
Many image-editing and film post-production applications rely on natural image matting as one of the processing steps. The task of the matting algorithm is to estimate the opacity of a foreground object in an image or video sequence accurately. Researchers from Trinity College Dublin propose the AlphaGAN architecture for natural image matting.
In mathematical terms, every pixel i in the image is assumed to be a linear combination of the foreground and background colors:
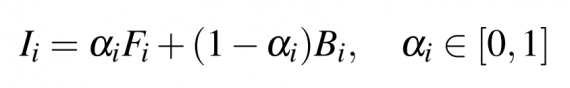
where ai is a scalar value that defines the foreground opacity at pixel i and is referred to as the alpha value.
So, how to solve this equation with so many unknown values? Let’s first discover the current state-of-the-art approaches to solving this problem…
Previous Works
Lots of current algorithms aim to solve the matting equation by treating it as a color-problem following either sampling or propagation approaches.
Sample-based image matting assumes that true foreground and background colors of the unknown pixel can be derived from the known foreground and background samples that are near that pixel. Methods that follow this assumption include:
- bayesian matting;
- iterative matting;
- shared sampling matting;
- sparse coding.
Propagation image matting works by propagating the known alpha value between known local foreground and background samples to the unknown pixels. The examples include:
- poisson matting;
- random walk;
- geodesic matting;
- spectral matting;
- close-form matting;
- fuzzy connectedness matting.
However, the over-dependency on color information can lead to artifacts in images where the foreground and background color distributions overlap.
Thus, recently, several deep learning approaches to the natural image matting were introduced, including:
- a two-stage network consisting of an encoder-decoder stage and a refinement stage by Xu et al.;
- end-to-end CNN for deep automatic portrait matting by Shen et al.;
- end-to-end CNN that utilizes the results deduced from local and non-local matting algorithms by Cho et al.;
- granular deep learning (GDL) architecture by Hu et al.
But is it possible to improve further the performance of these algorithms by applying GANs? Let’s find out now!
State-of-the-art Idea
Lutz, Amplianitis, and Smolić from Trinity College Dublin are the first to propose generative adversarial network (GAN) for natural image matting. Their generator network is trained to predict visually appealing alphas, while the discriminator is trained to classify well-composited images.
The researchers build their approach by improving the network architecture of Xu et al. to better deal with the spatial localization issues inherent in CNNs. In particular, they use dilated convolutions to capture global context information without downscaling feature maps and losing spatial information.
We are now ready to move on to the details of AlphaGAN – this is how Lutz and his colleagues call their image matting algorithm.
Network Architecture
AlphaGAN architecture consists of one generator G and one discriminator D.
The generator G is a convolutional encoder-decoder network that is trained both with the help of the ground-truth alphas as well as the adversarial loss from the discriminator. It takes an image composited from the foreground, alpha and a random background appended with the trimap as 4th-channel as input and attempts to predict the correct alpha. Resnet50 architecture is used for the encoder.
As you can see from the figure below, the decoder part of the network includes skipping connections from the encoder to improve the alpha prediction by reusing local information to capture fine structures in the image.
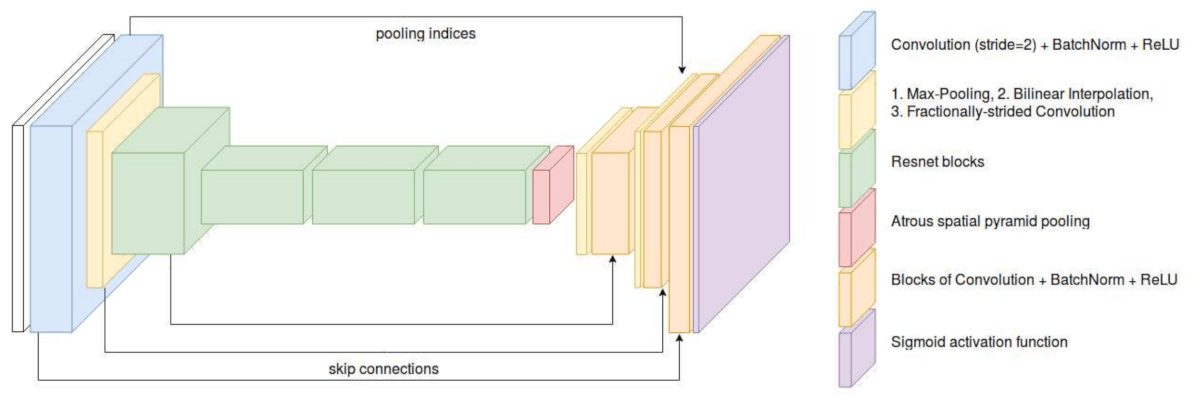
The discriminator D tries to distinguish between real 4-channel inputs and fake inputs where the first three channels are composited from the foreground, background and the predicted alpha. PatchGAN introduced by Isola et al. is used for the discriminator in this network.
The full objective of the network includes alpha-prediction loss, compositional loss, and adversarial loss:
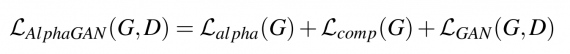
Experimental Results
The proposed method was evaluated based on two datasets:
- the Composition-1k dataset, which includes 1000 test images composed of 50 unique foreground objects;
- the alphamatting.com dataset, which consists of 28 training images and 8 test images; for each set, three different sizes of trimaps are provided, namely, “small” (S), “large” (L) and “user” (U).
The Composition-1k Dataset
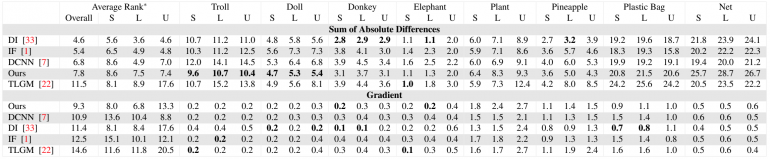
The metrics used include the sum of absolute differences (SAD), mean square error (MSE), gradient and connectivity errors.
The researchers compared their method with several state-of-the-art approaches where there is public code available. For all methods, the original code from the authors was used, without any modifications.

As it can be observed from the table, AlphaGAN delivers noticeably better results than other image matting algorithms selected for comparison. There is only one case (gradient error from the comprehensive sampling approach), where they do not achieve the best result.
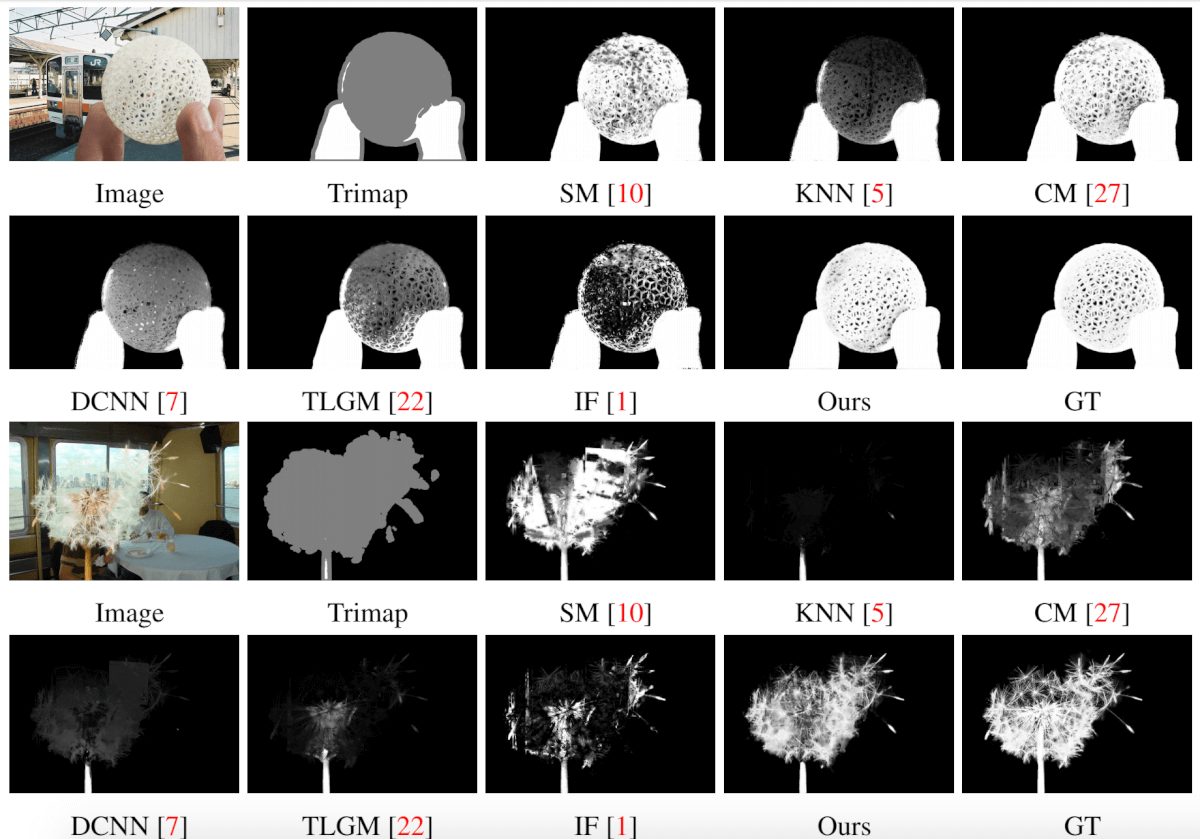
See also some qualitative results of this comparison in the next set of pictures:

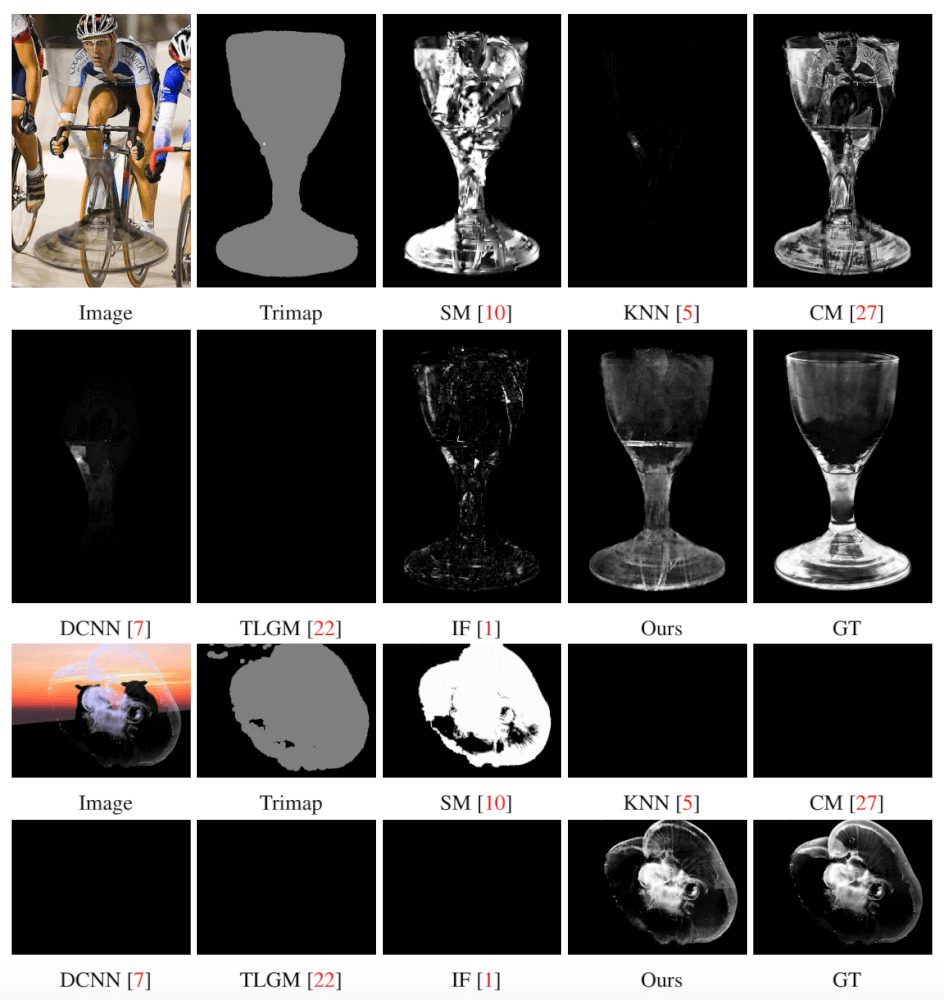
The Alphamatting.com Dataset
The researchers submitted results generated by AlphaGAN to alphamatting.com benchmark and got to the top positions for some of the images:
Specifically, they achieved the best results for Troll and Doll images, and the first place overall on the gradient evaluation metric. Their high results on these particular images demonstrate the advantage of using the adversarial loss from the discriminator to correctly predict the alpha values for such fine structures as hair.
The worst results of the proposed method come from the Net image. However, even though AlphaGAN approach appears low in the rankings for this image, the results still look very close to the top-performing approaches:
![Alpha matting predictions for the "Troll" and "Doll" images (best results) and the "Net" image (worst result) taken from the alphamatting.com dataset. From left to right: DCNN [7], IF [1], DI [33], ‘Ours’](https://neurohive.io/wp-content/uploads/2018/09/1.jpg)

![Alpha matting predictions for the "Troll" and "Doll" images (best results) and the "Net" image (worst result) taken from the alphamatting.com dataset. From left to right: DCNN [7], IF [1], DI [33], ‘Ours’](https://neurohive.io/wp-content/uploads/2018/09/3.jpg)
Bottom Line
AlphaGAN is the first algorithm that uses GANs for natural image matting. Its generator is trained to predict alpha mattes from input images while the discriminator is trained to distinguish good images composited from the ground-truth alpha from images composited with the predicted alpha.
Such network architecture produces visually appealing compositions with state-of-the-art or comparable results for the primary metrics. Exceptional performance is achieved for the images with such fine structures as hair. That is of great importance in practical matting applications, including film and TV production.





