Researchers from NVIDIA and MIT’s Computer Science and Artificial Intelligence Lab have proposed a novel method for video-to-video synthesis, showing impressive results. The proposed method – Vid2Vid – can synthesize high-resolution, photorealistic, temporally coherent videos on a diverse set of input formats including segmentation masks, sketches, and poses.
Previous works
Due to the inherent complexity of the problem of video-to-video synthesis, this topic remained relatively unexplored in the past. Compared to its image counterpart – image-to-image synthesis, much fewer studies have explored and tackled this problem.
Arguing that a general-purpose solution to video-to-video synthesis has not yet been explored in the prior work (as opposed to the image counterpart – image-to-image translation), the researchers compare and benchmark this approach with a strong baseline that combines a state-of-the-art video style transfer algorithm with a state-of-the-art image-to-image translation approach.
State-of-the-art idea
The general idea is to learn a mapping function that can convert an input video to a realistic output video. They frame this problem as a distribution matching problem, and they leverage the generative adversarial learning framework to produce a method that can generate photorealistic videos given an input video (such as a sequence of segmentation masks, poses, sketches, etc.).

Vid2Vid Method
As I mentioned before, the authors proposed a method based on Generative Adversarial Networks. They tackle the complex problem of video-to-video translation or video-to-video synthesis in a really impressive way by carefully designing an adversarial learning framework.
Their goal is to learn a mapping function that will map a sequence of input (source) images to a series of realistic output images, where the conditional distribution of the generated sequence given the source sequence is identical to the distribution of the original sequence given the source sequence:
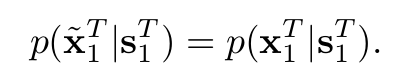
The matching of the distributions enforces the method to learn to output realistic and temporally coherent output videos. In a generative adversarial learning context, a Generator-Discriminator framework is designed to learn the mapping function. The generator is trained by solving an optimization problem – minimizing the Jensen-Shannon divergence between the two distributions. A minimax optimization is applied to a defined objective function:
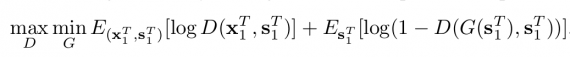
As mentioned in their paper, also widely known, optimizing for an objective function as the given one is a very challenging task. Often, the training of a generator and discriminator models becomes very unstable or even impossible depending on the optimization problem being solved. Therefore, in their research, they propose a simplified sequential generator making a few assumptions. They make the Markov property assumption to factorize the conditional distribution and decouple the dependencies across frames in the sequences.
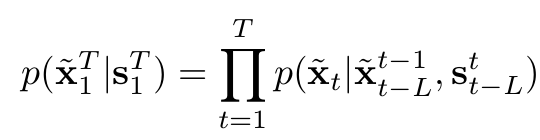
In simple words, they simplify the problem by assuming that the video frames can be generated sequentially and the generation of the t-th frame only depends on three things: 1) the current source image, 2) the past L source images, and 3) the past L generated images.
From this point, they design a feed-forward network F to learn a mapping from the past L source images, and the past L-1 generated images to a newly generated output image.
By the way, Neurohive is creating the new app for professional business headshots based on neural network. We are going to release it in September.
To model such a network, researchers make another assumption based on the fact that if the optical flow from the current frame to the next frame is known, it can be used to warp the current frame to generate an estimation of the next frame. Arguing that this will be largely true except for occluded areas (where it is unknown what is happening), they are considering a specific model.
The estimation network F is modeled in such a way to take into account a given occlusion mask, the estimated optical flow between the previous and the current image (which is given by an optical flow estimation function) and a hallucinated image (generated from scratch). The hallucinated image is necessary to fill the areas under occlusions.
Similarly as in images, wherein the context of generative adversarial learning many methods exploit local discriminators besides a global one, here the authors propose an interesting approach utilizing conditional image discriminator and conditional video discriminator.
Additionally, to make their method even better and more impressive, the researchers extend their approach to multimodal synthesis. They propose a generative method based on feature embedding scheme and using a Gaussian Mixture Models, to output several videos with different visual appearances depending on sampling different feature vectors.
Results
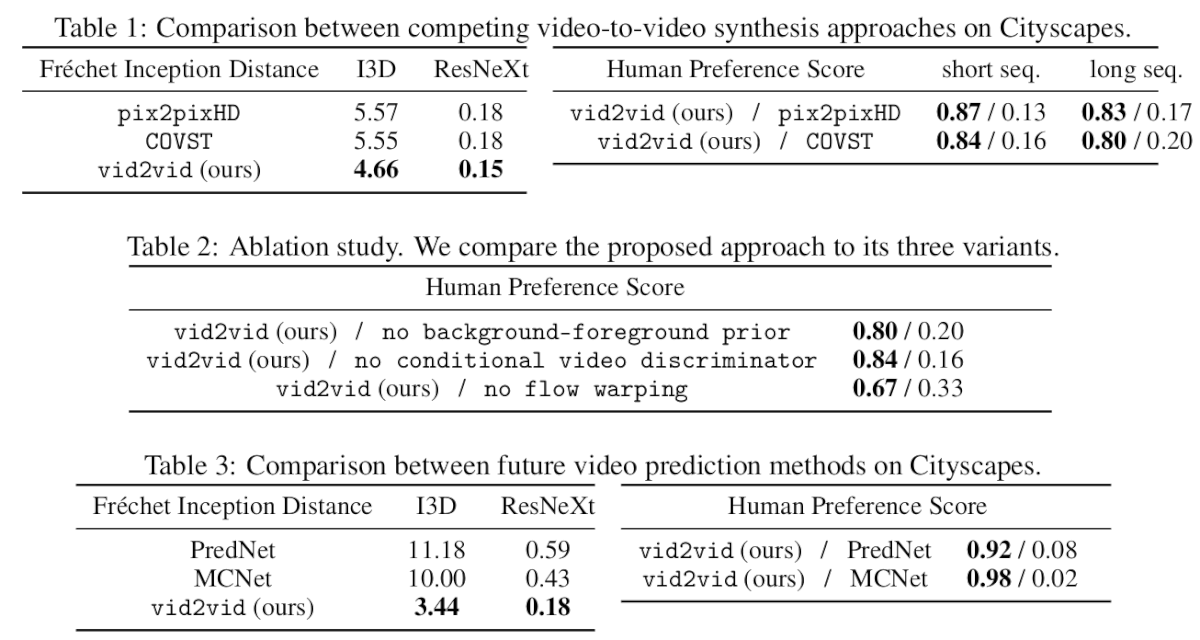
The proposed method yields impressive results. It was tested on several datasets such as Cityscapes, Apolloscape, Face video dataset, Dance video dataset. Moreover, two strong baselines were used for comparison: pix2pix method and modified video style transfer method (CONVST) where they changed the stylization network to pix2pix.



Comparison with other state-of-the-art
They use both subjective and objective evaluation metrics for performance evaluation: Human preference score, Fréchet Inception Distance (FID). A comparison between the proposed and other methods is given in the tables.


Conclusion
A new state-of-the-art method in video synthesis has been proposed. The conditional GAN-based approach shows impressive results in several different tasks within the scope of video-to-video translation. There are numerous applications of this kind of methods in computer vision, robotics, and computer graphics. Using a learned video synthesis model, one can generate realistic videos for many different purposes and applications.