Image-to-image translation is the task of mapping an image from a source domain to a target domain. Applications include image colorization, image super-resolution, style transfer, domain adaptation and data augmentation. Most of the approaches require data from each domain to be paired or under alignment, e.g., when translating satellite images to topographic maps, which restricts applications and may not even be possible for some domains. Unsupervised approaches, such as DiscoGAN and CycleGAN overcome this problem with cyclic losses which encourage the translated domain to be faithfully reconstructed when mapped back to the original domain. Existing algorithms feed an input image to an encoder–decoder-like neural network architecture called the generator, which tries to translate the image. Then, this output is fed to a discriminator which attempts to classify if the output image has indeed been translated.
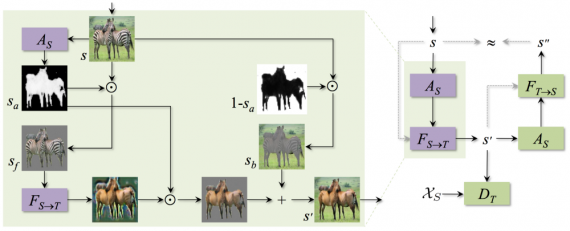
However, these approaches are limited by the system’s inability to attend only to specific scene objects. In the unsupervised case, where images are not paired or aligned, the network must additionally learn which parts of the scene are intended to be translated. For example, in Figure 1, a convincing translation between the horse and zebra domains requires the network to attend to each animal and change only those parts of the image. This is challenging for existing approaches, even if they use a localized loss like PatchGAN, as the network itself has no explicit attention mechanism. Instead, they typically aim to minimize the divergence between the underlying data-generating distribution for the entire image in the source and target domains. To overcome this limitation, a new approach is introduced which minimize the divergence between only the relevant parts of the data-generating distributions for the source and target domains.
Architecture Design
The goal of image translation is to estimate a map F(S→T) from a source image domain S to a target image domain T based on independently sampled data instances X(S) and X(T), such that the distribution of the mapped instances F(S→T) (XS) matches the probability distribution P(T) of the target. The training of the transfer network F(S→T) requires a discriminator D(T) to try to detect the translated outputs from the observed instances X(T). For cycle consistency, the inverse map F(T→S) and the corresponding discriminator D(S) are simultaneously trained. Solving this problem requires solving two equally important tasks:
- (1) locating the areas to map in each image, and
- (2) applying the right mapping to the located areas.
To achieve this, two attention networks A(S) and A(T), which select areas to translate by maximizing the probability that the discriminator makes a mistake.
Attention-guided generator
Input images are feed into attention network A(s), resulting in the attention map s(a) =AS(s). the mapped image s` is obtained by:
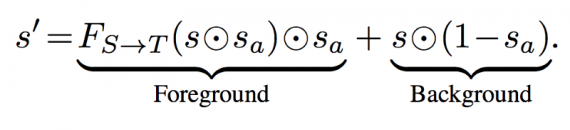
The ‘foreground’ object s(f) is obtained via an element-wise product on each RGB channel: s(f) =s(a)⊙s. Then, the foreground s(f) is fed into the generator F(S→T), which maps sf to the target domain T. To create background image s(b) = (1−s(a))⊙s, and add it to the masked output of the generator F(S→T).
Loss function: This process is governed by the adversarial energy:
![]()
Attention-guided discriminator
This added loss makes our framework more robust in two ways: (1) it enforces the attended regions in the generated image to conserve content (e.g., pose), and (2) it encourages the attention maps to be sharp (converging towards a binary map), as the cycle-consistency loss of unattended areas will always be zero.
The final energy is obtained loss by combining the adversarial and cycle-consistency losses for both source and target domains are as follows:
![]()
With a continuous attention map, the discriminator may receive ‘fractional’ pixel values, which may be close to zero early in training. While the generator benefits from being able to blend pixels at object boundaries, multiplying real images by these fractional values cause the discriminator to learn that mid gray is ‘real’ (i.e., we push the answer towards the midpoint 0 of the normalized [−1,1] pixel space). The learned attention map for the discriminator is as follows:
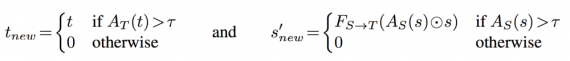
Thus, the updated adversarial energy L(adv) are as follows:
![]()
Result
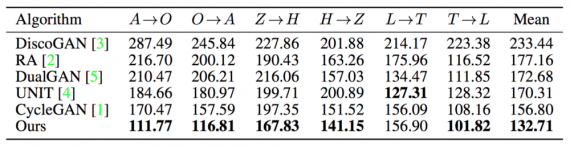
Fréchet Inception Distance (FID) is used to evaluate the image translation framework. FID computes the Fréchet distance between feature representations of real and generated images. Such feature representations are extracted from the last hidden layer of the Inception architecture. This approach achieves the lowest FID in all but one mapping, with CycleGAN as the next best performing approach. UNIT achieves the second-lowest FID value, which suggests that the latent space assumption is useful in this setting. The code can be found here.
While modern unsupervised image-to-image translation techniques can map relevant image regions, they also inadvertently map irrelevant regions, too. By doing so, the generated images fail to look realistic, as the background and foreground are generally not appropriately blended. By incorporating an attention mechanism into unsupervised image-to-image translation, this approach demonstrates significant improvements in the quality of generated images.



Apples to orange

Bonus — results for ablation experiments
By only adopting the holistic image discriminator (‘Ours–D’), the attention networks start to focus on the background as shown in the bottom row: