Big Transfer — это подход для предобучения представлений изображений. Предобученную модель затем можно использовать для дообучения на собственной задаче. Такой формат обучения называется transfer learning. Использование transfer learning оправдано, в случае если для собственной задачи нет достаточного количества размеченных данных. Использование BiT улучшает качество модели для таких задач, как few-shot распознавание и ObjectNet. Исследователи опубликовали предобученные модели и код для TF2, Jax и PyTorch.
Проблема недостатка размеченных данных
Распространенным ограничением при решении задач в области компьютерного зрения является недостаток размеченных данных. Текущие нейросетевые архитектуры нуждаются в крупным размеченных датасетах. При этом для отдельных задач разметка данных в достаточном объеме чересчур ресурсоемкая.
Чтобы обойти ограничение недостатка размеченных данных, в компьютерном зрении и NLP используют transfer learning. Transfer learning подход заключается в том, что сначала модель предобучается на крупном датасете общей направленности. Затем модель дообучают на своей задаче, для которой недостаточно размеченных данных.
В чем суть подхода
Стратегию предобучения BiT можно разбить на следующие шаги:
- Взять стандартную ResNet;
- Увеличить глубину и ширину нейросети;
- Заменить BatchNorm на GroupNorm и стандартизацию весов (GNWS);
- Обучить модель на крупном общем датасете, увеличив при этом количество итераций

После предобучения модель можно дообучить на интересующей задаче.

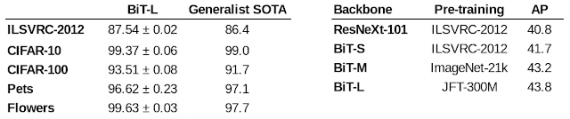
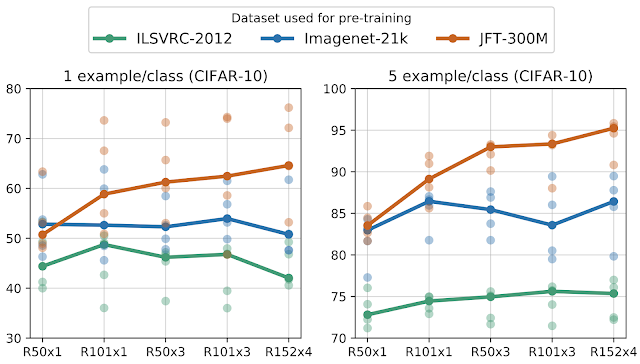
Оценка работы модели
Использование BiT в архитектуре позволяет повысить качество модели.