The Microsoft Research team introduced On-Policy RL with Optimal reward baseline (OPO) — a simplified reinforcement learning algorithm for aligning large language models. The new method addresses key problems of modern RLHF algorithms: training instability due to loose on-policy constraints and computational inefficiency due to auxiliary models. Code implementation is available on GitHub.
Problems with Modern RLHF Algorithms
Reinforcement Learning from Human Feedback (RLHF) is a foundational approach for aligning large language models with human preferences. The standard RLHF pipeline typically includes supervised fine-tuning followed by reinforcement learning, often using the Proximal Policy Optimization (PPO) algorithm, guided by a trained reward model.
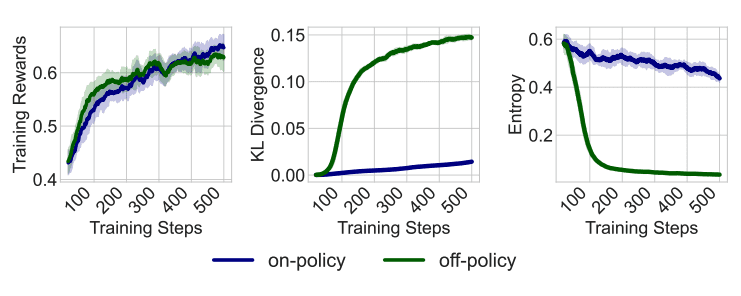
Modern RLHF algorithms face serious challenges in stability and efficiency. PPO requires training an additional value model to estimate advantages, creating additional computational overhead. Methods are often prone to instability due to loose on-policy constraints. The on-policy principle means that policy gradients should be computed on data collected by the current policy, i.e., the probabilistic distribution formula that the model assigns to different possible answers y for a given input x. Loose on-policy constraints lead to violations of this principle – using data from previous policy versions, which technically makes training off-policy. As a result, the model begins generating very similar, monotonous responses, changes its behavior too abruptly between updates, and even degrades its original capabilities.
Key OPO Innovations
Strict On-Policy Training
OPO uses strict on-policy training, which empirically stabilizes the training process and significantly enhances exploration capabilities. Unlike PPO, which collects a batch of data with the current policy and then performs multiple gradient updates on this fixed batch, strict on-policy training ensures that each gradient step is computed using fresh data sampled from the current policy.
This contrasts with conventional policy gradient methods, which introduce off-policy divergence during repeated rollouts. In practice, this can contribute to sample entropy collapse and large policy shifts, requiring explicit entropy regularization.
Optimal Reward Baseline
The team developed a mathematically optimal baseline that theoretically minimizes gradient variance. The idea is to subtract a special reference value from each reward that doesn’t affect the learning direction but makes the process more stable.
The optimal baseline b* is calculated using the formula:
b* = E[||∇θ log πθ(y|x)||² · r(x,y)] / E[||∇θ log πθ(y|x)||²]This is a weighted average of rewards, where the weights are the squared gradients of the model.
Simplification for Text Generation
For language tasks, a simpler formula can be used. The researchers assumed that the influence of each word on training is approximately equal, so the total influence of a response is proportional to its length. As a result, the optimal baseline formula simplifies to:
b* = E[ly · r(x,y)] / E[ly]where ly is the length of response y in tokens.
Thus, longer responses receive greater weight in the calculation. This means that the quality of long responses has a stronger influence on what the model considers a “normal” level of performance.
Experimental Results
The researchers tested the algorithm on the DeepSeek-R1-Distill-Qwen-7B model using the mathematical subset from Skywork-OR1-RL-Data (48 thousand tasks). A simple reward function was applied: 1 for correct answers, 0 for incorrect ones. Performance was evaluated on three mathematical benchmarks: MATH-500, AIME 2024, and AIME 2025.
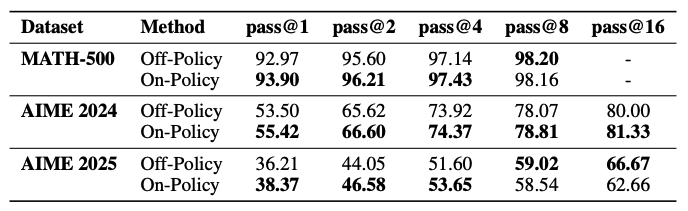
Strict on-policy training significantly outperforms off-policy training on the pass@1 metric across all tests. For example, on AIME 2024, the strict approach showed 55.42% versus 53.50% for off-policy training.
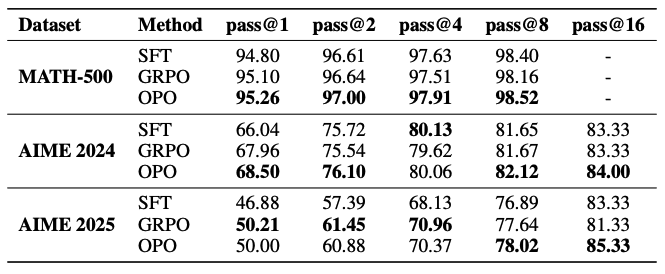
The algorithm with OPO outperforms Group Relative Policy Optimization (GRPO) in most cases. On MATH-500, OPO achieved 95.26% pass@1 versus 95.10% for GRPO. Advantages are particularly noticeable when the model is given multiple attempts to solve a task: on AIME 2025 with 16 attempts, the algorithm achieved 85.33% success versus 81.33% for group relative policy optimization.
Additional Benefits
The algorithm generates more diverse and less repetitive responses while maintaining more stable training dynamics with lower Kullback-Leibler divergence and higher entropy of output data compared to existing methods.