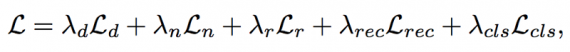
Results
Acquisition setup: To verify the generalizability of our method to real data, we show results on real images captured with different mobile devices in both indoor and outdoor environments. Authors capture linear RAW images (with potentially clipped highlights) with the flash enabled, using the Adobe Lightroom Mobile app. The mobile phones were hand-held, and the optical axis of the camera was only approximately perpendicular to the surfaces (See fig 4)

Qualitative results with different mobile phones: Figure 5 presents SVBRDF and normal estimation results for real images captured with three different mobile devices: Huawei P9, Google Tango and iPhone 6s. Scientists observe that even with a single image, our network successfully predicts the SVBRDF and normals, with images rendered using the predicted parameters, appear very similar to the input. Also, the exact same network generalizes well to different mobile devices, which shows that our data augmentation successfully helps the network factor out variations across devices. For some materials with specular highlights, the network can hallucinate information lost due to saturation. The network can also reconstruct reasonable normals even for complex instances.