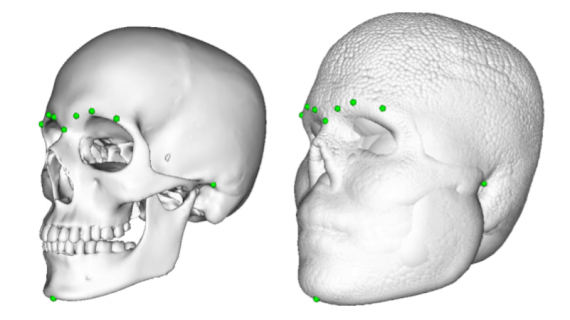
The 3D Morphable Model (3DMM) is a statistical model of 3D facial shape and texture. 3D Morphable Models have various applications in many fields including computer vision, computer graphics, human behavioral analysis, craniofacial surgery.
In essence, 3D Morphable Models are used to model facial shapes and textures and modeling human faces is not a trivial task at all. Different identities, highly-variable face shapes, and postures make the modeling of the human face a challenging task. In this context, a 3D Morphable Model is trying to learn a model of facial shape and texture in a space where there are explicit correspondences. This means, there has to be a point-to-point correspondence between the reconstruction and all other models, enabling morphing, and second, it has to model the underlying transformations between types of faces (male to female, neutral to smile, etc.).

Researchers from Michigan State University propose a novel Deep Learning-based approach to learning a 3D Morphable Model. Exploiting the power of Deep Neural Networks to learn non-linear mappings, they suggest a method for learning 3D Morphable Model out of just 2D images from in-the-wild (images not taken in a controlled environment like a lab).
Previous Approaches
A conventional 3DMM is learned from a set of 3D face scans with associated well-controlled 2D face images. Traditionally, 3DMM is learned through supervision by performing dimension reduction, typically Principal Component Analysis (PCA), on a training set of co-captured 3D face scans and 2D images. By employing a linear model such as PCA, non-linear transformations and facial variations cannot be captured by the 3D Morphable Model. Moreover, large amounts of high-quality 3D data are needed to model highly variable 3D face shapes.
State of the art idea
The idea of the proposed approach is to leverage the power of Deep Neural Networks or more specifically Convolutional Neural Networks (which are more suitable for the task and less expensive than multilayer perceptrons) to learn the 3D Morphable Model with an encoder network that takes a face image as input and generates the shape and albedo parameters, from which two decoders estimate shape and albedo.
Method
As mentioned before a linear 3DMM has the problems such as the need of 3D face scans for supervised learning, unable to leverage massive in-the-wild face images for learning, and the limited representation power due to the linear model (PCA). The proposed method learns a nonlinear 3 DMM model using only large-scale in-the-wild 2D face images.
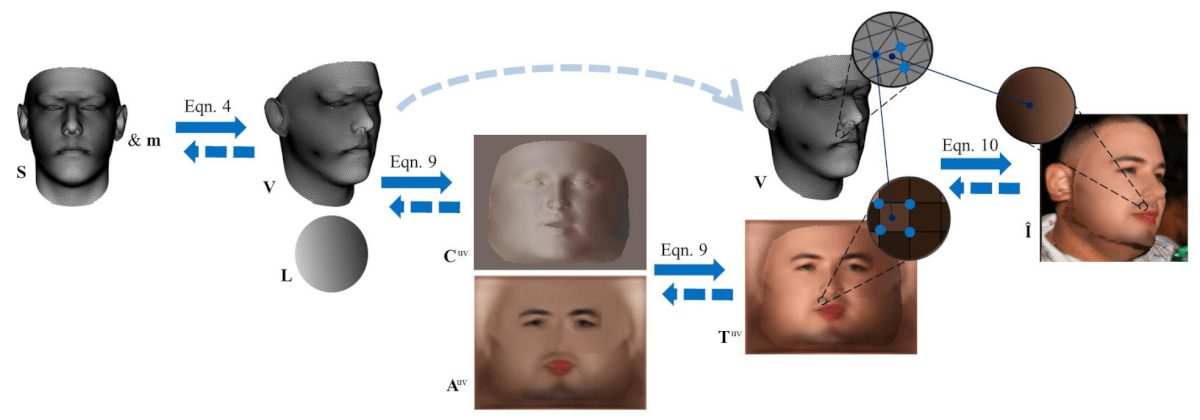
UV Space Representation
In their method, the researchers use an unwrapped 2D texture (where 3 D vertex v is projected onto the UV space) as a texture representation for the shape and the albedo. They argue that keeping the spatial information is very important as they employ Convolutional Networks in their method and frontal face-images contain little information about the two sides. Therefore their choice falls on UV-space representation.

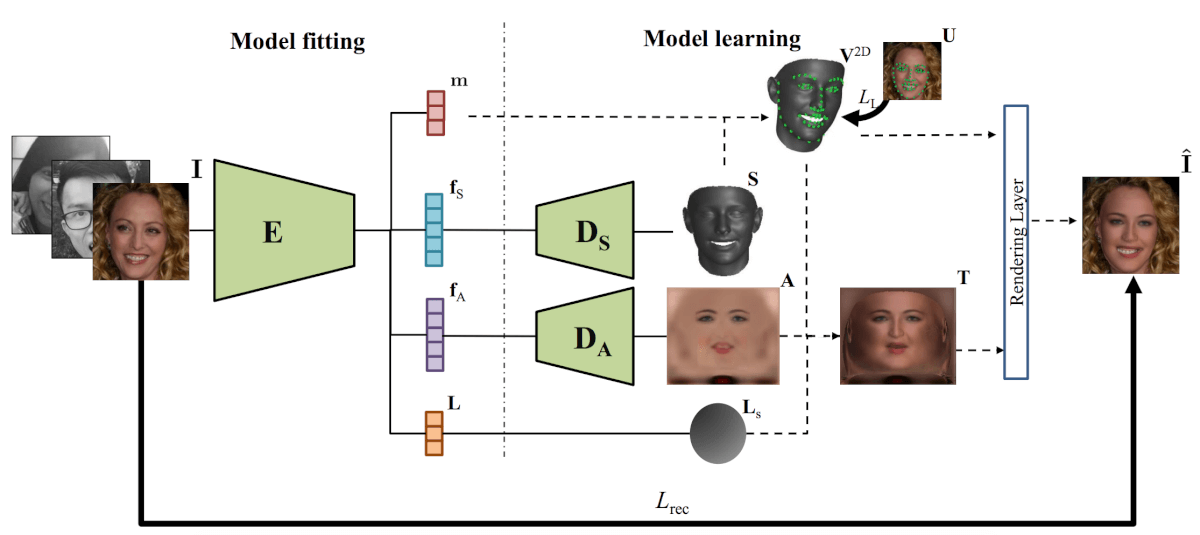
Network architecture
They designed an architecture that given an input image it encodes it into shape, albedo and lightning parameters (vectors). The encoded latent vectors for albedo and shape are decoded using two different Decoder networks (again Convolutional Neural Networks) to obtain face skin reflectance, image (for the albedo) and 3D face mash (for the shape). Then a differentiable rendering layer was designed to generate the reconstructed face by fusing the 3D face, albedo, lighting, and the camera projection parameters estimated by the encoder. The whole architecture is nicely presented in the figure below.
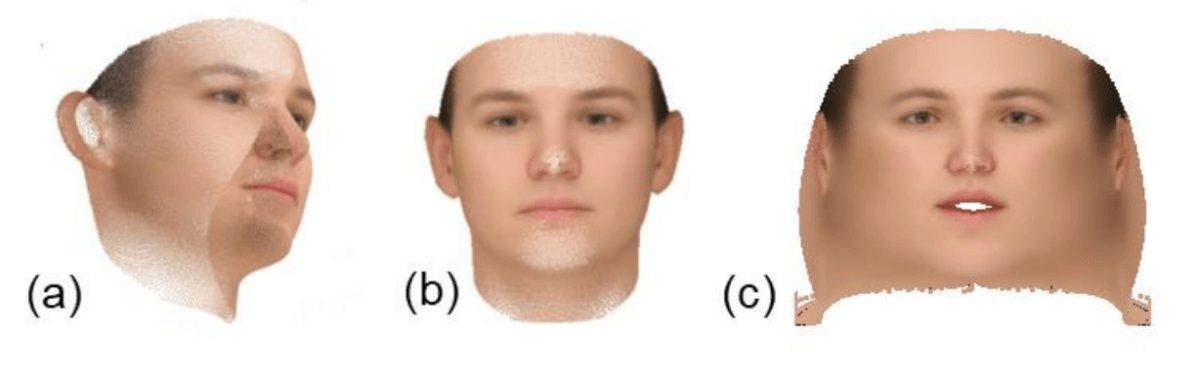
The presented robust, learning of a non-linear 3D Morphable Model is applied to 2D Face Alignment, and 3D Face Reconstruction problems. It can also have many applications since it represents a model learning method, which can solve different problems.
Comparison with other methods
The method was evaluated against other methods on the following tasks: 2D Face Alignment, 3D Face Reconstruction and Face Editing. The suggested technique outperforms other state-of-the-art methods on these tasks. Some of the results of the evaluation are presented below.
2D Face Alignment
One of the critical applications of this kind of approach can become face alignment. Alignment naturally should improve facial analysis in a range of tasks (for example face recognition). However, alignment is not a straightforward task, and this method proves successful in face alignment.

3D Face Reconstruction
The approach was also evaluated on another task: 3D Face Reconstruction, yielding outstanding results compared to other methods.




Face Editing
A method that learns a model and decomposes a face image into individual components allows the image to be modified and the face to be edited by manipulating different elements. The method was also evaluated on face editing tasks such as relighting and attribute manipulation.


Conclusions
In conclusion, the proposed method will have a potentially high impact since it improves the way of learning a 3D Morphable Model. This kind of model has been widely adopted in the past since its introduction, but there was not an efficient, robust way of learning this model from in-the-wild data.
The proposed approach exploits the power of deep neural networks as very good function approximator to model the highly variable human face robustly. The unusual path of learning a 3DMM allows different manipulations and many applications of this method, some of which are presented in the paper, and many others are expected.