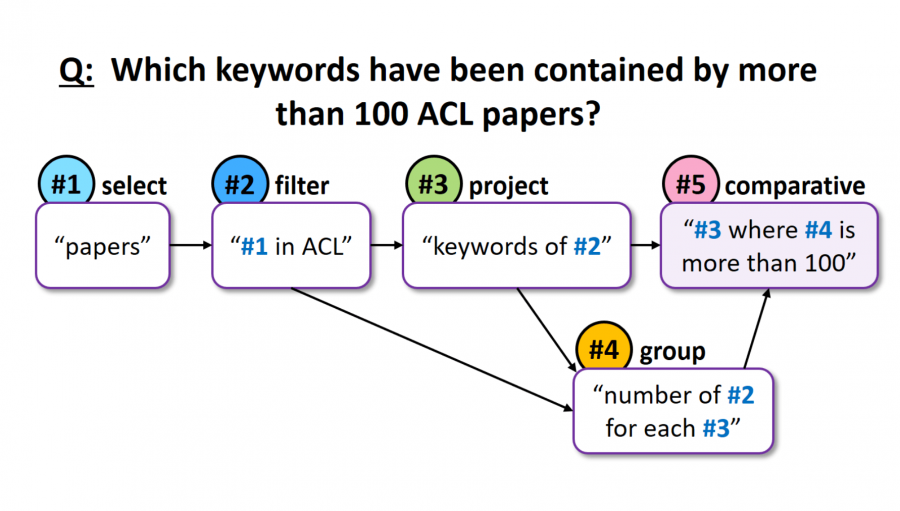
BREAK — это датасет для решения задачи понимания сути вопроса нейросетью. Он предназначен для того, чтобы модели вычленяли из комплексных вопросов сущности, которые помогут при генерации ответов. Датасет состоит из 83,978 вопросов на естественном языке, которые разметили с помощью предложенного представления QDMR. Question Decomposition Meaning Representation (QDMR) каждого вопроса представляет собой лист пунктов на естественном языке, которые необходимы для ответа на вопрос. Вопросы в BREAK собирали из 10 датасетов для задачи question answering. Сбором датасета занимались исследователи из Allen Institute for AI.
Понимание вопросов на естественном языке предполагает возможность разбиения вопроса на пункты, которые необходимы при формулировании ответа. Для этой задачи исследователи предлагают использовать QDMR представления. QDMR представления вопроса — это направленный граф, в котором узел — это пара сущности из вопроса и действия. Из одного узла в другой проводится связь в соответствии с последовательностью совершаемых действий.
Исследователи показали, что использование QDMR улучшает перформанс моделей для задачи open-domain question answering на датасете HOTPOTQA. QDMR можно конвертировать в язык формата псевдоSQL.
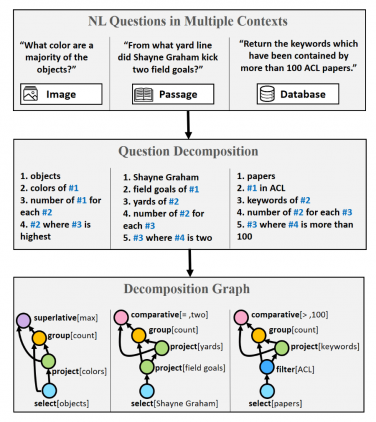
Что такое QDMR представление вопроса
Дизайн Question Decomposition Meaning Representation (QDMR) вдохновлен языками для управлениями баз данных и семантическим парсингом. В QDMR вопрос выражается в подвопросы (операторы), которые необходимо последовательно выполнить, чтобы ответить на вопрос. Каждый QDMR оператор может либо выбирать набор сущностей, извлекать информацию об их атрибутах или агрегировать информацию по сущностям.
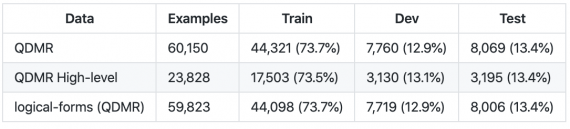
Как устроен датасет
BREAK агрегирует в себе вопросы из 10 датасетов для задач question answering:
- Semantic Parsing: Academic, ATIS, GeoQuery, Spider;
- Visual Question Answering: CLEVR-humans, NLVR2;
- Reading Comprehension (and KB-QA): ComQA, ComplexWebQuestions, DROP, HotpotQA
Исследователи обучили на BREAK нейросетевую модель CopyNet, которая обошла базовые решения.



