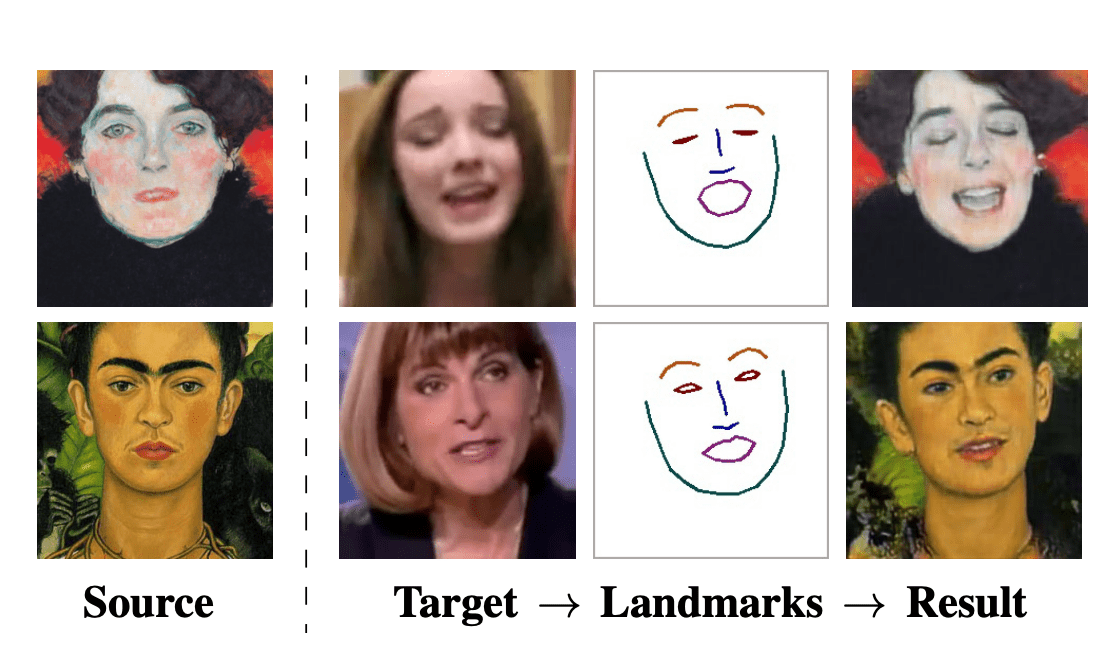
В Samsung AI и Сколково опубликовали работу, в которой нейросеть генерирует видео с человеком на основе одного или двух его статичных изображений. Модель выдает реалистичные результаты и сравнима по метрикам с state-of-the-art решениями.
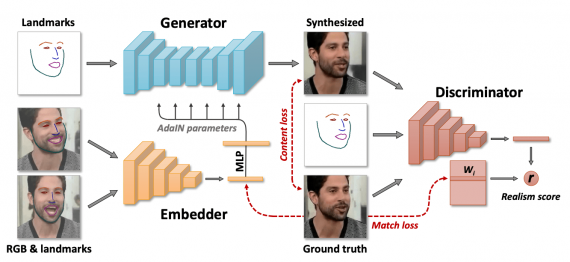
Архитектура нейросети
Meta-learning часть модели включает в себя нейросеть, которая сопоставляет изображения головы (с размеченными точками на разных частях лица) с векторами, которые содержат информацию о характеристиках лица, независимых от расположения лица на изображении. Генератор из входных размеченных точек лица синтезирует через сверточные слои выходные изображения. Целевая функция включает в себя perceptual loss и adversarial loss (реализована через условный дискриминатор проекций).
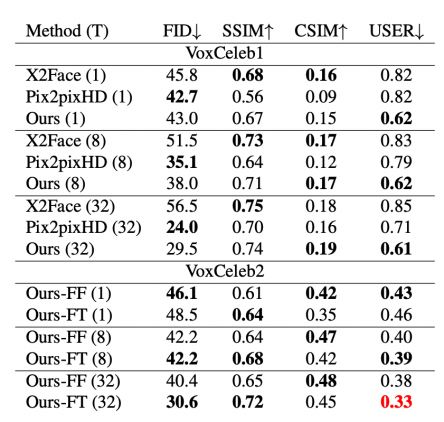
Эксперименты по проверке эффективности модели
В рамках экспериментов исследователи сначала проверили, как предложенная модель сравнима с конкурирующими подходами на данных VoxCeleb1. Затем проверили полные возможности модели на датасете VoxCeleb2. Одной из метрик оценки была оценка реалистичности сгенерированных изображений пользователями (USER на рис. ниже). По этой метрике, наибольший скор у самой полной предложенной модели.
В качестве ограничения модели выделяется неспособность генерации изображений с мимикой. В частности, модель не может генерировать смену взгляда в какую-либо сторону. Кроме этого, есть ограничение в том, как переносится желаемое изображение на входное: можно заметить разницу между человеком на входном изображении и человеком на сгенерированной видеозаписи.

Видеодемонстрация работы нейросети: