
AViD — это публичный датасет с анонимизированными видеозаписями из разных стран. Датасет предназначен для задачи распознавания действий. AViD состоит из видео, где человек выполняет одно действие. Разнообразие в датасете обеспечивается тем, что видео собирали из разных стран. Основной целью AViD является предоставить возможность обучать универсальные модели распознавания действий, а не специфичные для отдельных стран. Все лица в видеозаписях были анонимизированы для защиты приватности. Данные находятся под лицензией Creative Commons.
Проблема прошлых датасетов
Основным ограничением прошлых датасетов для распознавания действий на видео является то, что в данных есть перекос в сторону видео из отдельных стран. Это снижает обобщающую способность моделей и ограничивает использование таких моделей в реальных продуктах. Обученные на AViD модели лишены этого ограничения.

Подробнее о датасете
Процесс сбора данных состоял из трех шагов:
- Сначала был сформирован список классов действий;
- Затем видео, которые принадлежали к отобранным классам, семплировали из нескольких источников: Flickr, YouTube и других. Это обеспечивает разнообразие видеозаписей. Все лица на видео были распознаны и заблюррены;
- После этого исследователи сгенерировали клипы-кандидаты из каждого видео;
- Эти клипы затем разметили вручную
Всего датасет состоит из видео, которые иллюстрируют 887 действий.
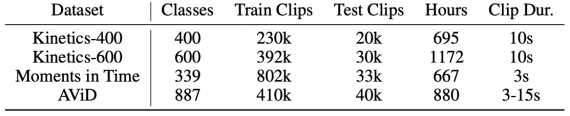
Ниже можно увидеть, что обучение на AViD дает прирост в точности за счет более разнообразных данных.

